ORB with 100 EMAORB Trading Strategy for FX Pairs on the 30-Minute Time Frame
Overview
This Opening Range Breakout (ORB) strategy is designed for trading FX pairs on the 30-minute time frame. The strategy is structured to take advantage of price momentum while aligning trades with the overall trend using the 100-period Exponential Moving Average (100EMA). The primary objective is to enter trades when price breaks and closes above or below the Opening Range (OR), with additional confirmation from a retest of the OR level if the initial entry is missed.
Strategy Rules
1. Defining the Opening Range (OR)
- The OR is determined by the high and low of the first 30-minute candle after market open.
- This range acts as the key level for breakout trading.
2. Trend Confirmation Using the 100EMA
- The 100EMA serves as a filter to determine trade direction:
- Buy Setup: Only take buy trades when the OR is above the 100EMA.
- Sell Setup: Only take sell trades when the OR is below the 100EMA.
3. Entry Criteria
- Buy Trade: Enter a long position when a candle breaks and closes above the OR high, confirming the breakout.
- Sell Trade: Enter a short position when a candle breaks and closes below the OR low, confirming the breakout.
- Retest Entry: If the initial entry is missed, wait for a price retest of the OR level for a secondary entry opportunity.
4. Risk-to-Reward Ratio (R2R)
- The goal is to target a 1:1 Risk-to-Reward (R2R) ratio.
- Stop-loss placement:
- Buy Trade: Place stop-loss just below the OR low.
- Sell Trade: Place stop-loss just above the OR high.
- Take profit at a distance equal to the stop-loss for a 1:1 R2R.
5. Risk Management
- Risk per trade should be based on personal risk tolerance.
- Adjust lot sizes accordingly to maintain a controlled risk percentage of account balance.
- Avoid over-leveraging, and consider moving stop-loss to breakeven if the price moves favourably.
Additional Considerations
- Avoid trading during major news events that may cause high volatility and unpredictable price movements.
- Monitor market conditions to ensure breakout confirmation with strong momentum rather than false breakouts.
- Use additional confluences such as candlestick patterns, support/resistance zones, or volume analysis for stronger trade validation.
This ORB strategy is designed to provide structured trade opportunities by combining breakout momentum with trend confirmation via the 100EMA. The strategy is straightforward, allowing traders to capitalise on clear breakout movements while implementing effective risk management practices. While the 1:1 R2R target provides a balanced approach, traders should always adapt their risk tolerance and market conditions to optimise trade performance.
By following these rules and maintaining discipline, traders can use this strategy effectively across various FX pairs on the 30-minute time frame.
Wskaźniki i strategie

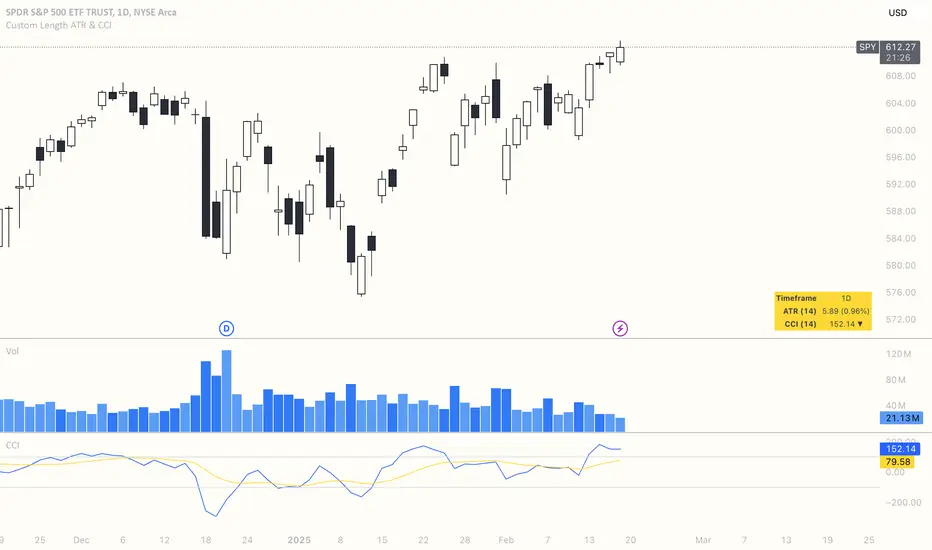
Industry Indices ComparisonA dynamic industry sector performance comparison indicator that helps traders and investors track relative strength across different market sectors in real-time.
- Compares up to 5 industry sector ETFs against a benchmark index (default: SPY)
- Displays key metrics including:
* Performance % over selected timeframe
* Relative performance vs benchmark
* Trend direction (▲ up, ▼ down, − neutral)
* Volume in millions (M) of shares traded
- Configurable timeframes: 1D, 1W, 1M, and 3M comparisons
- Color-coded performance indicators (green for outperformance, red for underperformance)
- Customizable table position and text size for optimal chart placement
The indicator helps identify:
1. Sector rotation patterns through relative performance
2. Leading and lagging sectors vs the broader market
3. Volume trends across different sectors
For traders, if you are considering two equally good setups, then choosing the setup belonging to a currently strong sector could be beneficial.
The Commitment of Traders (COT) IndexThe COT Index indicator is used to measure the positioning of different market participants (Large Traders, Small Traders, and Commercial Hedgers) relative to their historical positioning over a specified lookback period. It helps traders identify extreme positioning, which can signal potential reversals or trend continuations.
Key Features of the Indicator:
COT Data Retrieval
The script pulls COT report data from the TradingView COT Library TradingView/LibraryCOT/3).
It retrieves long and short positions for three key groups:
Large Traders (Non-commercial positions) – Speculators such as hedge funds.
Small Traders (Non-reportable positions) – Small retail traders.
Commercial Hedgers (Commercial positions) – Institutions that hedge real-world positions.
Threshold Zones for Extreme Positioning:
Upper Zone Threshold (Default: 90%)
Signals potential overbought conditions (excessive buying).
Lower Zone Threshold (Default: 10%)
Signals potential oversold conditions (excessive selling).
The indicator plots these zones using horizontal lines.
The COT Index should be used in conjunction with technical analysis (support/resistance, trends, etc.). A high COT Index does not mean the market will reverse immediately—it’s an indication of extreme sentiment.
Note:
If the script does not recognize or can't find the ticker currently viewed in the COT report, the COT indicator will default to U.S. Dollar.

Fixed Range LevelsThis indicator draws horizontal price levels on your chart based on a starting price and a range size that you define. It can also draw midpoint lines between the main levels if enabled.
Here's a breakdown of its functionality:
Key Features:
Starting Price:
You define a starting price (e.g., 21630).
The indicator calculates a corrected base price by rounding the starting price to the nearest multiple of the range size.
Range Size:
You define a range size (e.g., 71).
The indicator draws horizontal lines at intervals of the range size above and below the corrected base price.
Dual Ranges:
You can define two range sizes (e.g., 71 and 29).
The indicator can draw levels for both ranges simultaneously or individually, depending on your settings.
Midpoint Lines:
If enabled, the indicator draws midpoint lines between the main levels.
For example, if the main levels are at 21584 and 21655, the midpoint line will be at 21619.5.
Customizable Styles:
You can customize the line style (solid, dotted, dashed) and color for both the main levels and midpoint lines.
Dynamic Levels:
The levels are recalculated and redrawn dynamically based on the starting price and range size.
How It Works:
Corrected Base Price Calculation:
The indicator calculates the corrected base price using the formula:
pinescript
Copy
correctedBasePrice = math.floor(startingPrice / rangeSize) * rangeSize
For example, if startingPrice = 21630 and rangeSize = 71:
Copy
correctedBasePrice = math.floor(21630 / 71) * 71 = 304 * 71 = 21584
Drawing Levels:
The indicator draws horizontal lines at intervals of the range size above and below the corrected base price.
For example, if rangeSize = 71 and maxLevels = 5, the levels will be drawn at:
Copy
21584 - (5 * 71) = 21249
21584 - (4 * 71) = 21320
...
21584 + (5 * 71) = 21939
Midpoint Lines:
If enabled, the indicator draws midpoint lines between the main levels.
For example, if the main levels are at 21584 and 21655, the midpoint line will be at:
Copy
(21584 + 21655) / 2 = 21619.5
Dual Ranges:
If you enable both ranges, the indicator will draw levels for both range sizes simultaneously.
For example, if rangeSize1 = 71 and rangeSize2 = 29, the indicator will draw two sets of levels:
Levels at intervals of 71 (e.g., 21584, 21655, 21726, ...).
Levels at intervals of 29 (e.g., 21634, 21663, 21692, ...).
Example Use Case:
Imagine you're trading a stock or cryptocurrency, and you want to identify key support and resistance levels based on a specific price range. Here's how you can use this indicator:
Set the Starting Price:
For example, if the current price is 21630, you can set this as the starting price.
Define the Range Size:
If you believe the price moves in increments of 71, set rangeSize1 = 71.
If you also want to track smaller increments of 29, set rangeSize2 = 29.
Enable Midpoint Lines:
If you want to see the midpoint between the main levels, enable Show Midpoint Line.
Customize Line Styles:
Choose different colors and styles for the main levels and midpoint lines to make them visually distinct.
Analyze the Chart:
The indicator will draw horizontal lines at the specified intervals, helping you identify potential support, resistance, and midpoint levels.
Why Is This Useful?
Support and Resistance Levels:
The horizontal lines act as dynamic support and resistance levels based on the range size you define.
Price Targets:
You can use the levels to identify potential price targets or areas where the price might reverse.
Midpoint Analysis:
The midpoint lines can help you identify areas of consolidation or potential breakout points.
Flexibility:
You can customize the range sizes, colors, and styles to suit your trading strategy.
Summary:
This indicator is a powerful tool for traders who want to visualize price levels and midpoints based on a specific range size. It helps you identify key levels for support, resistance, and potential price targets, making it easier to plan your trades.

Shifted Buy PressureDifferentiated Buy Pressure Indicator Documentation
Overview: The Differentiated Buy Pressure indicator is a custom Pine Script™ indicator designed to measure and visualize buy and sell pressure in the market. It calculates buy pressure based on a combination of volume, range, and gap, and provides a differentiated buy pressure which is shifted by 90°, offering predictive insights.
Inputs:
Window Size: The window size for average calculation (default: 20).
Show Overlay: Option to show the price overlay (default: false).
Overlay Boost Factor: Boosting factor for overlaying the price (default: 0.01).
Calculations:
Relative Range: Calculated as (high - low) / close.
Average Range: Simple moving average of the relative range over the specified window.
Average Volume: Simple moving average of the volume over the specified window.
Relative Gap: Calculated as open / close .
Average Gap: Simple moving average of the relative gap over the specified window.
Buy Pressure: Calculated using the formula: buy_pressure = -math.log(relative_range / avg_range * volume / avg_volume * relative_gap / avg_gap)
Differentiated Buy Pressure: Calculated as the difference between the current and previous buy pressure: diff_buy_pressure = buy_pressure - buy_pressure
Plots:
Zero Line: A horizontal line at zero for reference.
Buy Pressure: Plotted in blue, representing the calculated buy pressure.
Differentiated Buy Pressure: Plotted in red, representing the differentiated buy pressure.
Overlay: Optionally plots the price overlay boosted by the differentiated buy pressure.
Labels:
Labels are created to display the buy pressure and differentiated buy pressure values on the chart.
Usage: This indicator helps traders visualize the buy and sell pressure in the market. Positive values indicate buy pressure, while negative values indicate sell pressure. The differentiated buy pressure, shifted by 90°, provides predictive insights into future market movements.
This documentation provides a comprehensive overview of the Differentiated Buy Pressure indicator, explaining its purpose, inputs, calculations, and usage.
KAI QUANTUM Candles Analysis - Yearly BreakdownThe "KAI QUANTUM Analysis – Yearly Breakdown" indicator offers a comprehensive, year-by-year examination of candlestick behavior, enabling traders and analysts to gauge market dynamics over extended periods. Key features include:
Yearly Aggregation:
The indicator groups candlestick data by year, providing a clear snapshot of market behavior for each period.
Dual-Color Analysis:
It categorizes candles as bullish (green) or bearish (red) and computes statistics separately for each, allowing you to assess both upward and downward market trends.
Average Body Size & Candle Count:
For each year, the indicator calculates the average body size of green and red candles and tracks the total number of each, helping you understand overall market volatility and momentum.
Top 10 Candle Analysis:
It identifies the ten largest candles (by body size) in each year and computes their average size, offering insight into the most significant market moves during that period.
Largest Candle Metrics:
The indicator determines the absolute size of the largest green and red candles in each year.
Percentage Move Calculation:
In addition to absolute values, it computes the largest move as a percentage of the open price for both green and red candles. This allows you to see not only which year experienced the biggest moves but also how those moves compare relative to the opening price.
Clear Tabular Display:
All the computed statistics are organized in an on-chart table, making it easy to compare yearly trends at a glance.
Ideal for daily and higher timeframes, this indicator is a valuable tool for long-term market analysis, enabling you to identify trends, assess volatility, and make informed trading decisions based on historical market behavior.

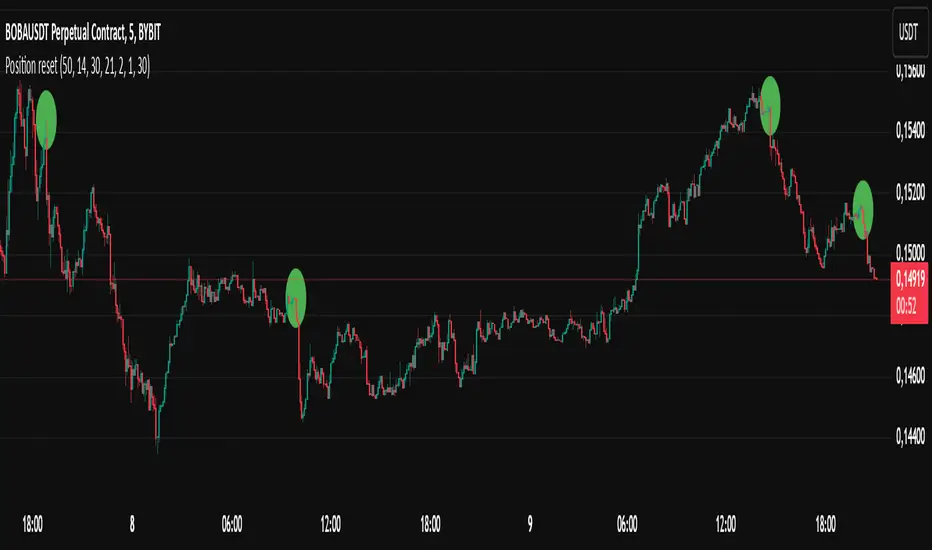
Position resetThe "Position Reset" indicator
The Position Reset indicator is a sophisticated technical analysis tool designed to identify possible entry points into short positions based on an analysis of market volatility and the behavior of various groups of bidders. The main purpose of this indicator is to provide traders with information about the current state of the market and help them decide whether to open short positions depending on the level of volatility and the mood of the main players.
The main components of the indicator:
1. Parameters for the RSI (Relative Strength Index):
The indicator uses two sets of parameters to calculate the RSI: one for bankers ("Banker"), the other for hot money ("Hot Money").
RSI for Bankers:
RSIBaseBanker: The baseline for calculating bankers' RSI. The default value is 50.
RSIPeriodBanker: The period for calculating the RSI for bankers. The default period is 14.
RSI for hot money:
RSIBaseHotMoney: The baseline for calculating the RSI of hot money. The default value is 30.
RSIPeriodHotMoney: The period for calculating the RSI for hot money. The default period is 21.
These parameters allow you to adjust the sensitivity of the indicator to the actions of different groups of market participants.
2. Sensitivity:
Sensitivity determines how strongly changes in the RSI will affect the final result of calculations. It is configured separately for bankers and hot money:
SensitivityBanker: Sensitivity for bankers' RSI. It is set to 2.0 by default.
SensitivityHotMoney: Sensitivity for hot money RSI. It is set to 1.0 by default.
Changing these parameters allows you to adapt the indicator to different market conditions and trader preferences.
3. Volatility Analysis:
Volatility is measured based on the length of the period, which is set by the volLength parameter. The default length is 30 candles. The indicator calculates the difference between the highest and lowest value for the specified period and divides this difference by the lowest value, thus obtaining the volatility coefficient.
Based on this coefficient, four levels of volatility are distinguished.:
Extreme volatility: The coefficient is greater than or equal to 0.25.
High volatility: The coefficient ranges from 0.125 to 0.2499.
Normal volatility: The coefficient ranges from 0.05 to 0.1249.
Low volatility: The coefficient is less than 0.0499.
Each level of volatility has its own significance for making decisions about entering a position.
4. Calculation functions:
The indicator uses several functions to process the RSI and volatility data.:
rsi_function: This function applies to every type of RSI (bankers and hot money). It adjusts the RSI value according to the set sensitivity and baseline, limiting the range of values from 0 to 20.
Moving Averages: Simple moving averages (SMA), exponential moving averages (EMA), and weighted moving averages (RMA) are used to smooth fluctuations. They are applied to different time intervals to obtain the average values of the RSI.
Thus, the indicator creates a comprehensive picture of market behavior, taking into account both short-term and long-term dynamics.
5. Bearish signals:
Bearish signals are considered situations when the RSI crosses certain levels simultaneously with a drop in indicators for both types of market participants (bankers and hot money).:
The bankers' RSI crossing is below the level of 8.5.
The current hot money RSI is less than 18.
The moving averages for banks and hot money are below their signal lines.
The RSI values for bankers are less than 5.
These conditions indicate a possible beginning of a downtrend.
6. Signal generation:
Depending on the current level of volatility and the presence of bearish signals, the indicator generates three types of signals:
Orange circle: Extremely high volatility and the presence of a bearish signal.
Yellow circle: High volatility and the presence of a bearish signal.
Green circle: Low volatility and the presence of a bearish signal.
These visual markers help the trader to quickly understand what level of risk accompanies each specific signal.
7. Notifications:
The indicator supports the function of sending notifications when one of the three types of signals occurs. The notification contains a brief description of the conditions under which the signal was generated, which allows the trader to respond promptly to a change in the market situation.
Advantages of using the "Position Reset" indicator:
Multi-level analysis: The indicator combines technical analysis (RSI) and volatility assessment, providing a comprehensive view of the current market situation.
Flexibility of settings: The ability to adjust the sensitivity parameters and the RSI baselines allows you to adapt the indicator to any market conditions and personal preferences of the trader.
Clear visualization: The use of colored labels on the chart simplifies the perception of information and helps to quickly identify key points for entering a trade.
Notification support: The notification sending feature makes it much easier to monitor the market, allowing you to respond to important events in time.
KEMAD | QuantumResearchQuantumResearch KEMAD Indicator
The QuantumResearch KEMAD Indicator is a sophisticated trend-following and volatility-based tool designed for traders who demand precision in detecting market trends and price reversals. By leveraging advanced techniques implemented in PineScript, this indicator integrates a Kalman filter, an Exponential Moving Average (EMA), and dynamic ATR-based deviation bands to produce clear, actionable trading signals.
1. Overview
The KEMAD Indicator aims to:
Reduce Market Noise: Employ a Kalman filter to smooth price data.
Identify Trends: Use an EMA of the filtered price to define the prevailing market direction.
Set Dynamic Thresholds: Adjust breakout levels with ATR-based deviation bands.
Generate Signals: Provide clear long and short trading signals along with intuitive visual cues.
2. How It Works
A. Kalman Filter Smoothing
Purpose: The Kalman filter refines the selected price source (e.g., close price) by reducing short-term fluctuations, thus offering a clearer view of the underlying price movement.
Customization: Users can adjust key parameters such as:
Process Noise: Controls the filter’s sensitivity to recent changes.
Measurement Noise: Determines how responsive the filter is to incoming price data.
Filter Order: Sets the number of data points considered in the smoothing process.
B. EMA-Based Trend Detection
Primary Trend EMA: A 25-period EMA is applied to the Kalman-filtered price, serving as the core trend indicator.
Signal Mechanism:
Long Signal: Triggered when the price exceeds the EMA plus an ATR-based upper deviation.
Short Signal: Triggered when the price falls below the EMA minus an ATR-based lower deviation.
C. ATR Deviation Bands
ATR Utilization: The Average True Range (ATR) is computed (default length of 21) to assess market volatility.
Dynamic Thresholds:
Upper Deviation: Calculated by adding 1.5× ATR to the EMA (for long signals).
Lower Deviation: Calculated by subtracting 1.1× ATR from the EMA (for short signals).
These bands adapt to current volatility, ensuring that signal thresholds are both dynamic and market-sensitive.
3. Visual Representation
The indicator’s design emphasizes clarity and ease of use:
Color-Coded Bar Signals:
Green Bars: Indicate bullish conditions when a long signal is active.
Red Bars: Indicate bearish conditions when a short signal is active.
Trend Confirmation Line: A 54-period EMA is plotted to further validate trend direction. Its color dynamically changes to reflect the active trend.
Background Fill: The space between a calculated price midpoint (typically the average of high and low) and the EMA is filled, visually emphasizing the prevailing market trend.
4. Customization & Parameters
The KEMAD Indicator is highly configurable, allowing traders to tailor the tool to their specific trading strategies and market conditions:
ATR Settings:
ATR Length: Default is 21; adjusts sensitivity to market volatility.
EMA Settings:
Trend EMA Length: Default is 25; smooths price action for trend detection.
Confirmation EMA Length: Default is 54; aids in confirming the trend.
Kalman Filter Parameters:
Process Noise: Default is 0.01.
Measurement Noise: Default is 3.0.
Filter Order: Default is 5.
Deviation Multipliers:
Long Signal Multiplier: Default is 1.5× ATR.
Short Signal Multiplier: Default is 1.1× ATR.
Appearance: Eight customizable color themes are available to suit individual visual preferences.
5. Trading Applications
The versatility of the KEMAD Indicator makes it suitable for various trading strategies:
Trend Following: It helps identify and ride sustained bullish or bearish trends by filtering out market noise.
Breakout Trading: Detects when prices move beyond the ATR-based deviation bands, signaling potential breakout opportunities.
Reversal Detection: Alerts traders to potential trend reversals when price crosses the dynamically smoothed EMA.
Risk Management: Offers clearly defined entry and exit points, based on volatility-adjusted thresholds, enhancing trade precision and risk control.
6. Final Thoughts
The QuantumResearch KEMAD Indicator represents a unique blend of advanced filtering (via the Kalman filter), robust trend analysis (using EMAs), and dynamic volatility assessment (through ATR deviation bands).
Its PineScript implementation allows for a high degree of customization, making it an invaluable tool for traders looking to reduce noise, accurately detect trends, and manage risk effectively.
Whether used for trend following, breakout strategies, or reversal detection, the KEMAD Indicator is designed to adapt to varying market conditions and trading styles.
Important Disclaimer: Past data does not predict future behavior. This indicator is provided for informational purposes only; no indicator or strategy can guarantee future results. Always perform thorough analysis and use proper risk management before trading.

Volatility Arbitrage Spread Oscillator Model (VASOM)The Volatility Arbitrage Spread Oscillator Model (VASOM) is a systematic approach to capitalizing on price inefficiencies in the VIX futures term structure. By analyzing the differential between front-month and second-month VIX futures contracts, we employ a momentum-based oscillator (Relative Strength Index, RSI) to signal potential market reversion opportunities. Our research builds upon existing financial literature on volatility risk premia and contango/backwardation dynamics in the volatility markets (Zhang & Zhu, 2006; Alexander & Korovilas, 2012).
Volatility derivatives have become essential tools for managing risk and engaging in speculative trades (Whaley, 2009). The Chicago Board Options Exchange (CBOE) Volatility Index (VIX) measures the market’s expectation of 30-day forward-looking volatility derived from S&P 500 option prices (CBOE, 2018). Term structures in VIX futures often exhibit contango or backwardation, depending on macroeconomic and market conditions (Alexander & Korovilas, 2012).
This strategy seeks to exploit the spread between the front-month and second-month VIX futures as a proxy for term structure dynamics. The spread’s momentum, quantified by the RSI, serves as a signal for entry and exit points, aligning with empirical findings on mean reversion in volatility markets (Zhang & Zhu, 2006).
• Entry Signal: When RSI_t falls below the user-defined threshold (e.g., 30), indicating a potential undervaluation in the spread.
• Exit Signal: When RSI_t exceeds a threshold (e.g., 70), suggesting mean reversion has occurred.
Empirical Justification
The strategy aligns with findings that suggest predictable patterns in volatility futures spreads (Alexander & Korovilas, 2012). Furthermore, the use of RSI leverages insights from momentum-based trading models, which have demonstrated efficacy in various asset classes, including commodities and derivatives (Jegadeesh & Titman, 1993).
References
• Alexander, C., & Korovilas, D. (2012). The Hazards of Volatility Investing. Journal of Alternative Investments, 15(2), 92-104.
• CBOE. (2018). The VIX White Paper. Chicago Board Options Exchange.
• Jegadeesh, N., & Titman, S. (1993). Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency. The Journal of Finance, 48(1), 65-91.
• Zhang, C., & Zhu, Y. (2006). Exploiting Predictability in Volatility Futures Spreads. Financial Analysts Journal, 62(6), 62-72.
• Whaley, R. E. (2009). Understanding the VIX. The Journal of Portfolio Management, 35(3), 98-105.

Candle Range TheoryCandle Range Analysis:
Calculates the true range of each candle
Shows a 14-period SMA of the range (adjustable)
Dynamic bands based on standard deviation
Visual Components:
Colored histogram showing range deviations from mean
Signal line for oscillator smoothing
Expansion/contraction zones marked with dotted lines
Arrow markers for extreme range conditions
Key Functionality:
Identifies range expansion/contraction relative to historical volatility
Shows normalized range oscillator (-100% to +100% scale)
Includes visual and audio alerts for extreme range conditions
Customizable parameters for sensitivity and smoothing
Interpretation:
Red zones indicate above-average volatility/expansion
Green zones indicate below-average volatility/contraction
Crossings above/below zero line show range expansion/contraction
Signal line crossover system potential

End-of-Session ProbabilityThis indicator estimates the probability that the market will finish the session above a specified target price. It blends a statistical probability model with directional bias and optional morning momentum weighting to help traders gauge end-of-day market expectations.
Key Features:
• Statistical Probability Model:
Uses a normal distribution (with a custom normal CDF approximation) scaled by the square-root-of-time rule. The indicator dynamically adjusts the standard deviation for the remaining session time to compute a z‑score and ultimately the probability that the session close exceeds the target.
• Directional Bias via Daily HullMA (Exponential):
A daily Hull Moving Average (calculated using an exponential method) is used as a big-picture trend indicator. The model allows you to select your bias method—either by comparing the current price to the daily HullMA (Price method) or by using the HullMA’s slope (Slope method). A drift multiplier scales this bias, which then shifts the mean used in the probability calculations.
• Optional Morning Momentum Weight:
For traders who believe that early session moves provide useful clues about the day’s momentum, you can enable an optional weighting. The indicator captures the percentage change from the morning open (within a user-defined time window) and adjusts the expected move accordingly. A multiplier lets you control the strength of this adjustment.
• Visual Outputs:
The indicator plots quantile lines (approximately the 25%, 50%, and 75% levels) for the expected price distribution at session end. An abbreviated on-chart label displays key information:
• Target: The target price (current price plus a user-defined offset)
• Prob Above: The probability (in percentage) that the session close will exceed the target price
• Time: The time remaining in the session (in minutes)
How to Use:
1. Set Your Parameters:
• Expected Session Move: Input your estimated standard deviation for the full-session move in price units.
• Daily Hull MA Settings: Adjust the period for the daily HullMA and choose the bias method (Price or Slope). Modify the drift multiplier to tune the strength of the directional bias.
• Target Offset: Specify an offset from the current price to set your target level.
• Morning Momentum (Optional): Enable the morning momentum weight if you want the indicator to adjust the expected move based on early session price changes. Define the morning session window and set the momentum multiplier.
2. Interpret the Output:
• Quantile Lines: These represent the range of possible end-of-session prices based on your model.
• Abbreviated Label: Provides a quick snapshot of the target price, probability of finishing above that target, and time remaining in the session.
3. Trading Application:
Use the probability output as a guide to assess if the market is likely to continue in the current direction or reverse by session close. The indicator can help you decide on trade entries, exits, or adjustments based on your overall strategy and risk management approach.
This tool is designed to offer a dynamic, statistically driven snapshot of the market’s expected end-of-day behavior, combining both longer-term trend bias and short-term momentum cues.

Bitcoin Liquidity Breakout with ICT StrategiesBitcoin Liquidity Breakout with ICT Strategies
a one of many scripts developed by our engineers .
Check the results for yourself
Market Sentiment - Historic Movement & Pending Orders The "Market Sentiment Osc" is a custom trading indicator designed to assess market sentiment based on bid-ask and tick-based data. This oscillator aggregates data from two key sources:
It measures the balance between market upticks, market downticks, cumulative bids and cumulative asks. By doing this we are attempting to guage sentiment by combining the actions that have happened in the past as well as the pending actions the market is willing to make.
The indicator combines these two components to form a composite oscillator that highlights shifts in market sentiment. When the composite value is positive, it suggests a bullish trend, while a negative value indicates bearish sentiment.
The Hoodie Market Trend is plotted as a histogram, with color coding:
Green: Bullish momentum (positive values).
Red: Bearish momentum (negative values).
Additionally, the user can toggle the histogram visibility with the provided input option.
This oscillator can be applied across various timeframes and stock symbols without allowing for symbol customization, making it a simple yet effective tool for market trend analysis. The zero line (purple) serves as a reference point to gauge whether the market is in a bullish or bearish phase.
OmniPulse (Fixed Version)OmniPulse (Fixed Version) – Description
OmniPulse is a multi-indicator framework designed to combine three core oscillators—RSI, Stochastic, and Momentum—at various lookback lengths, then refine their signals using placeholder features such as machine learning forecasting, adaptive cycle detection, and neural network filtering. While some of these advanced features are not natively supported in Pine Script, they are represented here in simplified forms to illustrate how a more sophisticated system could be structured.
Key Components:
Multi-Length Oscillator Arrays
RSI (calcrsi() function)
Stochastic (placeholder via ta.sma() on a typical price average)
Momentum (ta.roc())
These are calculated for multiple lengths defined by the rsiLengths, stochLengths, and momentumLengths arrays.
Dual-Threshold Convergence
Compares each oscillator’s value to user-defined upper/lower thresholds (threshold1, threshold2) to identify bullish or bearish conditions.
Summarizes results in a convergence score.
Placeholder Machine Learning Forecast
Demonstrates a simple averaging of oscillator values as a “forecast” when toggled on.
Adaptive Cycle Detection (Placeholder)
Introduces a static cycle period (e.g., 20.0) as a placeholder for more advanced transforms.
Neural Network Filter (Placeholder)
Averages convergence, forecast, and cyclePeriod into a single filteredSignal.
Signal Plotting
Plots the filtered signal on the chart.
Highlights potential bullish or bearish extremes with shape markers based on percentile thresholds.
Practical Use & Extension:
Real Multi-Timeframe Analysis: Replace placeholders with request.security() for each timeframe.
Advanced Forecasting: Incorporate custom or external machine learning models.
Genuine Cycle Detection: Implement more sophisticated logic or user-defined cycle detection tools.
Neural Network Heuristics: Expand the placeholder step into a deeper filtering or weighting system.
Overall, OmniPulse serves as an adaptable blueprint for traders and developers, showcasing how multiple indicators and advanced concepts might be combined into a cohesive, signal-generating framework.
Buyable Gap Ups (BGU) ScreenerBuyable Gap Ups (BGU) Screener
This custom indicator detects Buyable Gap Ups (BGU), designed to identify stocks with significant price movements driven by gap-ups, often signaling strong bullish momentum. It helps traders spot potential opportunities where a stock has gapped up above the previous day's high with increased volume, suggesting the possibility of continued price strength.
Key Features:
Gap Percentage Threshold: Set a minimum gap percentage required for a valid buyable gap-up.
Volume Change Threshold: Identifies gap-ups accompanied by a significant increase in volume compared to the 50-day average.
ATR-Based Gap Detection (Optional): Use Average True Range (ATR) to determine whether the gap is large enough, factoring in recent volatility.
Customizable Lookback Period: Adjust the number of recent bars to track the frequency of BGU occurrences.
Volume Confirmation: Only signals buyable gaps when volume surpasses a defined threshold above the 50-day average.
Input Parameters:
Gap Percentage Threshold: Adjusts the minimum percentage gap for a valid signal.
Volume Change Threshold: Determines the minimum percentage increase in volume compared to the 50-day moving average.
Use ATR Gap: Option to use ATR to determine the minimum gap size instead of the percentage gap.
ATR Multiplier for Gap: Customizes the gap size based on the ATR.
ATR Length: Adjusts the lookback period for calculating ATR.
Lookback Period for BGU: Set the number of bars over which to calculate the BGU count.
Alerts & Signals:
The script will plot signals below bars where a valid BGU condition is met.
Alerts can be set for when a BGU is detected, giving real-time notifications for potential trading opportunities.
This indicator is designed to help traders find stocks showing strong bullish momentum, especially after earnings or other market-moving events, with the potential for continued uptrend. It is ideal for those looking to incorporate gap-based strategies in their trading.

Fixed Gap Price LevelsIndicator Description:
The Fixed Gap Price Levels indicator draws horizontal price levels at user-defined intervals on the chart.
Users can select a starting price level (e.g., 71 or 2.1).
Lines are drawn at fixed gaps (e.g., if 71 is chosen, lines appear at 71, 142, 213, etc.).
An optional midpoint line can be enabled to appear halfway between the main levels.
Customizable colors for both main and midpoint lines.
Lines extend across the entire screen for easy visualization of price levels.
This tool helps traders quickly identify key price levels based on predefined spacing, aiding in technical analysis.
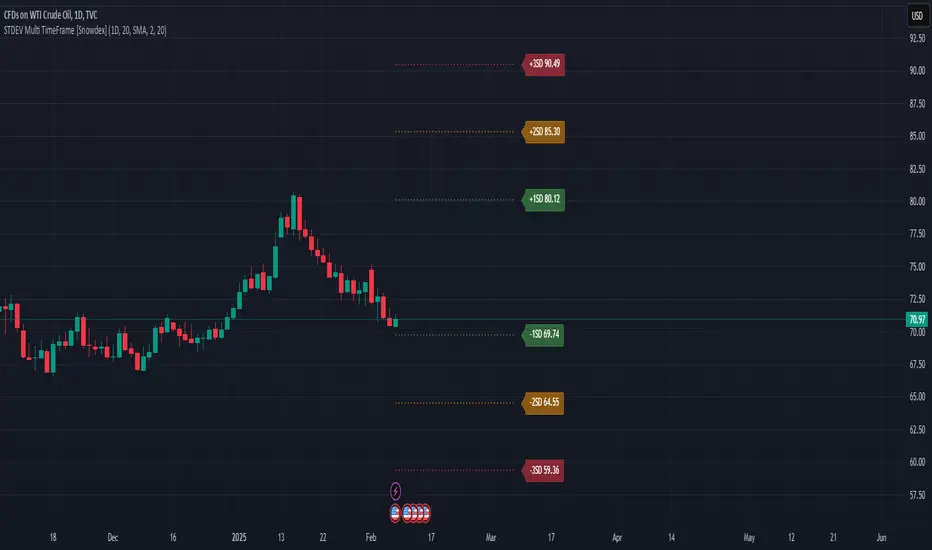
STDEV Multi TimeFrame [Snowdex]STDEV Multi TimeFrame
The STDEV Multi TimeFrame indicator plots standard deviation levels (+1SD, +2SD, +3SD, -1SD, -2SD, -3SD) based on a user-selected timeframe (1D, 1W, 1M, etc.). It helps identify volatility, trend strength, and potential reversal zones using Bollinger Bands-style deviation calculations.
Key Features:
✅ Multi-Timeframe Selection – Choose any timeframe for STDEV calculations.
✅ Customizable Bollinger Bands – Select SMA, EMA, RMA, or WMA as the baseline.
✅ Color-Coded STDEV Levels – Fast (Green), Medium (Orange), Slow (Red).
✅ Non-Repainting & Accurate – Uses request.security() for precise data retrieval.
✅ Extended Lines & Labels – Clear trend monitoring with formatted values.
Use Cases:
📌 Detect trend direction & volatility.
📌 Identify overbought/oversold zones.
📌 Use as dynamic support/resistance levels.
🚀 Ideal for stocks, forex, crypto, and options trading! 🚀
Price Level Multi Timeframe [Snowdex]Price Level Multi-Timeframe Indicator
This indicator visualizes important price levels from multiple timeframes (e.g., daily, weekly, monthly) directly on the chart. It helps traders identify significant support and resistance levels for better decision-making.
Features:
Displays price levels for multiple timeframes: daily (1D), weekly (1W), monthly (1M), quarterly (3M), semi-annual (6M), and yearly (12M).
Customizable options to show or hide levels and adjust their colors.
Highlights high, low, and close levels of each timeframe with labels and dotted lines.
Includes options to extend levels visually for better clarity.
Benefits:
Easily compare price levels across timeframes.
Enhance technical analysis with multi-timeframe insights.
Identify key areas of support and resistance dynamically.

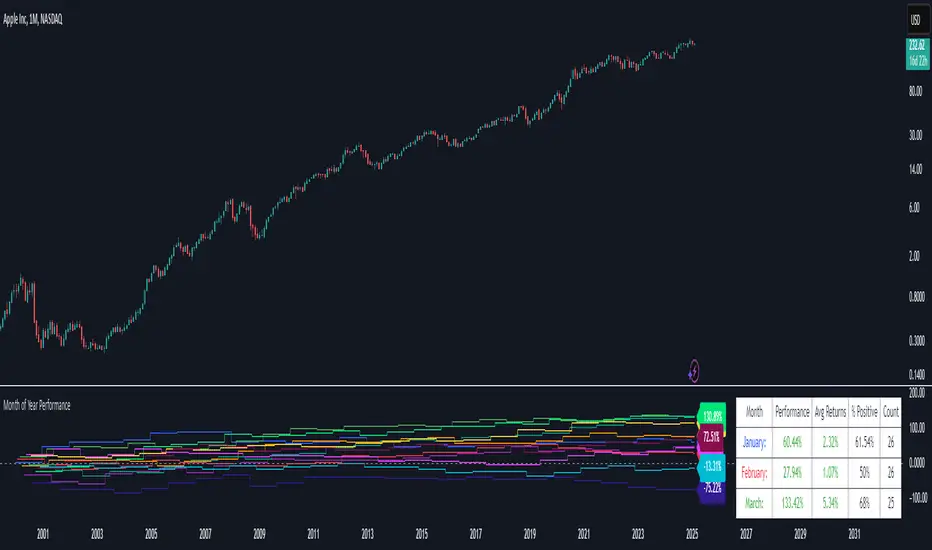
Month of Year Performance█ OVERVIEW
The Month of Year Performance indicator is designed to visualize and compare the cumulative percentage change for each month of the year. By aggregating monthly returns, it helps uncover seasonal trends and potential anomalies in financial markets.
In financial analysis, a calendar based anomaly refers to recurring patterns or tendencies associated with specific time periods, such as days of the week. By calculating the cumulative percentage change for each month (January through December) and displaying the results both graphically and in a summary table, this indicator helps identify whether certain months
consistently outperform others.
█ FEATURES
Customisable time window via Time Settings.
Calculates cumulative percentage change for each month (January to December) separately.
Built-in error check to ensure the indicator is applied on a Monthly timeframe.
Distinct visual representation for each month using unique colours.
Customisable table settings including location and font size.
Displays a performance summary table with metrics such as performance, average return, % positive, and count.
█ HOW TO USE
Add the indicator to a chart set to a Monthly timeframe.
Select your desired Start Time and End Time in the Time Settings.
Toggle the performance table on or off in the Table Settings.
Adjust the table’s location and font size as needed.
View the cumulative monthly performance plotted in distinct colours.
Colour Scheme:
January: Blue
February: Red
March: Green
April: Orange
May: Purple
June: Fuchsia
July: Teal
August: Yellow
September: Navy
October: Lime
November: Maroon
December: Aqua
Schwarzman Custom ORB with Box DisplayIndicator Overview
The Schwarzman Custom ORB (Opening Range Breakout) Indicator is a fully self-developed script designed for traders who utilize opening range breakout strategies. This indicator allows users to customize their ORB settings, apply them to historical price data, and visually connect multiple ORBs to analyze past performance. The goal is to provide traders with a tool to backtest and refine their breakout strategies based on historical ORB data.
How the Indicator Works
1️⃣ User-Defined ORB Settings
• The user selects a custom start time (hour and minute) for the ORB.
• The user defines a duration (e.g., 15 minutes, 30 minutes, etc.) for the ORB period.
• A timezone offset is included to adjust for different market sessions.
2️⃣ ORB High and Low Calculation
• The script records the highest and lowest prices within the selected ORB time window.
• The recorded values remain static after the ORB period ends, ensuring accurate range plotting.
3️⃣ Historical ORB Visualization
• Instead of only showing a single ORB for the current session, this indicator connects multiple ORBs across past data.
• This allows traders to visually analyze previous breakout performance.
• The plotted ORBs remain fixed and do not repaint, ensuring an accurate backtesting experience.
4️⃣ Stepline Visualization & Range Filling
• The high and low ORB levels are displayed using stepline plots to maintain clear horizontal levels.
• A shaded box is applied between the ORB high and low for better visualization.
Use Cases & Strategy Application
📌 Backtesting Historical ORBs – See how past ORBs performed under different market conditions.
📌 Custom ORB Settings – Adjust the start time and duration for different trading sessions.
📌 Multi-ORB Analysis – Connect ORBs over multiple trading days to study trends and breakouts.
📌 Breakout Strategy Optimization – Use the historical ORB connections to refine entry and exit points.
This indicator is particularly useful for day traders, scalpers, and breakout traders looking for a data-driven approach to trading.
Indicator Development & Transparency Statement
As a trader, I have tested various ORB (Opening Range Breakout) indicators available in the TradingView community. Through these experiences, I aimed to develop a version that best fits my own trading needs and strategy.
This script is a self-developed ORB tool, created from scratch while drawing inspiration from the concept of opening range breakouts, which is widely used in trading. Since I initially coded in Pine Script v4, I used ChatGPT to help refine and migrate the script to Pine Script v6 to ensure compatibility with the latest TradingView features. However, the core logic, structure, and customization were entirely designed and implemented based on my own approach.
I am making this indicator public not to violate any TradingView guidelines but to share my work with the trading community and provide a tool that can help others analyze ORB-based strategies. If there are any compliance concerns, I am open to adjusting the script accordingly, but I want to clarify that this is not a copy of any existing ORB script—it is a custom-built indicator tailored to my own trading preferences.
I appreciate the opportunity to contribute to the community and would welcome any specific feedback from TradingView regarding rule compliance.
Best regards,
Janko S. (Schwarzman)
Appeal to TradingView
Dear TradingView Team,
This script is 100% self-developed and does not copy or replicate any third-party code. It is a customized ORB tool designed for traders who wish to backtest and analyze opening range breakout strategies over multiple sessions. We kindly request specific clarification regarding which exact line(s) of code violate TradingView’s guidelines. If there are any compliance concerns, we are happy to adjust the script accordingly.
Please let us know the precise rules or community guidelines that were violated so we can make the necessary modifications.
🚀 Summary
✔ Fully Custom & Self-Developed – No copied or third-party code.
✔ Innovative Feature – Connects past ORBs for strategy backtesting.
✔ Transparent & Compliant – Requesting exact details on any potential rule violations.

Moving Volume DensityMoving Volume Density (MVD) is a custom TradingView indicator written in Pine Script™ (version 6) that blends volume analysis with price range data to offer a unique perspective on market dynamics. By measuring the total volume over a specified period and relating it to the price range during the same interval, this indicator provides valuable insights into the concentration of trading activity relative to price movement.
Key Features:
User-Defined Period: The indicator uses an input period (default 20 bars) to calculate both the total volume and the price range. This flexibility allows you to tailor the analysis to your preferred timeframe.
Volume Calculation: It computes the sum of the volume over the defined period, capturing the cumulative trading activity.
Price Range Determination: The indicator identifies the highest high and the lowest low within the period, calculating the price range (difference between the two). This range serves as the denominator in the density calculation.
Volume Density Computation: Volume Density is derived by dividing the total volume by the price range. This metric reveals how concentrated the volume is within the observed price movement. To prevent division errors, the calculation returns 'NA' when the price range is zero.
Visual Representation: The resulting Volume Density is plotted as a line on a separate sub-window, making it easy to compare with other indicators or overlay your analysis.
「Moving Volume Density (MVD) インジケーター」は、Pine Script™(バージョン6)で作成されたカスタムインジケーターです。出来高の分析と、指定期間内の高値・安値による価格レンジの情報を組み合わせることで、市場のダイナミクスに対する独自の視点を提供します。指定された期間内の合計出来高とその期間内の価格レンジの比率から、価格変動に対する出来高の集中度を示す指標となります。
主な特徴:
ユーザー定義の期間: インジケーターは、入力された期間(デフォルトは20本のバー)を基に、合計出来高と価格レンジ(最高値と最安値の差)の両方を計算します。これにより、ご自身の分析に合わせた柔軟な設定が可能です。
出来高の計算: 指定期間内の全出来高を合計することで、累積的な取引活動を把握します。
価格レンジの算出: 期間内の最高値と最安値を取得し、その差を価格レンジとして算出。このレンジは、出来高密度の計算における分母として使用されます。
出来高密度の計算: 合計出来高を価格レンジで割ることで、出来高がどれだけ価格変動内に集中しているかを示す「出来高密度」を求めます。なお、価格レンジがゼロの場合はゼロ除算を避けるため「NA」を返す設計となっています。
視覚的な表現: 計算結果はサブウィンドウにラインとしてプロットされ、他のインジケーターとの併用や比較が容易に行えます。

ROBO STB Custom Weekly Candle (Fri-Thu)Description:
This indicator creates custom weekly candles that start on Friday and end on Thursday, instead of the standard Monday–Friday weekly structure in TradingView. It aggregates the open, high, low, and close (OHLC) values from Friday to Thursday and displays them as candlesticks on the chart.
Features:
✅ Custom weekly candles from Friday to Thursday
✅ Dynamic calculation of open, high, low, and close
✅ Works on any timeframe
✅ Helps traders analyze market structure differently
How It Works:
Identifies the custom weekly session based on Friday's start and Thursday's end.
Aggregates OHLC values within this time range.
Resets the values when a new custom week begins.
Plots the calculated weekly candles on the chart.
Use Case:
This indicator is useful for traders who prefer to analyze weekly price movements based on a non-standard start and end day, especially those focusing on forex, crypto, or commodities where trading hours differ.
Notes:
This script does not modify existing candles but overlays new custom weekly candles on the chart.
It does not repaint and updates in real-time.
If you find this useful, like and share! 🚀

Custom Length ATRThis Custom Length ATR Indicator allows traders to calculate the Average True Range (ATR) dynamically based on a selected timeframe and number of days. Unlike traditional ATR indicators that are tied to the chart’s timeframe, this script lets users choose a specific timeframe scale (e.g., Daily, Hourly, etc.), ensuring consistent volatility measurement across different trading views.