Code Upd: On Balance Volume Oscillator [LazyBear] v4One of the review indicator from me.
I reviewed code for more comfortable use - the basic code was not modified.
Enjoy it!
Wyszukaj w skryptach "one一季度财报"
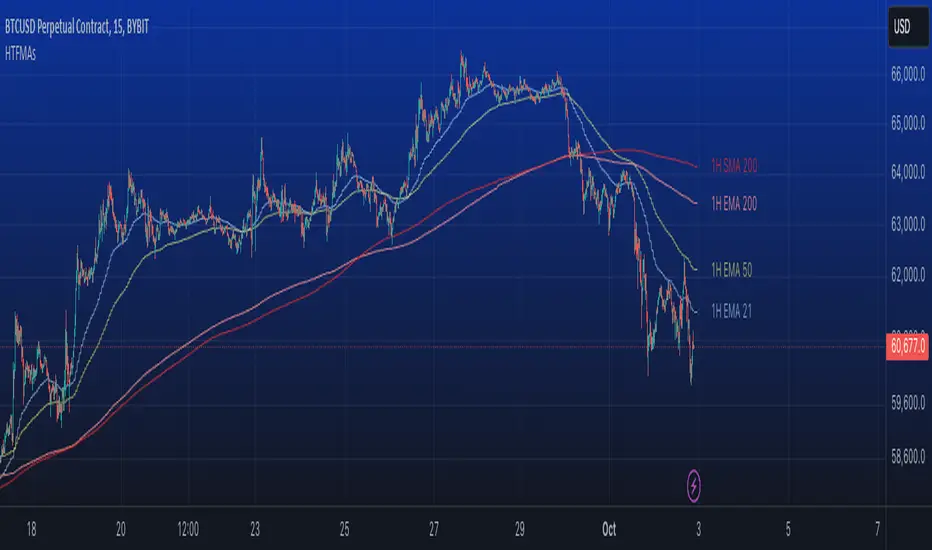
Common Moving averages ( 4 EMA + 3 SMA)Common moving averages used are included in the script. Customize them as per your wishes.
MA's set as default are
21 EMA
50 EMA , SMA
100 EMA , SMA
200 EMA , SMA
Please favorite it if you like it! Thanks!
RSI + Composite Index [SHK]One of the most powerful indicator based and divergence strategies i have ever seen was made by Constance Brown.
The Composite Index:
The best way to think of the Composite Index as it applies to the RSI is to think of the RSI as Windows 3.0 and the Composite Index as Windows 10. Constance Brown discovered that the RSI, while it does create and detect divergences, does is not as accurate as it could be. It’s a bit of an oxymoron to say this but the RSI is a momentum indicator without any momentum calculation attached to it. The RSI actually misses a significant amount of important moves and even generates some bad moves. What Constance Brown did with the RSI is to input a momentum calculation within the RSI itself.
Usage:
1. Check hidden and regular divergences on RSI+COMPOSITE_INDEX and PRICE+COMPOSITE_INDEX.
2. After finding divergence wait for COMPOSITE_INDEX to cross under/over it's moving averages to trigger.
Useful Note:
"RSI overbought/oversold as filter", "RSI and COMPOSITE_INDEX trendline as trigger", "RSI 50 Over/Under as trend direction detection", ... can be add to this strategy.
Enjoy!

Leeloo Quadruple (4x) Simple Moving AverageOne-stop shop for all of the simple moving averages because editing separately is annoying.

ATR stop and threshold valueOne can use the average true range for both entries and stops. A possible way to reduce false breakouts is to enter (say) at 0.5 * atr above the breakout level. Then you could use a 1.0*atr for a stop setting. This indicator allows you to set entries and stops for both long and short setups directly on the chart. I use it with breakout systems as it allows me to easily setup my trades.

Multiple Simple Moving AveragesOne no-fuss indicator for SMA for 6 different time period (10, 20, 50, 100, 200, 250), styled with sharp and thin line for shorter time period to light-coloured and wide line for longer time period.

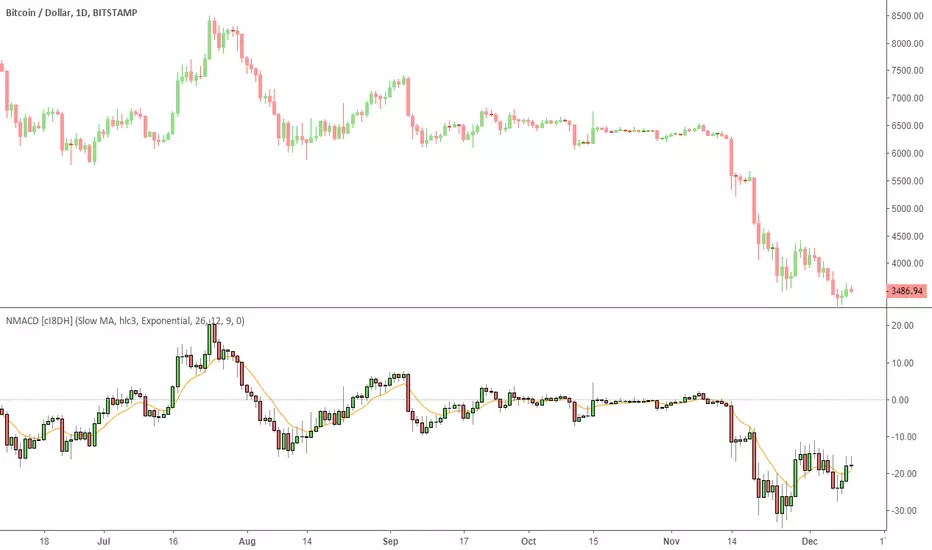
Multi Color Normalized MACD + Candles (NMACD) [cI8DH]One simple indicator for volatility, divergence and relative momentum
Features:
- Normalized MACD (by slow MA)
- Candle MACD (fast MA length is set to 0 in candle mode, i.e. price minus slow MA)
- Multi color histogram
- Background coloring based on MACD direction
- Choice of different MA types (Exponential, Simple, Weighted, Smoothed, Triple EMA)
- Triple EMA smoothing
Benefits of normalization:
- Absolutely better than RSI for comparing across different periods and assets
Applications and benefits of candle visualization:
- Zero cross: most traders use MAs overlaid on the main chart and look for price distance and MA cross visually. In candle mode, this indicator measures the difference between price and the slow moving MA. When this indicator crosses zero, it means price is crossing the slow moving MA.
- Divergence: full candle visualization (OHLC) is not possible for most other indicators. Candle visualization allows measuring divergence between price high, low and close simultaneously. Some trades incorrectly measure divergence between high, low of price against indicator tops and bottoms while having the indicator input set to default (usually close). With this indicator, you don't need to worry about such complexities.
Recommended setting:
- Enjoy candle mode :)
- Source set to hlc3
Fibonacci Exponential Moving Averages (+ 200EMA)One indicator to rule them all...
So here you have the fib based EMA`s (8,3,21,55) plus I added the 200 EMA cause I love it and should give you the complete picture. Have fun!
To add click on "Add to favorite scripts" and then select in your TV settings.
*Thanks to behind_crypto for publishing the base version of the script!*
EMA50Diff & MACD StrategyOne of my attempts to create a strategy for BTC.
Its a combination of EMA50Diff (the difference between spot and EMA50) and MACD.
Buy signal if (EMA50Diff) < -(EMADiffThreshold),
(MACD bearish crossunder),
(MACD) < -(MACDThreshold),
(EMA50Diff) > (EMA50Diff 1 candle ago),
(EMA50Diff 1 candle ago) < (EMA50Diff 2 candles ago)
Sell signal if (EMA50Diff) > (EMADiffThreshold),
(MACD bullish crossover),
(MACD) > (MACDThreshold),
(EMA50Diff) < (EMA50Diff 1 candle ago),
(EMA50Diff 1 candle ago) > (EMA50Diff 2 candles ago)
Exit either when target or stoploss get reached.
Initial capital is set to 100k and its currently going all-in on every trade but im looking for a better way to handle position sizes already..
Also i included slippage of 30 ticks and exchange commission of 0.15% (e.g. 2x BitMEX market taker fee)
Works best on 15m on bitfinex, bitstamp and gdax and i'm still trying to optimize it for bitmex too, will update when i got there..

RSI / Stoch / Stoch RSI (SRSI) Overlay [SigmaDraconis]One indicator combining RSI, Stochastic Oscillator and Stochastic RSI in one.
Credits for rwhiteside and his RSI / Stoch RSI Overlay indicator who served as inspiration to all three.
I believe this will be very useful to a lot of people.
If you like, use and i prove to be , you can contribute to my
TIP JAR :

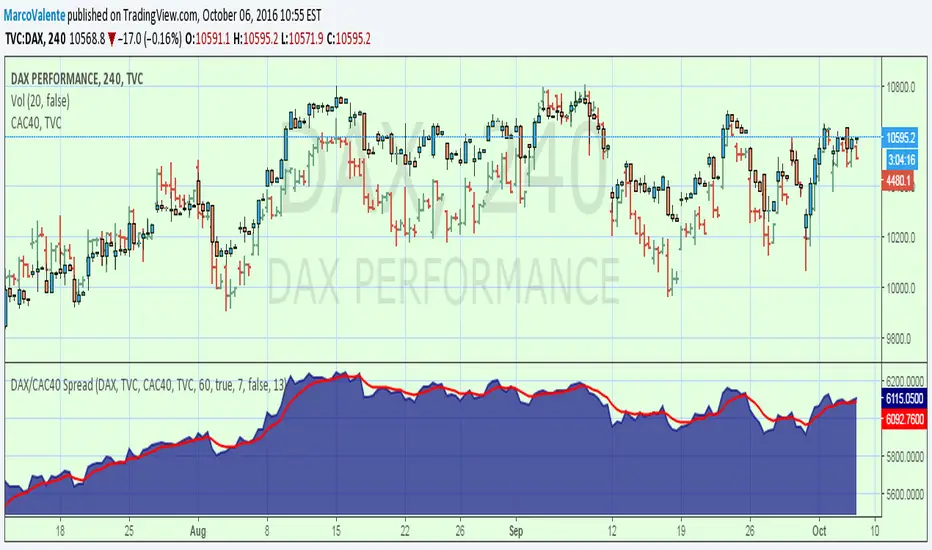
DAX/CAC40 SpreadOne more spread. You can change symbol by click on the input symbol window, and use anyone you like
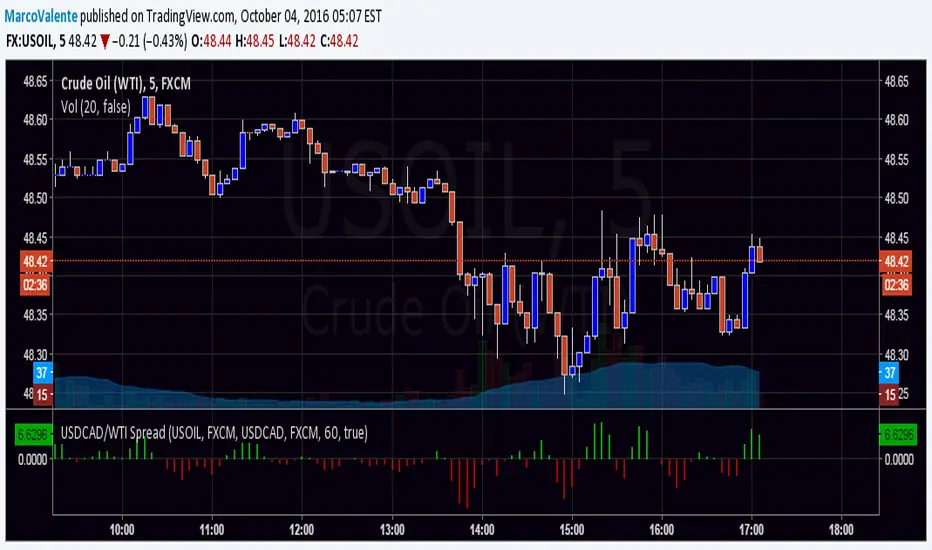
USDCAD/WTI SpreadOne more spread , this is USDCAD/WTI . Is the change of the moment of this 2 security.
One White Soldier StudyThis shows a green indicator on this study (17Jun & 15Aug on TRN) when a bullish candle opens and closes above the prior day's bearish candle, ignoring gap ups. This will only show in the DAILY chart, not intraday.

Ehlers Simple Cycle Indicator [LazyBear]One of the early cycle indicators from John Ehlers.
Ehlers suggests using this with ITrend (see linked PDF below). Osc/signal crosses identify entry/exit points.
Options page has the usual set of configurable params.
More info:
- Simple Cycle Indicator: www.mesasoftware.com
List of my public indicators: bit.ly
List of my app-store indicators: blog.tradingview.com

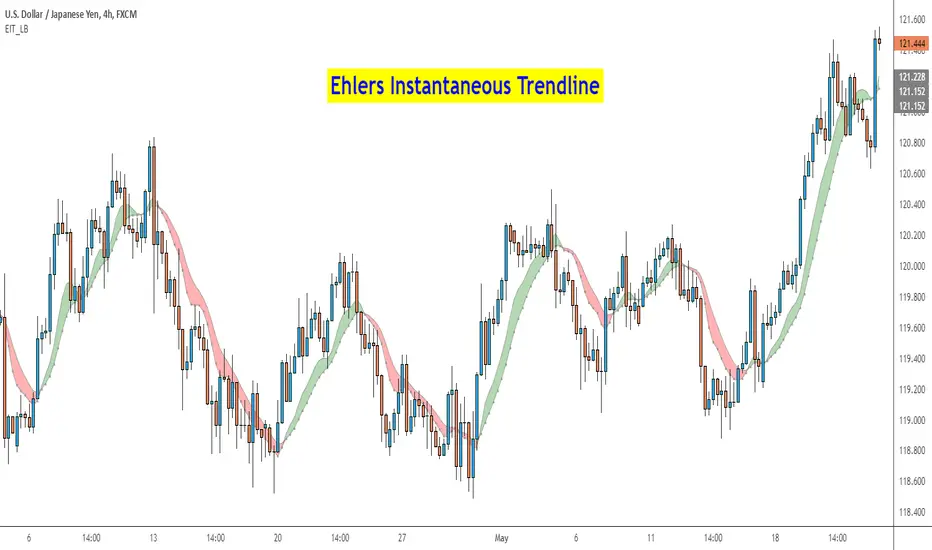
Ehlers Instantaneous Trend [LazyBear]One more to add to the Ehlers collection.
Ehlers Instantaneous Trendline, by John Ehlers, identifies the market trend by doing removing cycle component. I think, this simplicity is what makes it attractive :) To understand Ehlers's thought process behind this, refer to the PDF linked below.
There are atleast 6 variations of this ITrend. This version is from his early presentations.
Is this better than a simple HMA? May be, May be not. I will leave it to you to decide :)
I have added options to show this as a ribbon, and to color bars based on ITrend. Check out the options page.
More info:
- ITrend: www.mesasoftware.com
List of my public indicators: bit.ly
List of my app-store indicators: blog.tradingview.com
BTC Mon 8am Buy / Wed 2pm Sell (NY Time, Daily + Intraday)This strategy implements a fixed weekly time-based trading schedule for Bitcoin, using New York market hours as the reference clock. It is designed to test whether a consistent pattern exists between early-week accumulation and mid-week distribution in BTC price behavior.
Entry Rule — Monday 8:00 AM (NY Time)
The strategy enters a long position every Monday at exactly 08:00 AM Eastern Time, one hour after the U.S. equities market pre-open activity begins influencing global liquidity.
This timing attempts to capture early-week directional moves in Bitcoin, which sometimes occur as traditional markets come online.
Exit Rule — Wednesday 2:00 PM (NY Time)
The strategy closes the position every Wednesday at 2:00 PM Eastern Time, a point in the week where:
U.S. equity markets are still open
BTC often experiences mid-week volatility rotations
Liquidity is generally high
This exit removes exposure before later-week uncertainty and gives a consistent, measurable time window for each trade.
Timeframe Compatibility
Works on intraday charts (recommended 1h or lower) using precise time-based triggers.
Also runs on daily charts, where entries and exits occur on the Monday and Wednesday bars respectively (daily charts cannot show intraday timestamps).
All timestamps are synced to America/New_York regardless of the exchange’s native timezone.
Trading Frequency
Exactly one trade per week, preventing overtrading and allowing comparison of weekly performance across years of historical BTC price data.
Purpose of the Strategy
This is not a value-based or trend-following system, but a behavioral/time-cycle analysis tool.
It helps evaluate whether a repeating short-term edge exists based solely on:
Weekday timing
Liquidity cycles
Institutional market influence
BTC’s habitual early-week momentum patterns
It is ideal for:
Backtesting weekly BTC behavior
Studying time-based edges
Comparing alternative weekday/time combinations
Visualizing weekly P&L structure
Risk Notes
This strategy does not attempt to predict price direction and should not be assumed profitable without robust backtesting.
Time-based edges can appear, disappear, or invert depending on macro conditions.
There is no stop loss or risk management included by default, so the strategy reflects raw timing-based performance.

BTC Mon 8am Buy / Wed 2pm Sell (NY Time, Daily + Intraday)This strategy implements a fixed weekly time-based trading schedule for Bitcoin, using New York market hours as the reference clock. It is designed to test whether a consistent pattern exists between early-week accumulation and mid-week distribution in BTC price behavior.
Entry Rule — Monday 8:00 AM (NY Time)
The strategy enters a long position every Monday at exactly 08:00 AM Eastern Time, one hour after the U.S. equities market pre-open activity begins influencing global liquidity.
This timing attempts to capture early-week directional moves in Bitcoin, which sometimes occur as traditional markets come online.
Exit Rule — Wednesday 2:00 PM (NY Time)
The strategy closes the position every Wednesday at 2:00 PM Eastern Time, a point in the week where:
U.S. equity markets are still open
BTC often experiences mid-week volatility rotations
Liquidity is generally high
This exit removes exposure before later-week uncertainty and gives a consistent, measurable time window for each trade.
Timeframe Compatibility
Works on intraday charts (recommended 1h or lower) using precise time-based triggers.
Also runs on daily charts, where entries and exits occur on the Monday and Wednesday bars respectively (daily charts cannot show intraday timestamps).
All timestamps are synced to America/New_York regardless of the exchange’s native timezone.
Trading Frequency
Exactly one trade per week, preventing overtrading and allowing comparison of weekly performance across years of historical BTC price data.
Purpose of the Strategy
This is not a value-based or trend-following system, but a behavioral/time-cycle analysis tool.
It helps evaluate whether a repeating short-term edge exists based solely on:
Weekday timing
Liquidity cycles
Institutional market influence
BTC’s habitual early-week momentum patterns
It is ideal for:
Backtesting weekly BTC behavior
Studying time-based edges
Comparing alternative weekday/time combinations
Visualizing weekly P&L structure
Risk Notes
This strategy does not attempt to predict price direction and should not be assumed profitable without robust backtesting.
Time-based edges can appear, disappear, or invert depending on macro conditions.
There is no stop loss or risk management included by default, so the strategy reflects raw timing-based performance.

RSI Analytic Volume Matrix [RAVM] Overview
RSI Analytic Volume Matrix is an overlay indicator that turns classic RSI into a multi-layered market-reading engine. Instead of treating RSI 30 and 70 as simple buy/sell lines, RAVM combines RSI geometry (angle and acceleration), statistical volume analysis, and a 5×5 VSA-inspired matrix to describe what is really happening inside each candle.
The script is designed as an educational and analytical tool. It does not generate trading signals. Instead, it helps you read the market context, understand where the pressure is coming from (buyers vs. sellers), and see how price, momentum, and volume interact in real time.
Concept & Philosophy
RAVM is built around a hierarchical logic and a few core ideas:
• Hierarchical State Machine: First, RSI defines a context (where we are in the 0–100 range). Then the geometric engine evaluates the angle-of-turn of RSI using a Z-Score. Only after a meaningful geometric event is detected does the system promote a bar to a potential setup (warning vs. confirmed).
• Geometric Primacy: The angle and acceleration of RSI (RSI geometry) are more important than the raw RSI level itself. RAVM uses a geometric veto: if the geometric trigger is not confirmed, the confidence score is capped below 50%, even if volume looks interesting.
• RSI Beyond 30 and 70: Being above 70 or below 30 is not treated as an automatic overbought/oversold signal. RAVM treats those zones as contextual factors that contribute only a partial portion of the final score, alongside geometry, total volume expansion, buy/sell balance, and delta power.
• Volume Decomposition: Volume is decomposed into total, buy-side, sell-side, and delta components. Each of these is normalized with a Z-Score over a shared statistical window, so RSI geometry and volume live in the same statistical context.
• Educational Scoring Pipeline: RAVM builds a 0–100 "Quantum Score" for each detected setup. The score expresses how strong the story is across four dimensions: geometry (RSI angle-of-turn), total volume expansion, which side is driving that volume (buyers vs. sellers), and the power of delta. The score is designed for learning and weighting, not for mechanical trade entries.
• VSA Matrix Engine: A 5×5 matrix combines momentum states and volume dynamics. Each cell corresponds to an interpreted VSA-style scenario (Absorption, Distribution, No Demand, Stopping Volume, Strong Reversal, etc.), shown both as text and as a heatmap dashboard on the chart.
How RAVM Works
1. RSI Context & Geometry
RAVM starts with a classic RSI, but it does not stop at simple level checks. It computes the velocity and acceleration of RSI and normalizes them via a Z-Score to produce an Angle-of-Turn metric (Z-AoT). This Z-AoT is then mapped into a 0–1 intensity value called MSI (Momentum Shift Intensity).
The script monitors both classic RSI zones (around 30 and 70) and geometric triggers. Entering the lower or upper zone is treated as a contextual event only. A setup becomes "confirmed" when a significant geometric turn is detected (based on Z-AoT thresholds). Otherwise, the bar is at most a warning.
2. Volume & Statistical Engine
The volume engine can work in two modes: a geometric approximation (based on candle structure) or a more precise intrabar mode using up/down volume requests. In both cases, RAVM builds a volume packet consisting of:
• Total volume
• Buy-side volume
• Sell-side volume
• Delta (buy – sell)
Each of these series is normalized using a Z-Score over the same statistical window that is used for RSI geometry. This allows RAVM to answer questions such as: Is total volume exceptional on this bar? Is the expansion mostly coming from buyers or from sellers? Is delta unusually strong or weak compared to recent history?
3. Scoring System (Quantum Score)
For each bar where a setup is active, RAVM computes a 0–100 score intended as an educational confidence measure. The scoring pipeline follows this sequence:
A. RSI Geometry (MSI): Measures the strength of the RSI angle-of-turn via Z-AoT. This has geometric primacy over simple level checks.
B. RSI Zone Context: Being below 30 or above 70 contributes only a partial bonus to the score, reflecting the idea that these zones are context, not automatic signals. Mildly supportive zones (e.g., RSI below 50 for bullish contexts) can also contribute with lower weight.
C. Total Volume Expansion: A normalized Volume Power term expresses how exceptional the total volume is relative to its recent distribution. If there is no meaningful volume expansion, the score remains modest even if RSI geometry looks interesting.
D. Which Side Is Driving the Volume: RAVM then checks whether the expansion is primarily on the buy side or the sell side, using Z-Score statistics for buy and sell volume separately. This stage does not yet rely on delta as a power metric; it simply answers the question: "Is this expansion mostly driven by buyers, sellers, or both?"
E. Delta as Final Power: Only at the final stage does the script bring in delta and its Z-Score as a measure of how one-sided the pressure really is. A strong negative delta during a bullish context, for example, can highlight absorption, while a strong positive delta against a bearish context can highlight distribution or a buying climax.
If a setup is not geometrically confirmed (for example, a simple entry into RSI 30/70 without a strong geometric turn), RAVM caps the final score below 50%. This "Geometric Veto" enforces the idea that RSI geometry must confirm before a scenario can be considered high-confidence.
4. Overlay UI & Smart Labels
RAVM is an overlay indicator: all information is drawn directly on the price chart, not in a separate pane. When a setup is active, a smart label is attached to the bar, together with a vertical connector line. Each label shows:
• Direction of the setup (bullish or bearish)
• Trigger type (classic OS/OB vs. geometric/hidden)
• Status (warning vs. confirmed)
• Quantum Score as a percentage
Confirmed setups use stronger colors and solid connectors, while warnings use softer colors and dotted connectors. The script also manages label placement to avoid overlap, keeping the chart clean and readable.
In addition to labels, a dashboard table is drawn on the chart. It displays the currently active matrix scenario, the dominant bias, a short textual interpretation, the full 5×5 heatmap, and summary metrics such as RSI, MSI, and Volume Power.
RSI Is Not Just 30 and 70
One of the central design decisions in RAVM is to treat RSI 30 and 70 as context, not as fixed buy/sell buttons. Many traders mechanically assume that RSI below 30 means "buy" and RSI above 70 means "sell". RAVM explicitly rejects this simplification.
Instead, the script asks a series of deeper questions: How sharp is the angle-of-turn of RSI right now? Is total volume expanding or contracting? Is that expansion dominated by buyers or sellers? Is delta confirming the move, or is there a hidden absorption or distribution taking place?
In the scoring logic, being in a lower or upper RSI zone contributes only part of the final score. Geometry, volume expansion, the buy/sell split, and delta power all have to align before a high-confidence scenario emerges. This makes RAVM much closer to a structured market-reading tool than a classic overbought/oversold indicator.
Matrix User Manual – Reading the 5×5 Grid
The heart of RAVM is its 5×5 matrix, where the vertical axis represents momentum states (M1–M5) and the horizontal axis represents volume dynamics (V1–V5). Each cell in this grid corresponds to a VSA-style scenario. The dashboard highlights the currently active cell and prints a textual description so you can read the story at a glance.
1. Confirmation Scenarios
These scenarios occur when momentum direction and volume expansion are aligned:
• Bullish Confirmation / Strong Reversal: Momentum is shifting strongly upward (often from a depressed RSI context), and expanded volume is driven mainly by buyers. Often seen as a strong bullish reversal or continuation signal from a VSA perspective.
• Bearish Confirmation / Strong Drop: Momentum is turning decisively downward, and expanded volume is driven mainly by sellers. This maps to strong bearish continuation or sharp reversal patterns.
2. Absorption & Stopping Volume
• Absorption: Total volume expands, but the dominant flow is opposite to the recent price move or the geometric bias. For example, heavy selling volume while the geometric context is bullish. This can indicate smart money quietly absorbing orders from the crowd.
• Stopping Volume: Exceptionally high volume appears near the end of an extended move, while momentum begins to decelerate. Price may still print new extremes, but the effort vs. result relationship signals potential exhaustion and the possibility of a turn.
3. Distribution & Buying Climax
• Distribution: Heavy buying volume appears within a bearish or topping context. Rather than healthy accumulation, this often represents larger players offloading inventory to late buyers. The matrix will typically flag this as a bearish-leaning scenario despite strong upside prints.
• Buying Climax: A surge of buy-side volume near the end of a strong uptrend, with momentum starting to weaken. From a VSA point of view, this is often the last push where retail aggressively buys what smart money is selling.
4. No Demand & No Supply
• No Demand: Price attempts to rise but does so on low, non-expansive volume. The market is not interested in following the move, and the lack of participation often precedes weakness or sideways action.
• No Supply: Price tries to push lower on thin volume. Selling pressure is limited, and the lack of supply can precede stabilization or recovery if buyers step back in.
5. Trend Exhaustion
• Uptrend Exhaustion: Momentum remains nominally bullish, but the quality of volume deteriorates (e.g., more effort, less net result). The matrix marks this as an uptrend losing internal strength, often after a series of aggressive moves.
• Downtrend Exhaustion: Similar logic in the opposite direction: strong prior downtrend, but increasingly inefficient downside progress relative to the volume invested. This can precede accumulation or a relief rally.
6. Effort vs. Result Scenarios
• Bullish Effort, Little Result: Buyers invest notable volume, but price progress is limited. This may reveal hidden selling into strength or a lack of follow-through from the broader market.
• Bearish Effort, Little Result: Sellers push volume, but price does not decline proportionally. This can indicate absorption of selling pressure and potential underlying demand.
7. Neutral, Churn & Thin Markets
• Neutral / Thin Market: Momentum and volume both remain muted. RAVM marks these as neutral cells where aggressive decision-making is usually less attractive and observing the broader structure is more important.
• High Volume Churn / Volatility: Both sides are active with high volume but limited directional progress. This can correspond to battle zones, local ranges, or high volatility rotations where the main message is conflict rather than clear trend.
Inputs & Options
RAVM includes several input groups to adapt the tool to your preferences:
• Localization: Multiple language options for all labels and dashboard text (e.g., English, Farsi, Turkish, Russian).
• RSI Core Settings: RSI length, source, and upper/lower contextual zones (typically around 30 and 70).
• Geometric Engine: Z-AoT sigma thresholds, confirmation ratios, and normalization window multiplier. These control how sensitive the script is to RSI angle-of-turn events.
• Volume Engine: Choice between geometric approximation and intrabar up/down volume, Z-Score thresholds for volume expansion, and related parameters.
• Visual Interface: Toggles for smart labels, dashboard table, font sizes, dashboard position, and color themes for bullish, bearish, and warning states.
Disclaimer
RSI Analytic Volume Matrix is provided for educational and research purposes only. It does not constitute financial advice and is not a signal generator. Any trading decisions you make based on this tool, or any other, are entirely your own responsibility. Always consider your own risk management rules and conduct your own analysis.

ValueAtTime█ OVERVIEW
This library is a Pine Script® programming tool for accessing historical values in a time series using UNIX timestamps . Its data structure and functions index values by time, allowing scripts to retrieve past values based on absolute timestamps or relative time offsets instead of relying on bar index offsets.
█ CONCEPTS
UNIX timestamps
In Pine Script®, a UNIX timestamp is an integer representing the number of milliseconds elapsed since January 1, 1970, at 00:00:00 UTC (the UNIX Epoch ). The timestamp is a unique, absolute representation of a specific point in time. Unlike a calendar date and time, a UNIX timestamp's meaning does not change relative to any time zone .
This library's functions process series values and corresponding UNIX timestamps in pairs , offering a simplified way to identify values that occur at or near distinct points in time instead of on specific bars.
Storing and retrieving time-value pairs
This library's `Data` type defines the structure for collecting time and value information in pairs. Objects of the `Data` type contain the following two fields:
• `times` – An array of "int" UNIX timestamps for each recorded value.
• `values` – An array of "float" values for each saved timestamp.
Each index in both arrays refers to a specific time-value pair. For instance, the `times` and `values` elements at index 0 represent the first saved timestamp and corresponding value. The library functions that maintain `Data` objects queue up to one time-value pair per bar into the object's arrays, where the saved timestamp represents the bar's opening time .
Because the `times` array contains a distinct UNIX timestamp for each item in the `values` array, it serves as a custom mapping for retrieving saved values. All the library functions that return information from a `Data` object use this simple two-step process to identify a value based on time:
1. Perform a binary search on the `times` array to find the earliest saved timestamp closest to the specified time or offset and get the element's index.
2. Access the element from the `values` array at the retrieved index, returning the stored value corresponding to the found timestamp.
Value search methods
There are several techniques programmers can use to identify historical values from corresponding timestamps. This library's functions include three different search methods to locate and retrieve values based on absolute times or relative time offsets:
Timestamp search
Find the value with the earliest saved timestamp closest to a specified timestamp.
Millisecond offset search
Find the value with the earliest saved timestamp closest to a specified number of milliseconds behind the current bar's opening time. This search method provides a time-based alternative to retrieving historical values at specific bar offsets.
Period offset search
Locate the value with the earliest saved timestamp closest to a defined period offset behind the current bar's opening time. The function calculates the span of the offset based on a period string . The "string" must contain one of the following unit tokens:
• "D" for days
• "W" for weeks
• "M" for months
• "Y" for years
• "YTD" for year-to-date, meaning the time elapsed since the beginning of the bar's opening year in the exchange time zone.
The period string can include a multiplier prefix for all supported units except "YTD" (e.g., "2W" for two weeks).
Note that the precise span covered by the "M", "Y", and "YTD" units varies across time. The "1M" period can cover 28, 29, 30, or 31 days, depending on the bar's opening month and year in the exchange time zone. The "1Y" period covers 365 or 366 days, depending on leap years. The "YTD" period's span changes with each new bar, because it always measures the time from the start of the current bar's opening year.
█ CALCULATIONS AND USE
This library's functions offer a flexible, structured approach to retrieving historical values at or near specific timestamps, millisecond offsets, or period offsets for different analytical needs.
See below for explanations of the exported functions and how to use them.
Retrieving single values
The library includes three functions that retrieve a single stored value using timestamp, millisecond offset, or period offset search methods:
• `valueAtTime()` – Locates the saved value with the earliest timestamp closest to a specified timestamp.
• `valueAtTimeOffset()` – Finds the saved value with the earliest timestamp closest to the specified number of milliseconds behind the current bar's opening time.
• `valueAtPeriodOffset()` – Finds the saved value with the earliest timestamp closest to the period-based offset behind the current bar's opening time.
Each function has two overloads for advanced and simple use cases. The first overload searches for a value in a user-specified `Data` object created by the `collectData()` function (see below). It returns a tuple containing the found value and the corresponding timestamp.
The second overload maintains a `Data` object internally to store and retrieve values for a specified `source` series. This overload returns a tuple containing the historical `source` value, the corresponding timestamp, and the current bar's `source` value, making it helpful for comparing past and present values from requested contexts.
Retrieving multiple values
The library includes the following functions to retrieve values from multiple historical points in time, facilitating calculations and comparisons with values retrieved across several intervals:
• `getDataAtTimes()` – Locates a past `source` value for each item in a `timestamps` array. Each retrieved value's timestamp represents the earliest time closest to one of the specified timestamps.
• `getDataAtTimeOffsets()` – Finds a past `source` value for each item in a `timeOffsets` array. Each retrieved value's timestamp represents the earliest time closest to one of the specified millisecond offsets behind the current bar's opening time.
• `getDataAtPeriodOffsets()` – Finds a past value for each item in a `periods` array. Each retrieved value's timestamp represents the earliest time closest to one of the specified period offsets behind the current bar's opening time.
Each function returns a tuple with arrays containing the found `source` values and their corresponding timestamps. In addition, the tuple includes the current `source` value and the symbol's description, which also makes these functions helpful for multi-interval comparisons using data from requested contexts.
Processing period inputs
When writing scripts that retrieve historical values based on several user-specified period offsets, the most concise approach is to create a single text input that allows users to list each period, then process the "string" list into an array for use in the `getDataAtPeriodOffsets()` function.
This library includes a `getArrayFromString()` function to provide a simple way to process strings containing comma-separated lists of periods. The function splits the specified `str` by its commas and returns an array containing every non-empty item in the list with surrounding whitespaces removed. View the example code to see how we use this function to process the value of a text area input .
Calculating period offset times
Because the exact amount of time covered by a specified period offset can vary, it is often helpful to verify the resulting times when using the `valueAtPeriodOffset()` or `getDataAtPeriodOffsets()` functions to ensure the calculations work as intended for your use case.
The library's `periodToTimestamp()` function calculates an offset timestamp from a given period and reference time. With this function, programmers can verify the time offsets in a period-based data search and use the calculated offset times in additional operations.
For periods with "D" or "W" units, the function calculates the time offset based on the absolute number of milliseconds the period covers (e.g., `86400000` for "1D"). For periods with "M", "Y", or "YTD" units, the function calculates an offset time based on the reference time's calendar date in the exchange time zone.
Collecting data
All the `getDataAt*()` functions, and the second overloads of the `valueAt*()` functions, collect and maintain data internally, meaning scripts do not require a separate `Data` object when using them. However, the first overloads of the `valueAt*()` functions do not collect data, because they retrieve values from a user-specified `Data` object.
For cases where a script requires a separate `Data` object for use with these overloads or other custom routines, this library exports the `collectData()` function. This function queues each bar's `source` value and opening timestamp into a `Data` object and returns the object's ID.
This function is particularly useful when searching for values from a specific series more than once. For instance, instead of using multiple calls to the second overloads of `valueAt*()` functions with the same `source` argument, programmers can call `collectData()` to store each bar's `source` and opening timestamp, then use the returned `Data` object's ID in calls to the first `valueAt*()` overloads to reduce memory usage.
The `collectData()` function and all the functions that collect data internally include two optional parameters for limiting the saved time-value pairs to a sliding window: `timeOffsetLimit` and `timeframeLimit`. When either has a non-na argument, the function restricts the collected data to the maximum number of recent bars covered by the specified millisecond- and timeframe-based intervals.
NOTE : All calls to the functions that collect data for a `source` series can execute up to once per bar or realtime tick, because each stored value requires a unique corresponding timestamp. Therefore, scripts cannot call these functions iteratively within a loop . If a call to these functions executes more than once inside a loop's scope, it causes a runtime error.
█ EXAMPLE CODE
The example code at the end of the script demonstrates one possible use case for this library's functions. The code retrieves historical price data at user-specified period offsets, calculates price returns for each period from the retrieved data, and then populates a table with the results.
The example code's process is as follows:
1. Input a list of periods – The user specifies a comma-separated list of period strings in the script's "Period list" input (e.g., "1W, 1M, 3M, 1Y, YTD"). Each item in the input list represents a period offset from the latest bar's opening time.
2. Process the period list – The example calls `getArrayFromString()` on the first bar to split the input list by its commas and construct an array of period strings.
3. Request historical data – The code uses a call to `getDataAtPeriodOffsets()` as the `expression` argument in a request.security() call to retrieve the closing prices of "1D" bars for each period included in the processed `periods` array.
4. Display information in a table – On the latest bar, the code uses the retrieved data to calculate price returns over each specified period, then populates a two-row table with the results. The cells for each return percentage are color-coded based on the magnitude and direction of the price change. The cells also include tooltips showing the compared daily bar's opening date in the exchange time zone.
█ NOTES
• This library's architecture relies on a user-defined type (UDT) for its data storage format. UDTs are blueprints from which scripts create objects , i.e., composite structures with fields containing independent values or references of any supported type.
• The library functions search through a `Data` object's `times` array using the array.binary_search_leftmost() function, which is more efficient than looping through collected data to identify matching timestamps. Note that this built-in works only for arrays with elements sorted in ascending order .
• Each function that collects data from a `source` series updates the values and times stored in a local `Data` object's arrays. If a single call to these functions were to execute in a loop , it would store multiple values with an identical timestamp, which can cause erroneous search behavior. To prevent looped calls to these functions, the library uses the `checkCall()` helper function in their scopes. This function maintains a counter that increases by one each time it executes on a confirmed bar. If the count exceeds the total number of bars, indicating the call executes more than once in a loop, it raises a runtime error .
• Typically, when requesting higher-timeframe data with request.security() while using barmerge.lookahead_on as the `lookahead` argument, the `expression` argument should be offset with the history-referencing operator to prevent lookahead bias on historical bars. However, the call in this script's example code enables lookahead without offsetting the `expression` because the script displays results only on the last historical bar and all realtime bars, where there is no future data to leak into the past. This call ensures the displayed results use the latest data available from the context on realtime bars.
Look first. Then leap.
█ EXPORTED TYPES
Data
A structure for storing successive timestamps and corresponding values from a dataset.
Fields:
times (array) : An "int" array containing a UNIX timestamp for each value in the `values` array.
values (array) : A "float" array containing values corresponding to the timestamps in the `times` array.
█ EXPORTED FUNCTIONS
getArrayFromString(str)
Splits a "string" into an array of substrings using the comma (`,`) as the delimiter. The function trims surrounding whitespace characters from each substring, and it excludes empty substrings from the result.
Parameters:
str (series string) : The "string" to split into an array based on its commas.
Returns: (array) An array of trimmed substrings from the specified `str`.
periodToTimestamp(period, referenceTime)
Calculates a UNIX timestamp representing the point offset behind a reference time by the amount of time within the specified `period`.
Parameters:
period (series string) : The period string, which determines the time offset of the returned timestamp. The specified argument must contain a unit and an optional multiplier (e.g., "1Y", "3M", "2W", "YTD"). Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the `referenceTime` value's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
referenceTime (series int) : The millisecond UNIX timestamp from which to calculate the offset time.
Returns: (int) A millisecond UNIX timestamp representing the offset time point behind the `referenceTime`.
collectData(source, timeOffsetLimit, timeframeLimit)
Collects `source` and `time` data successively across bars. The function stores the information within a `Data` object for use in other exported functions/methods, such as `valueAtTimeOffset()` and `valueAtPeriodOffset()`. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to collect. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: (Data) A `Data` object containing collected `source` values and corresponding timestamps over the allowed time range.
method valueAtTime(data, timestamp)
(Overload 1 of 2) Retrieves value and time data from a `Data` object's fields at the index of the earliest timestamp closest to the specified `timestamp`. Callable as a method or a function.
Parameters:
data (series Data) : The `Data` object containing the collected time and value data.
timestamp (series int) : The millisecond UNIX timestamp to search. The function returns data for the earliest saved timestamp that is closest to the value.
Returns: ( ) A tuple containing the following data from the `Data` object:
- The stored value corresponding to the identified timestamp ("float").
- The earliest saved timestamp that is closest to the specified `timestamp` ("int").
valueAtTime(source, timestamp, timeOffsetLimit, timeframeLimit)
(Overload 2 of 2) Retrieves `source` and time information for the earliest bar whose opening timestamp is closest to the specified `timestamp`. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timestamp (series int) : The millisecond UNIX timestamp to search. The function returns data for the earliest bar whose timestamp is closest to the value.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : (simple string) Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple containing the following data:
- The `source` value corresponding to the identified timestamp ("float").
- The earliest bar's timestamp that is closest to the specified `timestamp` ("int").
- The current bar's `source` value ("float").
method valueAtTimeOffset(data, timeOffset)
(Overload 1 of 2) Retrieves value and time data from a `Data` object's fields at the index of the earliest saved timestamp closest to `timeOffset` milliseconds behind the current bar's opening time. Callable as a method or a function.
Parameters:
data (series Data) : The `Data` object containing the collected time and value data.
timeOffset (series int) : The millisecond offset behind the bar's opening time. The function returns data for the earliest saved timestamp that is closest to the calculated offset time.
Returns: ( ) A tuple containing the following data from the `Data` object:
- The stored value corresponding to the identified timestamp ("float").
- The earliest saved timestamp that is closest to `timeOffset` milliseconds before the current bar's opening time ("int").
valueAtTimeOffset(source, timeOffset, timeOffsetLimit, timeframeLimit)
(Overload 2 of 2) Retrieves `source` and time information for the earliest bar whose opening timestamp is closest to `timeOffset` milliseconds behind the current bar's opening time. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffset (series int) : The millisecond offset behind the bar's opening time. The function returns data for the earliest bar's timestamp that is closest to the calculated offset time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple containing the following data:
- The `source` value corresponding to the identified timestamp ("float").
- The earliest bar's timestamp that is closest to `timeOffset` milliseconds before the current bar's opening time ("int").
- The current bar's `source` value ("float").
method valueAtPeriodOffset(data, period)
(Overload 1 of 2) Retrieves value and time data from a `Data` object's fields at the index of the earliest timestamp closest to a calculated offset behind the current bar's opening time. The calculated offset represents the amount of time covered by the specified `period`. Callable as a method or a function.
Parameters:
data (series Data) : The `Data` object containing the collected time and value data.
period (series string) : The period string, which determines the calculated time offset. The specified argument must contain a unit and an optional multiplier (e.g., "1Y", "3M", "2W", "YTD"). Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the current bar's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
Returns: ( ) A tuple containing the following data from the `Data` object:
- The stored value corresponding to the identified timestamp ("float").
- The earliest saved timestamp that is closest to the calculated offset behind the bar's opening time ("int").
valueAtPeriodOffset(source, period, timeOffsetLimit, timeframeLimit)
(Overload 2 of 2) Retrieves `source` and time information for the earliest bar whose opening timestamp is closest to a calculated offset behind the current bar's opening time. The calculated offset represents the amount of time covered by the specified `period`. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
period (series string) : The period string, which determines the calculated time offset. The specified argument must contain a unit and an optional multiplier (e.g., "1Y", "3M", "2W", "YTD"). Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the current bar's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple containing the following data:
- The `source` value corresponding to the identified timestamp ("float").
- The earliest bar's timestamp that is closest to the calculated offset behind the current bar's opening time ("int").
- The current bar's `source` value ("float").
getDataAtTimes(timestamps, source, timeOffsetLimit, timeframeLimit)
Retrieves `source` and time information for each bar whose opening timestamp is the earliest one closest to one of the UNIX timestamps specified in the `timestamps` array. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
timestamps (array) : An array of "int" values representing UNIX timestamps. The function retrieves `source` and time data for each element in this array.
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple of the following data:
- An array containing a `source` value for each identified timestamp (array).
- An array containing an identified timestamp for each item in the `timestamps` array (array).
- The current bar's `source` value ("float").
- The symbol's description from `syminfo.description` ("string").
getDataAtTimeOffsets(timeOffsets, source, timeOffsetLimit, timeframeLimit)
Retrieves `source` and time information for each bar whose opening timestamp is the earliest one closest to one of the time offsets specified in the `timeOffsets` array. Each offset in the array represents the absolute number of milliseconds behind the current bar's opening time. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
timeOffsets (array) : An array of "int" values representing the millisecond time offsets used in the search. The function retrieves `source` and time data for each element in this array. For example, the array ` ` specifies that the function returns data for the timestamps closest to one day and one week behind the current bar's opening time.
source (float) : (series float) The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple of the following data:
- An array containing a `source` value for each identified timestamp (array).
- An array containing an identified timestamp for each offset specified in the `timeOffsets` array (array).
- The current bar's `source` value ("float").
- The symbol's description from `syminfo.description` ("string").
getDataAtPeriodOffsets(periods, source, timeOffsetLimit, timeframeLimit)
Retrieves `source` and time information for each bar whose opening timestamp is the earliest one closest to a calculated offset behind the current bar's opening time. Each calculated offset represents the amount of time covered by a period specified in the `periods` array. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
periods (array) : An array of period strings, which determines the time offsets used in the search. The function retrieves `source` and time data for each element in this array. For example, the array ` ` specifies that the function returns data for the timestamps closest to one day, week, and month behind the current bar's opening time. Each "string" in the array must contain a unit and an optional multiplier. Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the current bar's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
source (float) : (series float) The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple of the following data:
- An array containing a `source` value for each identified timestamp (array).
- An array containing an identified timestamp for each period specified in the `periods` array (array).
- The current bar's `source` value ("float").
- The symbol's description from `syminfo.description` ("string").

Adaptive Candlestick Pattern Recognition System█ INTRODUCTION
Nearly three years in the making, intermittently worked on in the few spare hours of weekends and time off, this is a passion project I undertook to flesh out my skills as a computer programmer. This script currently recognizes 85 different candlestick patterns ranging from one to five candles in length. It also performs statistical analysis on those patterns to determine prior performance and changes the coloration of those patterns based on that performance. In searching TradingView's script library for scripts similar to this one, I had found a handful. However, when I reviewed the ones which were open source, I did not see many that truly captured the power of PineScrypt or leveraged the way it works to create efficient and reliable code; one of the main driving factors for releasing this 5,000+ line behemoth open sourced.
Please take the time to review this description and source code to utilize this script to its fullest potential.
█ CONCEPTS
This script covers the following topics: Candlestick Theory, Trend Direction, Higher Timeframes, Price Analysis, Statistic Analysis, and Code Design.
Candlestick Theory - This script focuses solely on the concept of Candlestick Theory: arrangements of candlesticks may form certain patterns that can potentially influence the future price action of assets which experience those patterns. A full list of patterns (grouped by pattern length) will be in its own section of this description. This script contains two modes of operation for identifying candlestick patterns, 'CLASSIC' and 'BREAKOUT'.
CLASSIC: In this mode, candlestick patterns will be identified whenever they appear. The user has a wide variety of inputs to manipulate that can change how certain patterns are identified and even enable alerts to notify themselves when these patterns appear. Each pattern selected to appear will have their Profit or Loss (P/L) calculated starting from the first candle open succeeding the pattern to a candle close specified some number of candles ahead. These P/L calculations are then collected for each pattern, and split among partitions of prior price action of the asset the script is currently applied to (more on that in Higher Timeframes ).
BREAKOUT: In this mode, P/L calculations are held off until a breakout direction has been confirmed. The user may specify the number of candles ahead of a pattern's appearance (from one to five) that a pattern has to confirm a breakout in either an upward or downward direction. A breakout is constituted when there is a candle following the appearance of the pattern that closes above/at the highest high of the pattern, or below/at its lowest low. Only then will percent return calculations be performed for the pattern that's been identified, and these percent returns are broken up not only by the partition they had appeared in but also by the breakout direction itself. Patterns which do not breakout in either direction will be ignored, along with having their labels deleted.
In both of these modes, patterns may be overridden. Overrides occur when a smaller pattern has been detected and ends up becoming one (or more) of the candles of a larger pattern. A key example of this would be the Bearish Engulfing and the Three Outside Down patterns. A Three Outside Down necessitates a Bearish Engulfing as the first two candles in it, while the third candle closes lower. When a pattern is overridden, the return for that pattern will no longer be tracked. Overrides will not occur if the tail end of a larger pattern occurs at the beginning of a smaller pattern (Ex: a Bullish Engulfing occurs on the third candle of a Three Outside Down and the candle immediately following that pattern, the Three Outside Down pattern will not be overridden).
Important Functionality Note: These patterns are only searched for at the most recently closed candle, not on the currently closing candle, which creates an offset of one for this script's execution. (SEE LIMITATIONS)
Trend Direction - Many of the patterns require a trend direction prior to their appearance. Noting TradingView's own publication of candlestick patterns, I utilize a similar method for determining trend direction. Moving Averages are used to determine which trend is currently taking place for candlestick patterns to be sought out. The user has access to two Moving Averages which they may individually modify the following for each: Moving Average type (list of 9), their length, width, source values, and all variables associated with two special Moving Averages (Least Squares and Arnaud Legoux).
There are 3 settings for these Moving Averages, the first two switch between the two Moving Averages, and the third uses both. When using individual Moving Averages, the user may select a 'price point' to compare against the Moving Average (default is close). This price point is compared to the Moving Average at the candles prior to the appearance of candle patterns. Meaning: The close compared to the Moving Average two candles behind determines the trend direction used for Candlestick Analysis of one candle patterns; three candles behind for two candle patterns and so on. If the selected price point is above the Moving Average, then the current trend is an 'uptrend', 'downtrend' otherwise.
The third setting using both Moving Averages will compare the lengths of each, and trend direction is determined by the shorter Moving Average compared to the longer one. If the shorter Moving Average is above the longer, then the current trend is an 'uptrend', 'downtrend' otherwise. If the lengths of the Moving Averages are the same, or both Moving Averages are Symmetrical, then MA1 will be used by default. (SEE LIMITATIONS)
Higher Timeframes - This script employs the use of Higher Timeframes with a few request.security calls. The purpose of these calls is strictly for the partitioning of an asset's chart, splitting the returns of patterns into three separate groups. The four inputs in control of this partitioning split the chart based on: A given resolution to grab values from, the length of time in that resolution, and 'Upper' and 'Lower Limits' which split the trading range provided by that length of time in that resolution that forms three separate groups. The default values for these four inputs will partition the current chart by the yearly high-low range where: the 'Upper' partition is the top 20% of that trading range, the 'Middle' partition is 80% to 33% of the trading range, and the 'Lower' partition covers the trading range within 33% of the yearly low.
Patterns which are identified by this script will have their returns grouped together based on which partition they had appeared in. For example, a Bullish Engulfing which occurs within a third of the yearly low will have its return placed separately from a Bullish Engulfing that occurred within 20% of the yearly high. The idea is that certain patterns may perform better or worse depending on when they had occurred during an asset's trading range.
Price Analysis - Price Analysis is a major part of this script's functionality as it can fundamentally change how patterns are shown to the user. The settings related to Price Analysis include setting the number of candles ahead of a pattern's appearance to determine the return of that pattern. In 'BREAKOUT' mode, an additional setting allows the user to specify where the P/L calculation will begin for a pattern that had appeared and confirmed. (SEE LIMITATIONS)
The calculation for percent returns of patterns is illustrated with the following pseudo-code (CLASSIC mode, this is a simplified version of the actual code):
type patternObj
int ID
int partition
type returnsArray
float returns
// No pattern found = na returned
patternObj TEST_VAL = f_FindPattern()
priorTestVal = TEST_VAL
if not na( priorTestVal )
pnlMatrixRow = priorTestVal.ID
pnlMatrixCol = priorTestVal.partition
matrixReturn = matrix.get(PERCENT_RETURNS, pnlMatrixRow, pnlMatrixCol)
percentReturn = ( (close - open ) / open ) * 100%
array.push(matrixReturn.returns, percentReturn)
Statistic Analysis - This script uses Pine's built-in array functions to conduct the Statistic Analysis for patterns. When a pattern is found and its P/L calculation is complete, its return is added to a 'Return Array' User-Defined-Type that contains numerous fields which retain information on a pattern's prior performance. The actual UDT is as follows:
type returnArray
float returns = na
int size = 0
float avg = 0
float median = 0
float stdDev = 0
int polarities = na
All values within this UDT will be updated when a return is added to it (some based on user input). The array.avg , array.median and array.stdev will be ran and saved into their respective fields after a return is placed in the 'returns' array. The 'polarities' integer array is what will be changed based on user input. The user specifies two different percentages that declare 'Positive' and 'Negative' returns for patterns. When a pattern returns above, below, or in between these two values, different indices of this array will be incremented to reflect the kind of return that pattern had just experienced.
These values (plus the full name, partition the pattern occurred in, and a 95% confidence interval of expected returns) will be displayed to the user on the tooltip of the labels that identify patterns. Simply scroll over the pattern label to view each of these values.
Code Design - Overall this script is as much of an art piece as it is functional. Its design features numerous depictions of ASCII Art that illustrate what is being attempted by the functions that identify patterns, and an incalculable amount of time was spent rewriting portions of code to improve its efficiency. Admittedly, this final version is nearly 1,000 lines shorter than a previous version (one which took nearly 30 seconds after compilation to run, and didn't do nearly half of what this version does). The use of UDTs, especially the 'patternObj' one crafted and redesigned from the Hikkake Hunter 2.0 I published last month, played a significant role in making this script run efficiently. There is a slight rigidity in some of this code mainly around pattern IDs which are responsible for displaying the abbreviation for patterns (as well as the full names under the tooltips, and the matrix row position for holding returns), as each is hard-coded to correspond to that pattern.
However, one thing I would like to mention is the extensive use of global variables for pattern detection. Many scripts I had looked over for ideas on how to identify candlestick patterns had the same idea; break the pattern into a set of logical 'true/false' statements derived from historically referencing candle OHLC values. Some scripts which identified upwards of 20 to 30 patterns would reference Pine's built-in OHLC values for each pattern individually, potentially requesting information from TradingView's servers numerous times that could easily be saved into a variable for re-use and only requested once per candle (what this script does).
█ FEATURES
This script features a massive amount of switches, options, floating point values, detection settings, and methods for identifying/tailoring pattern appearances. All modifiable inputs for patterns are grouped together based on the number of candles they contain. Other inputs (like those for statistics settings and coloration) are grouped separately and presented in a way I believe makes the most sense.
Not mentioned above is the coloration settings. One of the aims of this script was to make patterns visually signify their behavior to the user when they are identified. Each pattern has its own collection of returns which are analyzed and compared to the inputs of the user. The user may choose the colors for bullish, neutral, and bearish patterns. They may also choose the minimum number of patterns needed to occur before assigning a color to that pattern based on its behavior; a color for patterns that have not met this minimum number of occurrences yet, and a color for patterns that are still processing in BREAKOUT mode.
There are also an additional three settings which alter the color scheme for patterns: Statistic Point-of-Reference, Adaptive coloring, and Hard Limiting. The Statistic Point-of-Reference decides which value (average or median) will be compared against the 'Negative' and 'Positive Return Tolerance'(s) to guide the coloration of the patterns (or for Adaptive Coloring, the generation of a color gradient).
Adaptive Coloring will have this script produce a gradient that patterns will be colored along. The more bullish or bearish a pattern is, the further along the gradient those patterns will be colored starting from the 'Neutral' color (hard lined at the value of 0%: values above this will be colored bullish, bearish otherwise). When Adaptive Coloring is enabled, this script will request the highest and lowest values (these being the Statistic Point-of-Reference) from the matrix containing all returns and rewrite global variables tied to the negative and positive return tolerances. This means that all patterns identified will be compared with each other to determine bullish/bearishness in Adaptive Coloring.
Hard Limiting will prevent these global variables from being rewritten, so patterns whose Statistic Point-of-Reference exceed the return tolerances will be fully colored the bullish or bearish colors instead of a generated gradient color. (SEE LIMITATIONS)
Apart from the Candle Detection Modes (CLASSIC and BREAKOUT), there's an additional two inputs which modify how this script behaves grouped under a "MASTER DETECTION SETTINGS" tab. These two "Pattern Detection Settings" are 'SWITCHBOARD' and 'TARGET MODE'.
SWITCHBOARD: Every single pattern has a switch that is associated with its detection. When a switch is enabled, the code which searches for that pattern will be run. With the Pattern Detection Setting set to this, all patterns that have their switches enabled will be sought out and shown.
TARGET MODE: There is an additional setting which operates on top of 'SWITCHBOARD' that singles out an individual pattern the user specifies through a drop down list. The names of every pattern recognized by this script will be present along with an identifier that shows the number of candles in that pattern (Ex: " (# candles)"). All patterns enabled in the switchboard will still have their returns measured, but only the pattern selected from the "Target Pattern" list will be shown. (SEE LIMITATIONS)
The vast majority of other features are held in the one, two, and three candle pattern sections.
For one-candle patterns, there are:
3 — Settings related to defining 'Tall' candles:
The number of candles to sample for previous candle-size averages.
The type of comparison done for 'Tall' Candles: Settings are 'RANGE' and 'BODY'.
The 'Tolerance' for tall candles, specifying what percent of the 'average' size candles must exceed to be considered 'Tall'.
When 'Tall Candle Setting' is set to RANGE, the high-low ranges are what the current candle range will be compared against to determine if a candle is 'Tall'. Otherwise the candle bodies (absolute value of the close - open) will be compared instead. (SEE LIMITATIONS)
Hammer Tolerance - How large a 'discarded wick' may be before it disqualifies a candle from being a 'Hammer'.
Discarded wicks are compared to the size of the Hammer's candle body and are dependent upon the body's center position. Hammer bodies closer to the high of the candle will have the upper wick used as its 'discarded wick', otherwise the lower wick is used.
9 — Doji Settings, some pulled from an old Doji Hunter I made a while back:
Doji Tolerance - How large the body of a candle may be compared to the range to be considered a 'Doji'.
Ignore N/S Dojis - Turns off Trend Direction for non-special Dojis.
GS/DF Doji Settings - 2 Inputs that enable and specify how large wicks that typically disqualify Dojis from being 'Gravestone' or 'Dragonfly' Dojis may be.
4 Settings related to 'Long Wick Doji' candles detailed below.
A Tolerance for 'Rickshaw Man' Dojis specifying how close the center of the body must be to the range to be valid.
The 4 settings the user may modify for 'Long Legged' Dojis are: A Sample Base for determining the previous average of wicks, a Sample Length specifying how far back to look for these averages, a Behavior Setting to define how 'Long Legged' Dojis are recognized, and a tolerance to specify how large in comparison to the prior wicks a Doji's wicks must be to be considered 'Long Legged'.
The 'Sample Base' list has two settings:
RANGE: The wicks of prior candles are compared to their candle ranges and the 'wick averages' will be what the average percent of ranges were in the sample.
WICKS: The size of the wicks themselves are averaged and returned for comparing against the current wicks of a Doji.
The 'Behavior' list has three settings:
ONE: Only one wick length needs to exceed the average by the tolerance for a Doji to be considered 'Long Legged'.
BOTH: Both wick lengths need to exceed the average of the tolerance of their respective wicks (upper wicks are compared to upper wicks, lower wicks compared to lower) to be considered 'Long Legged'.
AVG: Both wicks and the averages of the previous wicks are added together, divided by two, and compared. If the 'average' of the current wicks exceeds this combined average of prior wicks by the tolerance, then this would constitute a valid 'Long Legged' Doji. (For Dojis in general - SEE LIMITATIONS)
The final input is one related to candle patterns which require a Marubozu candle in them. The two settings for this input are 'INCLUSIVE' and 'EXCLUSIVE'. If INCLUSIVE is selected, any opening/closing variant of Marubozu candles will be allowed in the patterns that require them.
For two-candle patterns, there are:
2 — Settings which define 'Engulfing' parameters:
Engulfing Setting - Two options, RANGE or BODY which sets up how one candle may 'engulf' the previous.
Inclusive Engulfing - Boolean which enables if 'engulfing' candles can be equal to the values needed to 'engulf' the prior candle.
For the 'Engulfing Setting':
RANGE: If the second candle's high-low range completely covers the high-low range of the prior candle, this is recognized as 'engulfing'.
BODY: If the second candle's open-close completely covers the open-close of the previous candle, this is recognized as 'engulfing'. (SEE LIMITATIONS)
4 — Booleans specifying different settings for a few patterns:
One which allows for 'opens within body' patterns to let the second candle's open/close values match the prior candles' open/close.
One which forces 'Kicking' patterns to have a gap if the Marubozu setting is set to 'INCLUSIVE'.
And Two which dictate if the individual candles in 'Stomach' patterns need to be 'Tall'.
8 — Floating point values which affect 11 different patterns:
One which determines the distance the close of the first candle in a 'Hammer Inverted' pattern must be to the low to be considered valid.
One which affects how close the opens/closes need to be for all 'Lines' patterns (Bull/Bear Meeting/Separating Lines).
One that allows some leeway with the 'Matching Low' pattern (gives a small range the second candle close may be within instead of needing to match the previous close).
Three tolerances for On Neck/In Neck patterns (2 and 1 respectively).
A tolerance for the Thrusting pattern which give a range the close the second candle may be between the midpoint and close of the first to be considered 'valid'.
A tolerance for the two Tweezers patterns that specifies how close the highs and lows of the patterns need to be to each other to be 'valid'.
The first On Neck tolerance specifies how large the lower wick of the first candle may be (as a % of that candle's range) before the pattern is invalidated. The second tolerance specifies how far up the lower wick to the close the second candle's close may be for this pattern. The third tolerance for the In Neck pattern determines how far into the body of the first candle the second may close to be 'valid'.
For the remaining patterns (3, 4, and 5 candles), there are:
3 — Settings for the Deliberation pattern:
A boolean which forces the open of the third candle to gap above the close of the second.
A tolerance which changes the proximity of the third candle's open to the second candle's close in this pattern.
A tolerance that sets the maximum size the third candle may be compared to the average of the first two candles.
One boolean value for the Two Crows patterns (standard and Upside Gapping) that forces the first two candles in the patterns to completely gap if disabled (candle 1's close < candle 2's low).
10 — Floating point values for the remaining patterns:
One tolerance for defining how much the size of each candle in the Identical Black Crows pattern may deviate from the average of themselves to be considered valid.
One tolerance for setting how close the opens/closes of certain three candle patterns may be to each other's opens/closes.*
Three floating point values that affect the Three Stars in the South pattern.
One tolerance for the Side-by-Side patterns - looks at the second and third candle closes.
One tolerance for the Stick Sandwich pattern - looks at the first and third candle closes.
A floating value that sizes the Concealing Baby Swallow pattern's 3rd candle wick.
Two values for the Ladder Bottom pattern which define a range that the third candle's wick size may be.
* This affects the Three Black Crows (non-identical) and Three White Soldiers patterns, each require the opens and closes of every candle to be near each other.
The first tolerance of the Three Stars in the South pattern affects the first candle body's center position, and defines where it must be above to be considered valid. The second tolerance specifies how close the second candle must be to this same position, as well as the deviation the ratio the candle body to its range may be in comparison to the first candle. The third restricts how large the second candle range may be in comparison to the first (prevents this pattern from being recognized if the second candle is similar to the first but larger).
The last two floating point values define upper and lower limits to the wick size of a Ladder Bottom's fourth candle to be considered valid.
█ HOW TO USE
While there are many moving parts to this script, I attempted to set the default values with what I believed may help identify the most patterns within reasonable definitions. When this script is applied to a chart, the Candle Detection Mode (along with the BREAKOUT settings) and all candle switches must be confirmed before patterns are displayed. All switches are on by default, so this gives the user an opportunity to pick which patterns to identify first before playing around in the settings.
All of the settings/inputs described above are meant for experimentation. I encourage the user to tweak these values at will to find which set ups work best for whichever charts they decide to apply these patterns to.
Refer to the patterns themselves during experimentation. The statistic information provided on the tooltips of the patterns are meant to help guide input decisions. The breadth of candlestick theory is deep, and this was an attempt at capturing what I could in its sea of information.
█ LIMITATIONS
DISCLAIMER: While it may seem a bit paradoxical that this script aims to use past performance to potentially measure future results, past performance is not indicative of future results . Markets are highly adaptive and often unpredictable. This script is meant as an informational tool to show how patterns may behave. There is no guarantee that confidence intervals (or any other metric measured with this script) are accurate to the performance of patterns; caution must be exercised with all patterns identified regardless of how much information regarding prior performance is available.
Candlestick Theory - In the name, Candlestick Theory is a theory , and all theories come with their own limits. Some patterns identified by this script may be completely useless/unprofitable/unpredictable regardless of whatever combination of settings are used to identify them. However, if I truly believed this theory had no merit, this script would not exist. It is important to understand that this is a tool meant to be utilized with an array of others to procure positive (or negative, looking at you, short sellers ) results when navigating the complex world of finance.
To address the functionality note however, this script has an offset of 1 by default. Patterns will not be identified on the currently closing candle, only on the candle which has most recently closed. Attempting to have this script do both (offset by one or identify on close) lead to more trouble than it was worth. I personally just want users to be aware that patterns will not be identified immediately when they appear.
Trend Direction - Moving Averages - There is a small quirk with how MA settings will be adjusted if the user inputs two moving averages of the same length when the "MA Setting" is set to 'BOTH'. If Moving Averages have the same length, this script will default to only using MA 1 regardless of if the types of Moving Averages are different . I will experiment in the future to alleviate/reduce this restriction.
Price Analysis - BREAKOUT mode - With how identifying patterns with a look-ahead confirmation works, the percent returns for patterns that break out in either direction will be calculated on the same candle regardless of if P/L Offset is set to 'FROM CONFIRMATION' or 'FROM APPEARANCE'. This same issue is present in the Hikkake Hunter script mentioned earlier. This does not mean the P/L calculations are incorrect , the offset for the calculation is set by the number of candles required to confirm the pattern if 'FROM APPEARANCE' is selected. It just means that these two different P/L calculations will complete at the same time independent of the setting that's been selected.
Adaptive Coloring/Hard Limiting - Hard Limiting is only used with Adaptive Coloring and has no effect outside of it. If Hard Limiting is used, it is recommended to increase the 'Positive' and 'Negative' return tolerance values as a pattern's bullish/bearishness may be disproportionately represented with the gradient generated under a hard limit.
TARGET MODE - This mode will break rules regarding patterns that are overridden on purpose. If a pattern selected in TARGET mode would have otherwise been absorbed by a larger pattern, it will have that pattern's percent return calculated; potentially leading to duplicate returns being included in the matrix of all returns recognized by this script.
'Tall' Candle Setting - This is a wide-reaching setting, as approximately 30 different patterns or so rely on defining 'Tall' candles. Changing how 'Tall' candles are defined whether by the tolerance value those candles need to exceed or by the values of the candle used for the baseline comparison (RANGE/BODY) can wildly affect how this script functions under certain conditions. Refer to the tooltip of these settings for more information on which specific patterns are affected by this.
Doji Settings - There are roughly 10 or so two to three candle patterns which have Dojis as a part of them. If all Dojis are disabled, it will prevent some of these larger patterns from being recognized. This is a dependency issue that I may address in the future.
'Engulfing' Setting - Functionally, the two 'Engulfing' settings are quite different. Because of this, the 'RANGE' setting may cause certain patterns that would otherwise be valid under textbook and online references/definitions to not be recognized as such (like the Upside Gap Two Crows or Three Outside down).
█ PATTERN LIST
This script recognizes 85 patterns upon initial release. I am open to adding additional patterns to it in the future and any comments/suggestions are appreciated. It recognizes:
15 — 1 Candle Patterns
4 Hammer type patterns: Regular Hammer, Takuri Line, Shooting Star, and Hanging Man
9 Doji Candles: Regular Dojis, Northern/Southern Dojis, Gravestone/Dragonfly Dojis, Gapping Up/Down Dojis, and Long-Legged/Rickshaw Man Dojis
White/Black Long Days
32 — 2 Candle Patterns
4 Engulfing type patterns: Bullish/Bearish Engulfing and Last Engulfing Top/Bottom
Dark Cloud Cover
Bullish/Bearish Doji Star patterns
Hammer Inverted
Bullish/Bearish Haramis + Cross variants
Homing Pigeon
Bullish/Bearish Kicking
4 Lines type patterns: Bullish/Bearish Meeting/Separating Lines
Matching Low
On/In Neck patterns
Piercing pattern
Shooting Star (2 Lines)
Above/Below Stomach patterns
Thrusting
Tweezers Top/Bottom patterns
Two Black Gapping
Rising/Falling Window patterns
29 — 3 Candle Patterns
Bullish/Bearish Abandoned Baby patterns
Advance Block
Collapsing Doji Star
Deliberation
Upside/Downside Gap Three Methods patterns
Three Inside/Outside Up/Down patterns (4 total)
Bullish/Bearish Side-by-Side patterns
Morning/Evening Star patterns + Doji variants
Stick Sandwich
Downside/Upside Tasuki Gap patterns
Three Black Crows + Identical variation
Three White Soldiers
Three Stars in the South
Bullish/Bearish Tri-Star patterns
Two Crows + Upside Gap variant
Unique Three River Bottom
3 — 4 Candle Patterns
Concealing Baby Swallow
Bullish/Bearish Three Line Strike patterns
6 — 5 Candle Patterns
Bullish/Bearish Breakaway patterns
Ladder Bottom
Mat Hold
Rising/Falling Three Methods patterns
█ WORKS CITED
Because of the amount of time needed to complete this script, I am unable to provide exact dates for when some of these references were used. I will also not provide every single reference, as citing a reference for each individual pattern and the place it was reviewed would lead to a bibliography larger than this script and its description combined. There were five major resources I used when building this script, one book, two websites (for various different reasons including patterns, moving averages, and various other articles of information), various scripts from TradingView's public library (including TradingView's own source code for *all* candle patterns ), and PineScrypt's reference manual.
Bulkowski, Thomas N. Encyclopedia of Candlestick Patterns . Hoboken, New Jersey: John Wiley & Sons Inc., 2008. E-book (google books).
Various. Numerous webpages. CandleScanner . 2023. online. Accessed 2020 - 2023.
Various. Numerous webpages. Investopedia . 2023. online. Accessed 2020 - 2023.
█ AKNOWLEDGEMENTS
I want to take the time here to thank all of my friends and family, both online and in real life, for the support they've given me over the last few years in this endeavor. My pets who tried their hardest to keep me from completing it. And work for the grit to continue pushing through until this script's completion.
This belongs to me just as much as it does anyone else. Whether you are an institutional trader, gold bug hedging against the dollar, retail ape who got in on a squeeze, or just parents trying to grow their retirement/save for the kids. This belongs to everyone.
Private Beta for new features to be tested can be found here .
Vires In Numeris
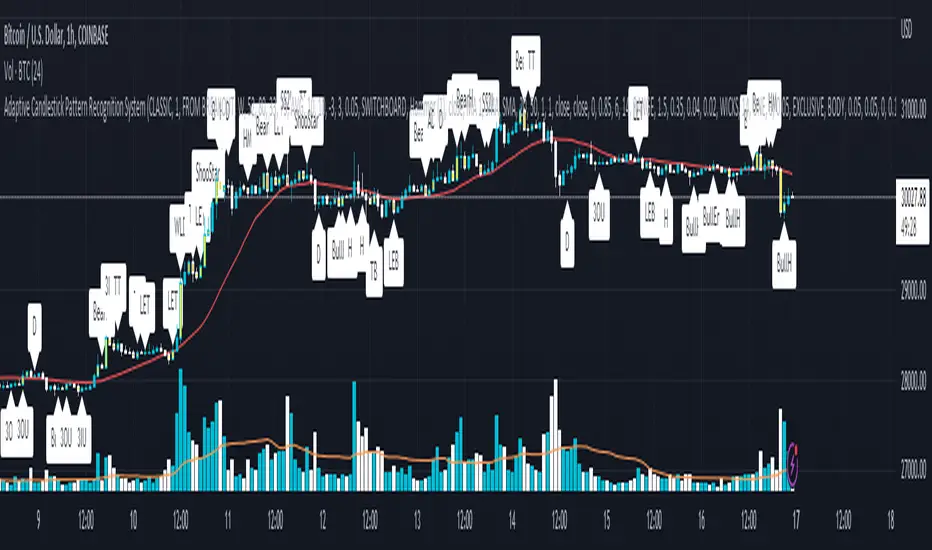
HTFMAs█ OVERVIEW
Contains a type HTFMA used to return data on six moving averages from a higher timeframe.
Several types of MA's are supported.
█ HOW TO USE
Please see instructions in the code (in library description). (Important: first fold all sections of the script: press Cmd + K then Cmd + - (for Windows Ctrl + K then Ctrl + -)
█ FULL LIST OF FUNCTIONS AND PARAMETERS
method getMaType(this)
Enumerator function, given a key returns `enum MaTypes` value
Namespace types: series string, simple string, input string, const string
Parameters:
this (string)
method init(this, enableAll, ma1Enabled, ma1MaType, ma1Src, ma1Prd, ma2Enabled, ma2MaType, ma2Src, ma2Prd, ma3Enabled, ma3MaType, ma3Src, ma3Prd, ma4Enabled, ma4MaType, ma4Src, ma4Prd, ma5Enabled, ma5MaType, ma5Src, ma5Prd, ma6Enabled, ma6MaType, ma6Src, ma6Prd)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs)
enableAll (simple MaEnable)
ma1Enabled (bool)
ma1MaType (series MaTypes)
ma1Src (string)
ma1Prd (int)
ma2Enabled (bool)
ma2MaType (series MaTypes)
ma2Src (string)
ma2Prd (int)
ma3Enabled (bool)
ma3MaType (series MaTypes)
ma3Src (string)
ma3Prd (int)
ma4Enabled (bool)
ma4MaType (series MaTypes)
ma4Src (string)
ma4Prd (int)
ma5Enabled (bool)
ma5MaType (series MaTypes)
ma5Src (string)
ma5Prd (int)
ma6Enabled (bool)
ma6MaType (series MaTypes)
ma6Src (string)
ma6Prd (int)
method init(this, enableAll, tf, rngAtrQ, showRecentBars, lblsOffset, lblsShow, lnOffset, lblSize, lblStyle, smoothen, ma1lnClr, ma1lnWidth, ma1lnStyle, ma2lnClr, ma2lnWidth, ma2lnStyle, ma3lnClr, ma3lnWidth, ma3lnStyle, ma4lnClr, ma4lnWidth, ma4lnStyle, ma5lnClr, ma5lnWidth, ma5lnStyle, ma6lnClr, ma6lnWidth, ma6lnStyle, ma1ShowHistory, ma2ShowHistory, ma3ShowHistory, ma4ShowHistory, ma5ShowHistory, ma6ShowHistory, ma1ShowLabel, ma2ShowLabel, ma3ShowLabel, ma4ShowLabel, ma5ShowLabel, ma6ShowLabel)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
enableAll (series MaEnable)
tf (string)
rngAtrQ (int)
showRecentBars (int)
lblsOffset (int)
lblsShow (bool)
lnOffset (int)
lblSize (string)
lblStyle (string)
smoothen (bool)
ma1lnClr (color)
ma1lnWidth (int)
ma1lnStyle (string)
ma2lnClr (color)
ma2lnWidth (int)
ma2lnStyle (string)
ma3lnClr (color)
ma3lnWidth (int)
ma3lnStyle (string)
ma4lnClr (color)
ma4lnWidth (int)
ma4lnStyle (string)
ma5lnClr (color)
ma5lnWidth (int)
ma5lnStyle (string)
ma6lnClr (color)
ma6lnWidth (int)
ma6lnStyle (string)
ma1ShowHistory (bool)
ma2ShowHistory (bool)
ma3ShowHistory (bool)
ma4ShowHistory (bool)
ma5ShowHistory (bool)
ma6ShowHistory (bool)
ma1ShowLabel (bool)
ma2ShowLabel (bool)
ma3ShowLabel (bool)
ma4ShowLabel (bool)
ma5ShowLabel (bool)
ma6ShowLabel (bool)
method get(this, id)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs)
id (int)
method set(this, id, prop, val)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs)
id (int)
prop (string)
val (string)
method set(this, id, prop, val)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
id (int)
prop (string)
val (string)
method htfUpdateTuple(rsParams, repaint)
Namespace types: RsParamsMAs
Parameters:
rsParams (RsParamsMAs)
repaint (bool)
method clear(this)
Namespace types: MaDrawing
Parameters:
this (MaDrawing)
method importRsRetTuple(this, htfBi, ma1, ma2, ma3, ma4, ma5, ma6)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
htfBi (int)
ma1 (float)
ma2 (float)
ma3 (float)
ma4 (float)
ma5 (float)
ma6 (float)
method getDrw(this, id)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
id (int)
method setDrwProp(this, id, prop, val)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
id (int)
prop (string)
val (string)
method initDrawings(this, rsPrms, dispBandWidth)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
rsPrms (RsParamsMAs)
dispBandWidth (float)
method updateDrawings(this, rsPrms, dispBandWidth)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
rsPrms (RsParamsMAs)
dispBandWidth (float)
method update(this)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps0 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps1 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps2 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps3 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps4 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps5 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `RsParamsMAs` child `RsMaCalcParams` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (RsParamsMAs) Target object to import prop values to.
oCfg (objProps6 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs)
oCfg (objProps7 type from moebius1977/CSVParser/1)
maCount (int)
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: RsParamsMAs
Parameters:
this (RsParamsMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps8 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps0 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps1 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps2 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps3 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps4 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps5 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Imports HTF MAs settings from objProps (of any level) into `HTFMAs` child `MaDrawing` objects (into the first first `maCount` of them)
Namespace types: HTFMAs
Parameters:
this (HTFMAs) : (HTFMAs) Target object to import prop values to.
oCfg (objProps6 type from moebius1977/CSVParser/1) : (CSVP.objProps) (one of objProps types) an objProps, ... opjProps8 containing properties' values in a child objProps objects
maCount (int) : (int) Number of tgtObj's RsMaCalcParams childs of tgtObj to set (1 to 6, starting from 1)
Returns: this
method importConfig(this, oCfg, maCount)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
oCfg (objProps7 type from moebius1977/CSVParser/1)
maCount (int)
method importConfig(this, oCfg, maCount)
Namespace types: HTFMAs
Parameters:
this (HTFMAs)
oCfg (objProps8 type from moebius1977/CSVParser/1)
maCount (int)
method newRsParamsMAs(this)
Namespace types: LO
Parameters:
this (LO)
method newHTFMAs(this)
Namespace types: LO
Parameters:
this (LO)
RsMaCalcParams
Parameters of one MA (only calculation params needed within req.sec(), visual parameters are within htfMAs type)
Fields:
enabled (series bool)
maType (series MaTypes) : MA type options: SMA / EMA / WMA / ...
src (series string)
prd (series int) : MA period
RsParamsMAs
Collection of parameters of 6 MAs. Used to pass params to req.sec()
Fields:
ma1CalcParams (RsMaCalcParams)
ma2CalcParams (RsMaCalcParams)
ma3CalcParams (RsMaCalcParams)
ma4CalcParams (RsMaCalcParams)
ma5CalcParams (RsMaCalcParams)
ma6CalcParams (RsMaCalcParams)
RsReturnMAs
Used to return data from req.sec().
Fields:
htfBi (series int)
ma1 (series float)
ma2 (series float)
ma3 (series float)
ma4 (series float)
ma5 (series float)
ma6 (series float)
MaDrawing
MA's plot parameters plus drawing objects for MA's current level (line and label).
Fields:
lnClr (series color) : (color) MA plot line color (like in plot())
lnWidth (series int) : (int) MA plot line width (like in plot())
lnStyle (series string) : (string) MA plot line style (like in plot())
showHistory (series bool) : (bool) Whether to plot the MA on historical bars or only show current level to the right of the latest bar.
showLabel (series bool) : (bool) Whether to show the name of the MA to the right of the MA's level
ln (series line) : (line) line to show MA"s current level
lbl (series label) : (label) label showing MA's name
HTFMAs
Contains data and drawing parameters for MA's of one timeframe (MA calculation parameters for MA's of one timeframe are in a separate object RsParamsMAs)
Fields:
rsRet (RsReturnMAs) : (RsReturnMAs) Contains data returned from req.sec(). Is set to na in between HTF bar changes if smoothing is enabled.
rsRetLast (RsReturnMAs) : (RsReturnMAs) Contains a copy of data returned from req.sec() in case rsRet is set to na for smoothing.
rsRetNaObj (RsReturnMAs) : (RsReturnMAs) An empty object as `na` placeholder
ma1Drawing (MaDrawing) : (MaDrawing) MA drawing properties
ma2Drawing (MaDrawing) : (MaDrawing) MA drawing properties
ma3Drawing (MaDrawing) : (MaDrawing) MA drawing properties
ma4Drawing (MaDrawing) : (MaDrawing) MA drawing properties
ma5Drawing (MaDrawing) : (MaDrawing) MA drawing properties
ma6Drawing (MaDrawing) : (MaDrawing) MA drawing properties
enabled (series bool) : (bool ) Enables/disables all of the MAs of one timeframe.
tf (series string) : (string) Timeframe
showHistory (series bool) : (bool ) Plot MA line on historical bars
rngAtrQ (series int) : (int ) A multiplier for atr(14). Determines a range within which the MA's will be plotted. MA's too far away will not be plotted.
showRecentBars (series int) : (int ) Only plot MA on these recent bars
smoothen (series bool) : (bool ) Smoothen MA plot. If false the same HTF value is returned on all chart bars within a HTF bar (intrabars), so the plot looks like steps.
lblsOffset (series int) : (int ) Show MA name this number of bars to the right off last bar.
lblsShow (series bool) : (bool ) Show MA name
lnOffset (series int) : (int ) Start line showing current level of the MA this number of bars to the right off the last bar.
lblSize (series string) : (string) Label size
lblStyle (series string) : (string) Label style
lblTxtAlign (series string) : (string) Label text align
bPopupLabel (series bool) : (bool ) Show current MA value as a tooltip to MA's name.
LO
LO Library object, whose only purpose is to serve as a shorthand for library name in script code.
Fields:
dummy (series string)