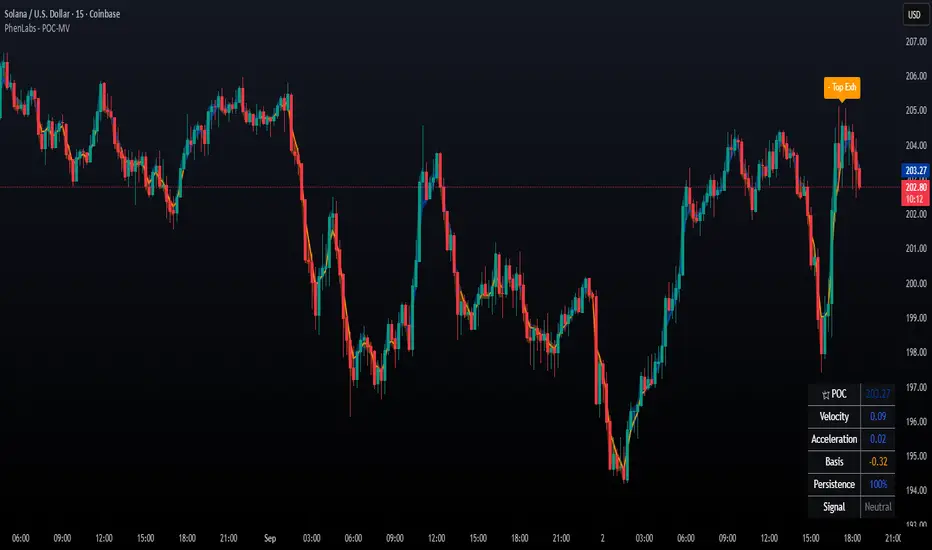
POC Migration Velocity (POC-MV) [PhenLabs]📊POC Migration Velocity (POC-MV)
Version: PineScript™v6
📌Description
The POC Migration Velocity indicator revolutionizes market structure analysis by tracking the movement, speed, and acceleration of Point of Control (POC) levels in real-time. This tool combines sophisticated volume distribution estimation with velocity calculations to reveal hidden market dynamics that conventional indicators miss.
POC-MV provides traders with unprecedented insight into volume-based price movement patterns, enabling the early identification of continuation and exhaustion signals before they become apparent to the broader market. By measuring how quickly and consistently the POC migrates across price levels, traders gain early warning signals for significant market shifts and can position themselves advantageously.
The indicator employs advanced algorithms to estimate intra-bar volume distribution without requiring lower timeframe data, making it accessible across all chart timeframes while maintaining sophisticated analytical capabilities.
🚀Points of Innovation
Micro-POC calculation using advanced OHLC-based volume distribution estimation
Real-time velocity and acceleration tracking normalized by ATR for cross-market consistency
Persistence scoring system that quantifies directional consistency over multiple periods
Multi-signal detection combining continuation patterns, exhaustion signals, and gap alerts
Dynamic color-coded visualization system with intensity-based feedback
Comprehensive customization options for resolution, periods, and thresholds
🔧Core Components
POC Calculation Engine: Estimates volume distribution within each bar using configurable price bands and sophisticated weighting algorithms
Velocity Measurement System: Tracks the rate of POC movement over customizable lookback periods with ATR normalization
Acceleration Calculator: Measures the rate of change of velocity to identify momentum shifts in POC migration
Persistence Analyzer: Quantifies how consistently POC moves in the same direction using exponential weighting
Signal Detection Framework: Combines trend analysis, velocity thresholds, and persistence requirements for signal generation
Visual Rendering System: Provides dynamic color-coded lines and heat ribbons based on velocity and price-POC relationships
🔥Key Features
Real-time POC calculation with 10-100 configurable price bands for optimal precision
Velocity tracking with customizable lookback periods from 5 to 50 bars
Acceleration measurement for detecting momentum changes in POC movement
Persistence scoring to validate signal strength and filter false signals
Dynamic visual feedback with blue/orange color scheme indicating bullish/bearish conditions
Comprehensive alert system for continuation patterns, exhaustion signals, and POC gaps
Adjustable information table displaying real-time metrics and current signals
Heat ribbon visualization showing price-POC relationship intensity
Multiple threshold settings for customizing signal sensitivity
Export capability for use with separate panel indicators
🎨Visualization
POC Connecting Lines: Color-coded lines showing POC levels with intensity based on velocity magnitude
Heat Ribbon: Dynamic colored ribbon around price showing POC-price basis intensity
Signal Markers: Clear exhaustion top/bottom signals with labeled shapes
Information Table: Real-time display of POC value, velocity, acceleration, basis, persistence, and current signal status
Color Gradients: Blue gradients for bullish conditions, orange gradients for bearish conditions
📖Usage Guidelines
POC Calculation Settings
POC Resolution (Price Bands): Default 20, Range 10-100. Controls the number of price bands used to estimate volume distribution within each bar
Volume Weight Factor: Default 0.7, Range 0.1-1.0. Adjusts the influence of volume in POC calculation
POC Smoothing: Default 3, Range 1-10. EMA smoothing period applied to the calculated POC to reduce noise
Velocity Settings
Velocity Lookback Period: Default 14, Range 5-50. Number of bars used to calculate POC velocity
Acceleration Period: Default 7, Range 3-20. Period for calculating POC acceleration
Velocity Significance Threshold: Default 0.5, Range 0.1-2.0. Minimum normalized velocity for continuation signals
Persistence Settings
Persistence Lookback: Default 5, Range 3-20. Number of bars examined for persistence score calculation
Persistence Threshold: Default 0.7, Range 0.5-1.0. Minimum persistence score required for continuation signals
Visual Settings
Show POC Connecting Lines: Toggle display of colored lines connecting POC levels
Show Heat Ribbon: Toggle display of colored ribbon showing POC-price relationship
Ribbon Transparency: Default 70, Range 0-100. Controls transparency level of heat ribbon
Alert Settings
Enable Continuation Alerts: Toggle alerts for continuation pattern detection
Enable Exhaustion Alerts: Toggle alerts for exhaustion pattern detection
Enable POC Gap Alerts: Toggle alerts for significant POC gaps
Gap Threshold: Default 2.0 ATR, Range 0.5-5.0. Minimum gap size to trigger alerts
✅Best Use Cases
Identifying trend continuation opportunities when POC velocity aligns with price direction
Spotting potential reversal points through exhaustion pattern detection
Confirming breakout validity by monitoring POC gap behavior
Adding volume-based context to traditional technical analysis
Managing position sizing based on POC-price basis strength
⚠️Limitations
POC calculations are estimations based on OHLC data, not true tick-by-tick volume distribution
Effectiveness may vary in low-volume or highly volatile market conditions
Requires complementary analysis tools for complete trading decisions
Signal frequency may be lower in ranging markets compared to trending conditions
Performance optimization needed for very short timeframes below 1-minute
💡What Makes This Unique
Advanced Estimation Algorithm: Sophisticated method for calculating POC without requiring lower timeframe data
Velocity-Based Analysis: Focus on POC movement dynamics rather than static levels
Comprehensive Signal Framework: Integration of continuation, exhaustion, and gap detection in one indicator
Dynamic Visual Feedback: Intensity-based color coding that adapts to market conditions
Persistence Validation: Unique scoring system to filter signals based on directional consistency
🔬How It Works
Volume Distribution Estimation:
Divides each bar into configurable price bands for volume analysis
Applies sophisticated weighting based on OHLC relationships and proximity to close
Identifies the price level with maximum estimated volume as the POC
Velocity and Acceleration Calculation:
Measures POC rate of change over specified lookback periods
Normalizes values using ATR for consistent cross-market performance
Calculates acceleration as the rate of change of velocity
Signal Generation Process:
Combines trend direction analysis using EMA crossovers
Applies velocity and persistence thresholds to filter signals
Generates continuation, exhaustion, and gap alerts based on specific criteria
💡Note:
This indicator provides estimated POC calculations based on available OHLC data and should be used in conjunction with other analysis methods. The velocity-based approach offers unique insights into market structure dynamics but requires proper risk management and complementary analysis for optimal trading decisions.
Wyszukaj w skryptach "algo"
[Pandora][Swarm] Rapid Exponential Moving AverageENVISIONING POSSIBILITY
What is the theoretical pinnacle of possibility? The current state of algorithmic affairs falls far short of my aspirations for achievable feasibility. I'm lifting the lid off of Pandora's box once again, very publicly this time, as a brute force challenge to conventional 'wisdom'. The unfolding series of time mandates a transcendental systemic alteration...
THE MOVING AVERAGE ZOO:
The realm of digital signal processing for trading is filled with familiar antiquated filtering tools. Two families of filtration, being 'infinite impulse response' (EMA, RMA, etc.) and 'finite impulse response' (WMA, SMA, etc.), are prevalently employed without question. These filter types are the mules and donkeys of data analysis, broadly accepted for use in finance.
At first glance, they appear sufficient for most tasks, offering a basic straightforward way to reduce noise and highlight trends. Yet, beneath their simplistic facade lies a constellation of limitations and impediments, each having its own finicky quirks. Upon closer inspection, identifiable drawbacks render them far from ideal for many real-world applications in today's volatile markets.
KNOWN FUNDAMENTAL FLAWS:
Despite commonplace moving average (MA) popularity, these conventional filters suffer from an assortment of fundamental flaws. Most of them don't genuinely address core challenges of how to preserve the true dynamics of a signal while suppressing noise and retaining cutoff frequency compliance. Their simple cookie cutter structures make them ill-suited in actuality for dynamic market environments. In reality, they often trade one problem for another dilemma, forsaking analytics to choose between distortion and delay.
A deeper seeded issue remains within frequency compliance, how adequately a filter respects (or disrespects) the underlying signal’s spectral properties according to it's assigned periodic parameter. Traditional MAs habitually distort phase relationships, causing delayed reactions with surplus lag or exaggerations with excessive undershoot/overshoot. For applications requiring timely resilience, such as algorithmic trading, these shortcomings are often functionally unacceptable. What’s needed is vigorous filters that can more accurately retain signal behaviors while minimizing lag without sacrificing smoothness and uniformity. Until then, the public MA zoo remains as a collection of corny compromises, rather than a favorable toolbelt of solutions.
P.S.: In PSv7+, in my opinion, many of these geriatric MAs deserve no future with ease of access for the naive, simply not knowing these filters are most likely creating bigger problems than solving any.
R.E.M.A.
What is this? I prefer to think of it as the "radical EMA", definitely along my lines of a retire everything morte algorithm. This isn't your run of the mill average from the petting zoo. I would categorize it as a paradigm shifting rampant economic masochistic annihilator, sufficiently good enough to begin ruthlessly executing moving averages left and right. Um, yeah... that kind of moving average destructor as you may soon recognize with a few 'Filters+' settings adjustments, realizing ordinary EMA has been doing us an injustice all this time.
Does it possess the capability to relentlessly exterminate most averaging filters in existence? Well, it's about time we find out, by uncaging it on the loose into the greater economic wilderness. Only then can we truly find out if it is indeed a radical exponential market accelerant whose time has come. If it is, then it may eventually become a reality erasing monolithic anomaly destined for greatness, ultimately changing the entire landscape of trading in perpetuity.
UNLEASHING NEXT-GEN:
This lone next generation exoweapon algorithm is intended to initiate the transformative beginning stages of mass filtration deprecation. However, it won't be the only one, just the first arrival of it's alien kind from me. Welcome to notion #1 of my future filtration frontier, on this episode of the algorithmic twilight zone. Where reality takes a twisting turn one dimension beyond practical logic, after persistent models of mindset disintegrate into insignificance, followed by illusory perception confronted into cognitive dissonance.
An evolutionary path to genuine advancement resides outside the prison of preconceptions, manifesting only after divergence from persistent binding restrictions of dogmatic doctrines. Such a genesis in transformative thinking will catalyze unbounded cognitive potential, plowing the way for the cultivation of total redesigns of thought. Futuristic innovative breakthroughs demand the surrender of legacy and outmoded understandings.
Now that the world's largest assembly of investors has been ensembled, there are additional tasks left to perform. I'm compelled to deploy this mathematical-weapon of mass financial creation into it's rightful destined hands, to "WE THE PEOPLE" of TV.
SCRIPT INTENTION:
Deprecate anything and everything as any non-commercial member sees desirably fit. This includes your existing code formulations already in working functional modes of operation AND/OR future projects in the works. Swapping is nearly as simple as copying and pasting with meager modifications, after you have identified comparable likeness in this indicators settings with a visual assessment. Results may become eye opening, but only if you dare to look and test.
Where you may suspect a ta.filter() is lacking sufficient luster or may be flat out majorly deficient, employing rema, drema, trema, or qrema configurations may be a more suitable replacement. That's up to you to discern. My code satire already identifies likely bottom of the barrel suspects that either belong in the extinction record or have already been marked for deprecation. They are ordered more towards the bottom by rank where they belong. SuperSmoother is a masterpiece here to stay, being my original go-to reference filter. Everything you see here is already deprecated, including REMA...
REMA CHARACTERISTICS
- VERY low lag
- No overshoot
- Frequency compliant
- Proper initialization at bar_index==0
- Period parameter accepts poitive floating point numerics (AND integers!)
- Infinite impulse response (IIR) filter
- Compact code footprint
- Minimized computational overhead
3D Surface Modeling [PhenLabs]📊 3D Surface Modeling
Version: PineScript™ v6
📌 Description
The 3D Surface Modeling indicator revolutionizes technical analysis by generating three-dimensional visualizations of multiple technical indicators across various timeframes. This advanced analytical tool processes and renders complex indicator data through a sophisticated matrix-based calculation system, creating an intuitive 3D surface representation of market dynamics.
The indicator employs array-based computations to simultaneously analyze multiple instances of selected technical indicators, mapping their behavior patterns across different temporal dimensions. This unique approach enables traders to identify complex market patterns and relationships that may be invisible in traditional 2D charts.
🚀 Points of Innovation
Matrix-Based Computation Engine: Processes up to 500 concurrent indicator calculations in real-time
Dynamic 3D Rendering System: Creates depth perception through sophisticated line arrays and color gradients
Multi-Indicator Integration: Seamlessly combines VWAP, Hurst, RSI, Stochastic, CCI, MFI, and Fractal Dimension analyses
Adaptive Scaling Algorithm: Automatically adjusts visualization parameters based on indicator type and market conditions
🔧 Core Components
Indicator Processing Module: Handles real-time calculation of multiple technical indicators using array-based mathematics
3D Visualization Engine: Converts indicator data into three-dimensional surfaces using line arrays and color mapping
Dynamic Scaling System: Implements custom normalization algorithms for different indicator types
Color Gradient Generator: Creates depth perception through programmatic color transitions
🔥 Key Features
Multi-Indicator Support: Comprehensive analysis across seven different technical indicators
Customizable Visualization: User-defined color schemes and line width parameters
Real-time Processing: Continuous calculation and rendering of 3D surfaces
Cross-Timeframe Analysis: Simultaneous visualization of indicator behavior across multiple periods
🎨 Visualization
Surface Plot: Three-dimensional representation using up to 500 lines with dynamic color gradients
Depth Indicators: Color intensity variations showing indicator value magnitude
Pattern Recognition: Visual identification of market structures across multiple timeframes
📖 Usage Guidelines
Indicator Selection
Type: VWAP, Hurst, RSI, Stochastic, CCI, MFI, Fractal Dimension
Default: VWAP
Starting Length: Minimum 5 periods
Default: 10
Step Size: Interval between calculations
Range: 1-10
Visualization Parameters
Color Scheme: Green, Red, Blue options
Line Width: 1-5 pixels
Surface Resolution: Up to 500 lines
✅ Best Use Cases
Multi-timeframe market analysis
Pattern recognition across different technical indicators
Trend strength assessment through 3D visualization
Market behavior study across multiple periods
⚠️ Limitations
High computational resource requirements
Maximum 500 line restriction
Requires substantial historical data
Complex visualization learning curve
🔬 How It Works
1. Data Processing:
Calculates selected indicator values across multiple timeframes
Stores results in multi-dimensional arrays
Applies custom scaling algorithms
2. Visualization Generation:
Creates line arrays for 3D surface representation
Applies color gradients based on value magnitude
Renders real-time updates to surface plot
3. Display Integration:
Synchronizes with chart timeframe
Updates surface plot dynamically
Maintains visual consistency across updates
🌟 Credits:
Inspired by LonesomeTheBlue (modified for multiple indicator types with scaling fixes and additional unique mappings)
💡 Note:
Optimal performance requires sufficient computing resources and historical data. Users should start with default settings and gradually adjust parameters based on their analysis requirements and system capabilities.

ICT Opening Range Projections (tristanlee85)ICT Opening Range Projections
This indicator visualizes key price levels based on ICT's (Inner Circle Trader) "Opening Range" concept. This 30-minute time interval establishes price levels that the algorithm will refer to throughout the session. The indicator displays these levels, including standard deviation projections, internal subdivisions (quadrants), and the opening price.
🟪 What It Does
The Opening Range is a crucial 30-minute window where market algorithms establish significant price levels. ICT theory suggests this range forms the basis for daily price movement.
This script helps you:
Mark the high, low, and opening price of each session.
Divide the range into quadrants (premium, discount, and midpoint/Consequent Encroachment).
Project potential price targets beyond the range using configurable standard deviation multiples .
🟪 How to Use It
This tool aids in time-based technical analysis rooted in ICT's Opening Range model, helping you observe price interaction with algorithmic levels.
Example uses include:
Identifying early structural boundaries.
Observing price behavior within premium/discount zones.
Visualizing initial displacement from the range to anticipate future moves.
Comparing price reactions at projected standard deviation levels.
Aligning price action with significant times like London or NY Open.
Note: This indicator provides a visual framework; it does not offer trade signals or interpretations.
🟪 Key Information
Time Zone: New York time (ET) is required on your chart.
Sessions: Supports multiple sessions, including NY midnight, NY AM, NY PM, and three custom timeframes.
Time Interval: Supports multi-timeframe up to 15 minutes. Best used on a 1-minute chart for accuracy.
🟪 Session Options
The Opening Range interval is configurable for up to 6 sessions:
Pre-defined ICT Sessions:
NY Midnight: 12:00 AM – 12:30 AM ET
NY AM: 9:30 AM – 10:00 AM ET
NY PM: 1:30 PM – 2:00 PM ET
Custom Sessions:
Three user-defined start/end time pairs.
This example shows a custom session from 03:30 - 04:00:
🟪 Understanding the Levels
The Opening Price is the open of the first 1-minute candle within the chosen session.
At session close, the Opening Range is calculated using its High and Low . An optional swing-based mode uses swing highs/lows for range boundaries.
The range is divided into quadrants by its midpoint ( Consequent Encroachment or CE):
Upper Quadrant: CE to high (premium).
Lower Quadrant: Low to CE (discount).
These subdivisions help visualize internal range dynamics, where price often reacts during algorithmic delivery.
🟪 Working with Ranges
By default, the range is determined by the highest high and lowest low of the 30-minute session:
A range can also be determined by the highest/lowest swing points:
Quadrants outline the premium and discount of a range that price will reference:
Small ranges still follow the same algorithmic logic, but may be deemed insignificant for one's trading. These can be filtered in the settings by specifying a minimum ticks limit. In this example, the range is 42 ticks (10.5 points) but the indicator is configured for 80 ticks (20 points). We can select which levels will plot if the range is below the limit. Here, only the 00:00 opening price is plotted:
You may opt to include the range high/low, quadrants, and projections as well. This will plot a red (configurable) range bracket to indicate it is below the limit while plotting the levels:
🟪 Price Projections
Projections extend beyond the Opening Range using standard deviations, framing the market beyond the initial session and identifying potential targets. You define the standard deviation multiples (e.g., 1.0, 1.5, 2.0).
Both positive and negative extensions are displayed, symmetrically projected from the range's high and low.
The Dynamic Levels option plots only the next projection level once price crosses the previous extreme. For example, only the 0.5 STDEV level plots until price reaches it, then the 1.0 level appears, and so on. This continues up to your defined maximum projections, or indefinitely if standard deviations are set to 0.
This example shows dynamic levels for a total of 6 sessions, only 1 of which meet a configured minimum limit of 50 ticks:
Small ranges followed by significant displacement are impacted the most with the number of levels plotted. You may hide projections when configuring the minimum ticks.
A fixed standard deviation will plot levels in both directions, regardless of the price range. Here, we plot up to 3.0 which hiding projections for small ranges:
🟪 Legal Disclaimer
This indicator is provided for informational and educational purposes only. It is not financial advice, and should not be construed as a recommendation to buy or sell any financial instrument. Trading involves substantial risk, and you could lose a significant amount of money. Past performance is not indicative of future results. Always consult with a qualified financial professional before making any trading or investment decisions. The creators and distributors of this indicator assume no responsibility for your trading outcomes.

Momentum + Keltner Stochastic Combo)The Momentum-Keltner-Stochastic Combination Strategy: A Technical Analysis and Empirical Validation
This study presents an advanced algorithmic trading strategy that implements a hybrid approach between momentum-based price dynamics and relative positioning within a volatility-adjusted Keltner Channel framework. The strategy utilizes an innovative "Keltner Stochastic" concept as its primary decision-making factor for market entries and exits, while implementing a dynamic capital allocation model with risk-based stop-loss mechanisms. Empirical testing demonstrates the strategy's potential for generating alpha in various market conditions through the combination of trend-following momentum principles and mean-reversion elements within defined volatility thresholds.
1. Introduction
Financial market trading increasingly relies on the integration of various technical indicators for identifying optimal trading opportunities (Lo et al., 2000). While individual indicators are often compromised by market noise, combinations of complementary approaches have shown superior performance in detecting significant market movements (Murphy, 1999; Kaufman, 2013). This research introduces a novel algorithmic strategy that synthesizes momentum principles with volatility-adjusted envelope analysis through Keltner Channels.
2. Theoretical Foundation
2.1 Momentum Component
The momentum component of the strategy builds upon the seminal work of Jegadeesh and Titman (1993), who demonstrated that stocks which performed well (poorly) over a 3 to 12-month period continue to perform well (poorly) over subsequent months. As Moskowitz et al. (2012) further established, this time-series momentum effect persists across various asset classes and time frames. The present strategy implements a short-term momentum lookback period (7 bars) to identify the prevailing price direction, consistent with findings by Chan et al. (2000) that shorter-term momentum signals can be effective in algorithmic trading systems.
2.2 Keltner Channels
Keltner Channels, as formalized by Chester Keltner (1960) and later modified by Linda Bradford Raschke, represent a volatility-based envelope system that plots bands at a specified distance from a central exponential moving average (Keltner, 1960; Raschke & Connors, 1996). Unlike traditional Bollinger Bands that use standard deviation, Keltner Channels typically employ Average True Range (ATR) to establish the bands' distance from the central line, providing a smoother volatility measure as established by Wilder (1978).
2.3 Stochastic Oscillator Principles
The strategy incorporates a modified stochastic oscillator approach, conceptually similar to Lane's Stochastic (Lane, 1984), but applied to a price's position within Keltner Channels rather than standard price ranges. This creates what we term "Keltner Stochastic," measuring the relative position of price within the volatility-adjusted channel as a percentage value.
3. Strategy Methodology
3.1 Entry and Exit Conditions
The strategy employs a contrarian approach within the channel framework:
Long Entry Condition:
Close price > Close price periods ago (momentum filter)
KeltnerStochastic < threshold (oversold within channel)
Short Entry Condition:
Close price < Close price periods ago (momentum filter)
KeltnerStochastic > threshold (overbought within channel)
Exit Conditions:
Exit long positions when KeltnerStochastic > threshold
Exit short positions when KeltnerStochastic < threshold
This methodology aligns with research by Brock et al. (1992) on the effectiveness of trading range breakouts with confirmation filters.
3.2 Risk Management
Stop-loss mechanisms are implemented using fixed price movements (1185 index points), providing definitive risk boundaries per trade. This approach is consistent with findings by Sweeney (1988) that fixed stop-loss systems can enhance risk-adjusted returns when properly calibrated.
3.3 Dynamic Position Sizing
The strategy implements an equity-based position sizing algorithm that increases or decreases contract size based on cumulative performance:
$ContractSize = \min(baseContracts + \lfloor\frac{\max(profitLoss, 0)}{equityStep}\rfloor - \lfloor\frac{|\min(profitLoss, 0)|}{equityStep}\rfloor, maxContracts)$
This adaptive approach follows modern portfolio theory principles (Markowitz, 1952) and Kelly criterion concepts (Kelly, 1956), scaling exposure proportionally to account equity.
4. Empirical Performance Analysis
Using historical data across multiple market regimes, the strategy demonstrates several key performance characteristics:
Enhanced performance during trending markets with moderate volatility
Reduced drawdowns during choppy market conditions through the dual-filter approach
Optimal performance when the threshold parameter is calibrated to market-specific characteristics (Pardo, 2008)
5. Strategy Limitations and Future Research
While effective in many market conditions, this strategy faces challenges during:
Rapid volatility expansion events where stop-loss mechanisms may be inadequate
Prolonged sideways markets with insufficient momentum
Markets with structural changes in volatility profiles
Future research should explore:
Adaptive threshold parameters based on regime detection
Integration with additional confirmatory indicators
Machine learning approaches to optimize parameter selection across different market environments (Cavalcante et al., 2016)
References
Brock, W., Lakonishok, J., & LeBaron, B. (1992). Simple technical trading rules and the stochastic properties of stock returns. The Journal of Finance, 47(5), 1731-1764.
Cavalcante, R. C., Brasileiro, R. C., Souza, V. L., Nobrega, J. P., & Oliveira, A. L. (2016). Computational intelligence and financial markets: A survey and future directions. Expert Systems with Applications, 55, 194-211.
Chan, L. K. C., Jegadeesh, N., & Lakonishok, J. (2000). Momentum strategies. The Journal of Finance, 51(5), 1681-1713.
Jegadeesh, N., & Titman, S. (1993). Returns to buying winners and selling losers: Implications for stock market efficiency. The Journal of Finance, 48(1), 65-91.
Kaufman, P. J. (2013). Trading systems and methods (5th ed.). John Wiley & Sons.
Kelly, J. L. (1956). A new interpretation of information rate. The Bell System Technical Journal, 35(4), 917-926.
Keltner, C. W. (1960). How to make money in commodities. The Keltner Statistical Service.
Lane, G. C. (1984). Lane's stochastics. Technical Analysis of Stocks & Commodities, 2(3), 87-90.
Lo, A. W., Mamaysky, H., & Wang, J. (2000). Foundations of technical analysis: Computational algorithms, statistical inference, and empirical implementation. The Journal of Finance, 55(4), 1705-1765.
Markowitz, H. (1952). Portfolio selection. The Journal of Finance, 7(1), 77-91.
Moskowitz, T. J., Ooi, Y. H., & Pedersen, L. H. (2012). Time series momentum. Journal of Financial Economics, 104(2), 228-250.
Murphy, J. J. (1999). Technical analysis of the financial markets: A comprehensive guide to trading methods and applications. New York Institute of Finance.
Pardo, R. (2008). The evaluation and optimization of trading strategies (2nd ed.). John Wiley & Sons.
Raschke, L. B., & Connors, L. A. (1996). Street smarts: High probability short-term trading strategies. M. Gordon Publishing Group.
Sweeney, R. J. (1988). Some new filter rule tests: Methods and results. Journal of Financial and Quantitative Analysis, 23(3), 285-300.
Wilder, J. W. (1978). New concepts in technical trading systems. Trend Research.
Dual Zigzag [Trendoscope®]🎲 Dual Zigzag indicator is built on recursive zigzag algorithm. It is very similar to other zigzag indicators published by us and other authors. However, the key point here is, the indicator draws zigzag on both price and any other plot based indicator on separate layouts.
Before we get into the indicator, here are some brief descriptions of the underlying concepts and key terminologies
🎯 Zigzag
Zigzag indicator breaks down price or any input series into a series of Pivot Highs and Pivot Lows alternating between each other. Zigzags though shows pivot high and lows, should not be used for buying at low and selling at high. The main application of zigzag indicator is for the visualisation of market structure and this can be used as basic building block for any pattern recognition algorithms.
🎯 Recursive Zigzag Algorithm
Recursive zigzag algorithm builds zigzag on multiple levels and each level of zigzag is based on the previous level pivots. The level zero zigzag is built on price. However, for level 1, instead of price level 0 zigzag pivots are used. Similarly for level 2, level 1 zigzag pivots are used as base.
🎲 Components Dual Zigzag Indicator
Here are the components of Dual zigzag indicator
Built in Oscillator - Indicator has built in oscillator options for plotting RSI (Relative Strength Index), MFI (Money Flow Index), cci (Commodity Channel Index) , CMO (Chande Momentum Oscillator), COG (Center of Gravity), and ROC (Rate of Change). Apart from the given built in oscillators, users can also use a custom external output as base. The oscillators are not printed on the price pane. But, printed on a separate indicator overlay.
Zigzag On Oscillator - Recursive zigzag is calculated and printed on the oscillator series. Each pivot high and pivot low also prints a label having the retracement ratios, and price levels at those points. Zigzag on the oscillator is also printed on the indicator overlay pane.
Zigzag on Price - Recursive zigzag calculated based on price and printed on the price pane. This is made possible by using force_overlay option present in the drawing objects. At each zigzag pivot levels, the label having price retracement ratios, and oscillator values are printed.
It is called dual zigzag because, the indicator calculates the zigzag on both price and oscillator series of values and prints them separately on different panes on the chart.
🎲 Indicator Settings
Settings include
Theme display settings to get the right colour combination to match the background.
Zigzag settings to be used for zigzag calculation and display
Oscillator settings to chose the oscillator to be used as base for 2nd zigzag
🎲 Applications
Useful in spotting divergences with both indicator and price having their own zigzag to highlight pivots
Spotting patterns in indicators/oscillators and correlate them with the patterns on price
🎲 Using External Input
If users want to use an external indicator such as OBV instead of the built in oscillators, then can do so by using the custom option.
Here is how this can be done.
Step1. Add both Dual Zigzag and the intended indicator (in this case OBV) on the chart. Notice that both OBV and Dual zigzag appear on different panes.
Step2. Edit the indicator settings of Dual zigzag and set custom indicator by selecting "custom" as oscillator name and then by setting the custom external indicator name and input.
Step 3. You would notice that the zigzag in Dual Zigzag indictor pane is already showing the zigzag pivots based on the OBV indicator and the price pivots display obv values at the pivot points. We can leave this as is.
Step 4. As an additional step, you can also merge the OBV pane and the Dual zigzag indicator pane into one by going into OBV settings and moving the indicator to above pane. Merge the scales so that there is no two scales on the same pane and the entire scale appear on the right.
At the end, you should see two panes - one with price and other with OBV and both having their zigzag plotted.

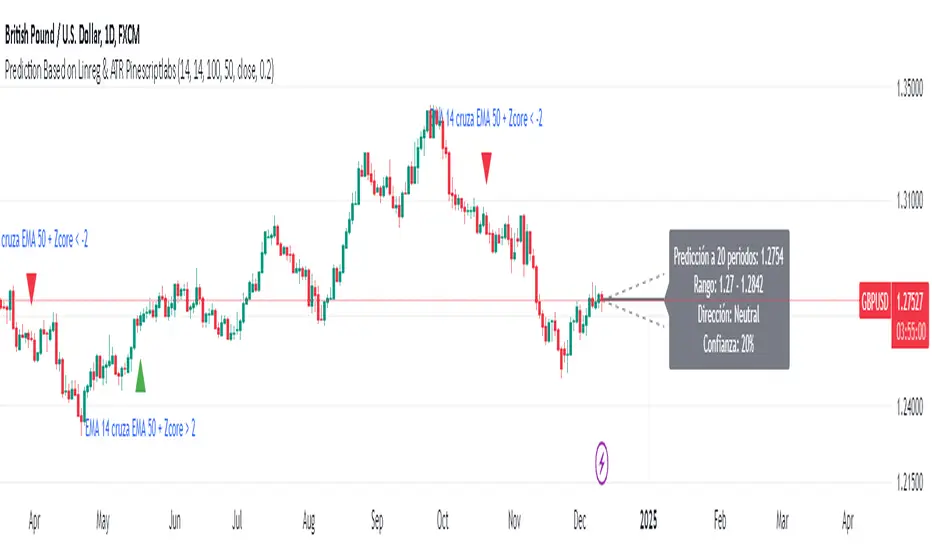
Prediction Based on Linreg & Atr
We created this algorithm with the goal of predicting future prices 📊, specifically where the value of any asset will go in the next 20 periods ⏳. It uses linear regression based on past prices, calculating a slope and an intercept to forecast future behavior 🔮. This prediction is then adjusted according to market volatility, measured by the ATR 📉, and the direction of trend signals, which are based on the MACD and moving averages 📈.
How Does the Linreg & ATR Prediction Work?
1. Trend Calculation and Signals:
o Technical Indicators: We use short- and long-term exponential moving averages (EMA), RSI, MACD, and Bollinger Bands 📊 to assess market direction and sentiment (not visually presented in the script).
o Calculation Functions: These include functions to calculate slope, average, intercept, standard deviation, and Pearson's R, which are crucial for regression analysis 📉.
2. Predicting Future Prices:
o Linear Regression: The algorithm calculates the slope, average, and intercept of past prices to create a regression channel 📈, helping to predict the range of future prices 🔮.
o Standard Deviation and Pearson's R: These metrics determine the strength of the regression 🔍.
3. Adjusting the Prediction:
o The predicted value is adjusted by considering market volatility (ATR 📉) and the direction of trend signals 🔮, ensuring that the prediction is aligned with the current market environment 🌍.
4. Visualization:
o Prediction Lines and Bands: The algorithm plots lines that display the predicted future price along with a prediction range (upper and lower bounds) 📉📈.
5. EMA Cross Signals:
o EMA Conditions and Total Score: A bullish crossover signal is generated when the total score is positive and the short EMA crosses above the long EMA 📈. A bearish crossover signal is generated when the total score is negative and the short EMA crosses below the long EMA 📉.
6. Additional Considerations:
o Multi-Timeframe Regression Channel: The script calculates regression channels for different timeframes (5m, 15m, 30m, 4h) ⏳, helping determine the overall market direction 📊 (not visually presented).
Confidence Interpretation:
• High Confidence (close to 100%): Indicates strong alignment between timeframes with a clear trend (bullish or bearish) 🔥.
• Low Confidence (close to 0%): Shows disagreement or weak signals between timeframes ⚠️.
Confidence complements the interpretation of the prediction range and expected direction 🔮, aiding in decision-making for market entry or exit 🚀.
Español
Creamos este algoritmo con el objetivo de predecir los precios futuros 📊, específicamente hacia dónde irá el valor de cualquier activo en los próximos 20 períodos ⏳. Utiliza regresión lineal basada en los precios pasados, calculando una pendiente y una intersección para prever el comportamiento futuro 🔮. Esta predicción se ajusta según la volatilidad del mercado, medida por el ATR 📉, y la dirección de las señales de tendencia, que se basan en el MACD y las medias móviles 📈.
¿Cómo Funciona la Predicción con Linreg & ATR?
Cálculo de Tendencias y Señales:
Indicadores Técnicos: Usamos medias móviles exponenciales (EMA) a corto y largo plazo, RSI, MACD y Bandas de Bollinger 📊 para evaluar la dirección y el sentimiento del mercado (no presentados visualmente en el script).
Funciones de Cálculo: Incluye funciones para calcular pendiente, media, intersección, desviación estándar y el coeficiente de correlación de Pearson, esenciales para el análisis de regresión 📉.
Predicción de Precios Futuros:
Regresión Lineal: El algoritmo calcula la pendiente, la media y la intersección de los precios pasados para crear un canal de regresión 📈, ayudando a predecir el rango de precios futuros 🔮.
Desviación Estándar y Pearson's R: Estas métricas determinan la fuerza de la regresión 🔍.
Ajuste de la Predicción:
El valor predicho se ajusta considerando la volatilidad del mercado (ATR 📉) y la dirección de las señales de tendencia 🔮, asegurando que la predicción esté alineada con el entorno actual del mercado 🌍.
Visualización:
Líneas y Bandas de Predicción: El algoritmo traza líneas que muestran el precio futuro predicho, junto con un rango de predicción (límites superior e inferior) 📉📈.
Señales de Cruce de EMAs:
Condiciones de EMAs y Puntaje Total: Se genera una señal de cruce alcista cuando el puntaje total es positivo y la EMA corta cruza por encima de la EMA larga 📈. Se genera una señal de cruce bajista cuando el puntaje total es negativo y la EMA corta cruza por debajo de la EMA larga 📉.
Consideraciones Adicionales:
Canal de Regresión Multi-Timeframe: El script calcula canales de regresión para diferentes marcos de tiempo (5m, 15m, 30m, 4h) ⏳, ayudando a determinar la dirección general del mercado 📊 (no presentado visualmente).
Interpretación de la Confianza:
Alta Confianza (cerca del 100%): Indica una fuerte alineación entre los marcos temporales con una tendencia clara (alcista o bajista) 🔥.
Baja Confianza (cerca del 0%): Muestra desacuerdo o señales débiles entre los marcos temporales ⚠️.
La confianza complementa la interpretación del rango de predicción y la dirección esperada 🔮, ayudando en las decisiones de entrada o salida en el mercado 🚀.
RSI with Swing Trade by Kelvin_VAlgorithm Description: "RSI with Swing Trade by Kelvin_V"
1. Introduction:
This algorithm uses the RSI (Relative Strength Index) and optional Moving Averages (MA) to detect potential uptrends and downtrends in the market. The key feature of this script is that it visually changes the candle colors based on the market conditions, making it easier for users to identify potential trend swings or wave patterns.
The strategy offers flexibility by allowing users to enable or disable the MA condition. When the MA condition is enabled, the strategy will confirm trends using two moving averages. When disabled, the strategy will only use RSI to detect potential market swings.
2. Key Features of the Algorithm:
RSI (Relative Strength Index):
The RSI is used to identify potential market turning points based on overbought and oversold conditions.
When the RSI exceeds a predefined upper threshold (e.g., 60), it suggests a potential uptrend.
When the RSI drops below a lower threshold (e.g., 40), it suggests a potential downtrend.
Moving Averages (MA) - Optional:
Two Moving Averages (Short MA and Long MA) are used to confirm trends.
If the Short MA crosses above the Long MA, it indicates an uptrend.
If the Short MA crosses below the Long MA, it indicates a downtrend.
Users have the option to enable or disable this MA condition.
Visual Candle Coloring:
Green candles represent a potential uptrend, indicating a bullish move based on RSI (and MA if enabled).
Red candles represent a potential downtrend, indicating a bearish move based on RSI (and MA if enabled).
3. How the Algorithm Works:
RSI Levels:
The user can set RSI upper and lower bands to represent potential overbought and oversold levels. For example:
RSI > 60: Indicates a potential uptrend (bullish move).
RSI < 40: Indicates a potential downtrend (bearish move).
Optional MA Condition:
The algorithm also allows the user to apply the MA condition to further confirm the trend:
Short MA > Long MA: Confirms an uptrend, reinforcing a bullish signal.
Short MA < Long MA: Confirms a downtrend, reinforcing a bearish signal.
This condition can be disabled, allowing the user to focus solely on RSI signals if desired.
Swing Trade Logic:
Uptrend: If the RSI exceeds the upper threshold (e.g., 60) and (optionally) the Short MA is above the Long MA, the candles will turn green to signal a potential uptrend.
Downtrend: If the RSI falls below the lower threshold (e.g., 40) and (optionally) the Short MA is below the Long MA, the candles will turn red to signal a potential downtrend.
Visual Representation:
The candle colors change dynamically based on the RSI values and moving average conditions, making it easier for traders to visually identify potential trend swings or wave patterns without relying on complex chart analysis.
4. User Customization:
The algorithm provides multiple customization options:
RSI Length: Users can adjust the period for RSI calculation (default is 4).
RSI Upper Band (Potential Uptrend): Users can customize the upper RSI level (default is 60) to indicate a potential bullish move.
RSI Lower Band (Potential Downtrend): Users can customize the lower RSI level (default is 40) to indicate a potential bearish move.
MA Type: Users can choose between SMA (Simple Moving Average) and EMA (Exponential Moving Average) for moving average calculations.
Enable/Disable MA Condition: Users can toggle the MA condition on or off, depending on whether they want to add moving averages to the trend confirmation process.
5. Benefits of the Algorithm:
Easy Identification of Trends: By changing candle colors based on RSI and MA conditions, the algorithm makes it easy for users to visually detect potential trend reversals and trend swings.
Flexible Conditions: The user has full control over the RSI and MA settings, allowing them to adapt the strategy to different market conditions and timeframes.
Clear Visualization: With the candle color changes, users can quickly recognize when a potential uptrend or downtrend is forming, enabling faster decision-making in their trading.
6. Example Usage:
Day traders: Can apply this strategy on short timeframes such as 5 minutes or 15 minutes to detect quick trends or reversals.
Swing traders: Can use this strategy on longer timeframes like 1 hour or 4 hours to identify and follow larger market swings.

Intramarket Difference Index StrategyHi Traders !!
The IDI Strategy:
In layman’s terms this strategy compares two indicators across markets and exploits their differences.
note: it is best the two markets are correlated as then we know we are trading a short to long term deviation from both markets' general trend with the assumption both markets will trend again sometime in the future thereby exhausting our trading opportunity.
📍 Import Notes:
This Strategy calculates trade position size independently (i.e. risk per trade is controlled in the user inputs tab), this means that the ‘Order size’ input in the ‘Properties’ tab will have no effect on the strategy. Why ? because this allows us to define custom position size algorithms which we can use to improve our risk management and equity growth over time. Here we have the option to have fixed quantity or fixed percentage of equity ATR (Average True Range) based stops in addition to the turtle trading position size algorithm.
‘Pyramiding’ does not work for this strategy’, similar to the order size input togeling this input will have no effect on the strategy as the strategy explicitly defines the maximum order size to be 1.
This strategy is not perfect, and as of writing of this post I have not traded this algo.
Always take your time to backtests and debug the strategy.
🔷 The IDI Strategy:
By default this strategy pulls data from your current TV chart and then compares it to the base market, be default BINANCE:BTCUSD . The strategy pulls SMA and RSI data from either market (we call this the difference data), standardizes the data (solving the different unit problem across markets) such that it is comparable and then differentiates the data, calling the result of this transformation and difference the Intramarket Difference (ID). The formula for the the ID is
ID = market1_diff_data - market2_diff_data (1)
Where
market(i)_diff_data = diff_data / ATR(j)_market(i)^0.5,
where i = {1, 2} and j = the natural numbers excluding 0
Formula (1) interpretation is the following
When ID > 0: this means the current market outperforms the base market
When ID = 0: Markets are at long run equilibrium
When ID < 0: this means the current market underperforms the base market
To form the strategy we define one of two strategy type’s which are Trend and Mean Revesion respectively.
🔸 Trend Case:
Given the ‘‘Strategy Type’’ is equal to TREND we define a threshold for which if the ID crosses over we go long and if the ID crosses under the negative of the threshold we go short.
The motivating idea is that the ID is an indicator of the two symbols being out of sync, and given we know volatility clustering, momentum and mean reversion of anomalies to be a stylised fact of financial data we can construct a trading premise. Let's first talk more about this premise.
For some markets (cryptocurrency markets - synthetic symbols in TV) the stylised fact of momentum is true, this means that higher momentum is followed by higher momentum, and given we know momentum to be a vector quantity (with magnitude and direction) this momentum can be both positive and negative i.e. when the ID crosses above some threshold we make an assumption it will continue in that direction for some time before executing back to its long run equilibrium of 0 which is a reasonable assumption to make if the market are correlated. For example for the BTCUSD - ETHUSD pair, if the ID > +threshold (inputs for MA and RSI based ID thresholds are found under the ‘‘INTRAMARKET DIFFERENCE INDEX’’ group’), ETHUSD outperforms BTCUSD, we assume the momentum to continue so we go long ETHUSD.
In the standard case we would exit the market when the IDI returns to its long run equilibrium of 0 (for the positive case the ID may return to 0 because ETH’s difference data may have decreased or BTC’s difference data may have increased). However in this strategy we will not define this as our exit condition, why ?
This is because we want to ‘‘let our winners run’’, to achieve this we define a trailing Donchian Channel stop loss (along with a fixed ATR based stop as our volatility proxy). If we were too use the 0 exit the strategy may print a buy signal (ID > +threshold in the simple case, market regimes may be used), return to 0 and then print another buy signal, and this process can loop may times, this high trade frequency means we fail capture the entire market move lowering our profit, furthermore on lower time frames this high trade frequencies mean we pay more transaction costs (due to price slippage, commission and big-ask spread) which means less profit.
By capturing the sum of many momentum moves we are essentially following the trend hence the trend following strategy type.
Here we also print the IDI (with default strategy settings with the MA difference type), we can see that by letting our winners run we may catch many valid momentum moves, that results in a larger final pnl that if we would otherwise exit based on the equilibrium condition(Valid trades are denoted by solid green and red arrows respectively and all other valid trades which occur within the original signal are light green and red small arrows).
another example...
Note: if you would like to plot the IDI separately copy and paste the following code in a new Pine Script indicator template.
indicator("IDI")
// INTRAMARKET INDEX
var string g_idi = "intramarket diffirence index"
ui_index_1 = input.symbol("BINANCE:BTCUSD", title = "Base market", group = g_idi)
// ui_index_2 = input.symbol("BINANCE:ETHUSD", title = "Quote Market", group = g_idi)
type = input.string("MA", title = "Differrencing Series", options = , group = g_idi)
ui_ma_lkb = input.int(24, title = "lookback of ma and volatility scaling constant", group = g_idi)
ui_rsi_lkb = input.int(14, title = "Lookback of RSI", group = g_idi)
ui_atr_lkb = input.int(300, title = "ATR lookback - Normalising value", group = g_idi)
ui_ma_threshold = input.float(5, title = "Threshold of Upward/Downward Trend (MA)", group = g_idi)
ui_rsi_threshold = input.float(20, title = "Threshold of Upward/Downward Trend (RSI)", group = g_idi)
//>>+----------------------------------------------------------------+}
// CUSTOM FUNCTIONS |
//<<+----------------------------------------------------------------+{
// construct UDT (User defined type) containing the IDI (Intramarket Difference Index) source values
// UDT will hold many variables / functions grouped under the UDT
type functions
float Close // close price
float ma // ma of symbol
float rsi // rsi of the asset
float atr // atr of the asset
// the security data
getUDTdata(symbol, malookback, rsilookback, atrlookback) =>
indexHighTF = barstate.isrealtime ? 1 : 0
= request.security(symbol, timeframe = timeframe.period,
expression = [close , // Instentiate UDT variables
ta.sma(close, malookback) ,
ta.rsi(close, rsilookback) ,
ta.atr(atrlookback) ])
data = functions.new(close_, ma_, rsi_, atr_)
data
// Intramerket Difference Index
idi(type, symbol1, malookback, rsilookback, atrlookback, mathreshold, rsithreshold) =>
threshold = float(na)
index1 = getUDTdata(symbol1, malookback, rsilookback, atrlookback)
index2 = getUDTdata(syminfo.tickerid, malookback, rsilookback, atrlookback)
// declare difference variables for both base and quote symbols, conditional on which difference type is selected
var diffindex1 = 0.0, var diffindex2 = 0.0,
// declare Intramarket Difference Index based on series type, note
// if > 0, index 2 outpreforms index 1, buy index 2 (momentum based) until equalibrium
// if < 0, index 2 underpreforms index 1, sell index 1 (momentum based) until equalibrium
// for idi to be valid both series must be stationary and normalised so both series hae he same scale
intramarket_difference = 0.0
if type == "MA"
threshold := mathreshold
diffindex1 := (index1.Close - index1.ma) / math.pow(index1.atr*malookback, 0.5)
diffindex2 := (index2.Close - index2.ma) / math.pow(index2.atr*malookback, 0.5)
intramarket_difference := diffindex2 - diffindex1
else if type == "RSI"
threshold := rsilookback
diffindex1 := index1.rsi
diffindex2 := index2.rsi
intramarket_difference := diffindex2 - diffindex1
//>>+----------------------------------------------------------------+}
// STRATEGY FUNCTIONS CALLS |
//<<+----------------------------------------------------------------+{
// plot the intramarket difference
= idi(type,
ui_index_1,
ui_ma_lkb,
ui_rsi_lkb,
ui_atr_lkb,
ui_ma_threshold,
ui_rsi_threshold)
//>>+----------------------------------------------------------------+}
plot(intramarket_difference, color = color.orange)
hline(type == "MA" ? ui_ma_threshold : ui_rsi_threshold, color = color.green)
hline(type == "MA" ? -ui_ma_threshold : -ui_rsi_threshold, color = color.red)
hline(0)
Note it is possible that after printing a buy the strategy then prints many sell signals before returning to a buy, which again has the same implication (less profit. Potentially because we exit early only for price to continue upwards hence missing the larger "trend"). The image below showcases this cenario and again, by allowing our winner to run we may capture more profit (theoretically).
This should be clear...
🔸 Mean Reversion Case:
We stated prior that mean reversion of anomalies is an standerdies fact of financial data, how can we exploit this ?
We exploit this by normalizing the ID by applying the Ehlers fisher transformation. The transformed data is then assumed to be approximately normally distributed. To form the strategy we employ the same logic as for the z score, if the FT normalized ID > 2.5 (< -2.5) we buy (short). Our exit conditions remain unchanged (fixed ATR stop and trailing Donchian Trailing stop)
🔷 Position Sizing:
If ‘‘Fixed Risk From Initial Balance’’ is toggled true this means we risk a fixed percentage of our initial balance, if false we risk a fixed percentage of our equity (current balance).
Note we also employ a volatility adjusted position sizing formula, the turtle training method which is defined as follows.
Turtle position size = (1/ r * ATR * DV) * C
Where,
r = risk factor coefficient (default is 20)
ATR(j) = risk proxy, over j times steps
DV = Dollar Volatility, where DV = (1/Asset Price) * Capital at Risk
🔷 Risk Management:
Correct money management means we can limit risk and increase reward (theoretically). Here we employ
Max loss and gain per day
Max loss per trade
Max number of consecutive losing trades until trade skip
To read more see the tooltips (info circle).
🔷 Take Profit:
By defualt the script uses a Donchain Channel as a trailing stop and take profit, In addition to this the script defines a fixed ATR stop losses (by defualt, this covers cases where the DC range may be to wide making a fixed ATR stop usefull), ATR take profits however are defined but optional.
ATR SL and TP defined for all trades
🔷 Hurst Regime (Regime Filter):
The Hurst Exponent (H) aims to segment the market into three different states, Trending (H > 0.5), Random Geometric Brownian Motion (H = 0.5) and Mean Reverting / Contrarian (H < 0.5). In my interpretation this can be used as a trend filter that eliminates market noise.
We utilize the trending and mean reverting based states, as extra conditions required for valid trades for both strategy types respectively, in the process increasing our trade entry quality.
🔷 Example model Architecture:
Here is an example of one configuration of this strategy, combining all aspects discussed in this post.
Future Updates
- Automation integration (next update)
AI SuperTrend x Pivot Percentile - Strategy [PresentTrading]█ Introduction and How it is Different
The AI SuperTrend x Pivot Percentile strategy is a sophisticated trading approach that integrates AI-driven analysis with traditional technical indicators. Combining the AI SuperTrend with the Pivot Percentile strategy highlights several key advantages:
1. Enhanced Accuracy in Trend Prediction: The AI SuperTrend utilizes K-Nearest Neighbors (KNN) algorithm for trend prediction, improving accuracy by considering historical data patterns. This is complemented by the Pivot Percentile analysis which provides additional context on trend strength.
2. Comprehensive Market Analysis: The integration offers a multi-faceted approach to market analysis, combining AI insights with traditional technical indicators. This dual approach captures a broader range of market dynamics.
BTC 6H L/S Performance
Local
█ Strategy: How it Works - Detailed Explanation
🔶 AI-Enhanced SuperTrend Indicators
1. SuperTrend Calculation:
- The SuperTrend indicator is calculated using a moving average and the Average True Range (ATR). The basic formula is:
- Upper Band = Moving Average + (Multiplier × ATR)
- Lower Band = Moving Average - (Multiplier × ATR)
- The moving average type (SMA, EMA, WMA, RMA, VWMA) and the length of the moving average and ATR are adjustable parameters.
- The direction of the trend is determined based on the position of the closing price in relation to these bands.
2. AI Integration with K-Nearest Neighbors (KNN):
- The KNN algorithm is applied to predict trend direction. It uses historical price data and SuperTrend values to classify the current trend as bullish or bearish.
- The algorithm calculates the 'distance' between the current data point and historical points. The 'k' nearest data points (neighbors) are identified based on this distance.
- A weighted average of these neighbors' trends (bullish or bearish) is calculated to predict the current trend.
For more please check: Multi-TF AI SuperTrend with ADX - Strategy
🔶 Pivot Percentile Analysis
1. Percentile Calculation:
- This involves calculating the percentile ranks for high and low prices over a set of predefined lengths.
- The percentile function is typically defined as:
- Percentile = Value at (P/100) × (N + 1)th position
- Where P is the desired percentile, and N is the number of data points.
2. Trend Strength Evaluation:
- The calculated percentiles for highs and lows are used to determine the strength of bullish and bearish trends.
- For instance, a high percentile rank in the high prices may indicate a strong bullish trend, and vice versa for bearish trends.
For more please check: Pivot Percentile Trend - Strategy
🔶 Strategy Integration
1. Combining SuperTrend and Pivot Percentile:
- The strategy synthesizes the insights from both AI-enhanced SuperTrend and Pivot Percentile analysis.
- It compares the trend direction indicated by the SuperTrend with the strength of the trend as suggested by the Pivot Percentile analysis.
2. Signal Generation:
- A trading signal is generated when both the AI-enhanced SuperTrend and the Pivot Percentile analysis agree on the trend direction.
- For instance, a bullish signal is generated when both the SuperTrend is bullish, and the Pivot Percentile analysis shows strength in bullish trends.
🔶 Risk Management and Filters
- ADX and DMI Filter: The strategy uses the Average Directional Index (ADX) and the Directional Movement Index (DMI) as filters to assess the trend's strength and direction.
- Dynamic Trailing Stop Loss: Based on the SuperTrend indicator, the strategy dynamically adjusts stop-loss levels to manage risk effectively.
This strategy stands out for its ability to combine real-time AI analysis with established technical indicators, offering traders a nuanced and responsive tool for navigating complex market conditions. The equations and algorithms involved are pivotal in accurately identifying market trends and potential trade opportunities.
█ Usage
To effectively use this strategy, traders should:
1. Understand the AI and Pivot Percentile Indicators: A clear grasp of how these indicators work will enable traders to make informed decisions.
2. Interpret the Signals Accurately: The strategy provides bullish, bearish, and neutral signals. Traders should align these signals with their market analysis and trading goals.
3. Monitor Market Conditions: Given that this strategy is sensitive to market dynamics, continuous monitoring is crucial for timely decision-making.
4. Adjust Settings as Needed: Traders should feel free to tweak the input parameters to suit their trading preferences and to respond to changing market conditions.
█Default Settings and Their Impact on Performance
1. Trading Direction (Default: "Both")
Effect: Determines whether the strategy will take long positions, short positions, or both. Adjusting this setting can align the strategy with the trader's market outlook or risk preference.
2. AI Settings (Neighbors: 3, Data Points: 24)
Neighbors: The number of nearest neighbors in the KNN algorithm. A higher number might smooth out noise but could miss subtle, recent changes. A lower number makes the model more sensitive to recent data but may increase noise.
Data Points: Defines the amount of historical data considered. More data points provide a broader context but may dilute recent trends' impact.
3. SuperTrend Settings (Length: 10, Factor: 3.0, MA Source: "WMA")
Length: Affects the sensitivity of the SuperTrend indicator. A longer length results in a smoother, less sensitive indicator, ideal for long-term trends.
Factor: Determines the bandwidth of the SuperTrend. A higher factor creates wider bands, capturing larger price movements but potentially missing short-term signals.
MA Source: The type of moving average used (e.g., WMA - Weighted Moving Average). Different MA types can affect the trend indicator's responsiveness and smoothness.
4. AI Trend Prediction Settings (Price Trend: 10, Prediction Trend: 80)
Price Trend and Prediction Trend Lengths: These settings define the lengths of weighted moving averages for price and SuperTrend, impacting the responsiveness and smoothness of the AI's trend predictions.
5. Pivot Percentile Settings (Length: 10)
Length: Influences the calculation of pivot percentiles. A shorter length makes the percentile more responsive to recent price changes, while a longer length offers a broader view of price trends.
6. ADX and DMI Settings (ADX Length: 14, Time Frame: 'D')
ADX Length: Defines the period for the Average Directional Index calculation. A longer period results in a smoother ADX line.
Time Frame: Sets the time frame for the ADX and DMI calculations, affecting the sensitivity to market changes.
7. Commission, Slippage, and Initial Capital
These settings relate to transaction costs and initial investment, directly impacting net profitability and strategy feasibility.

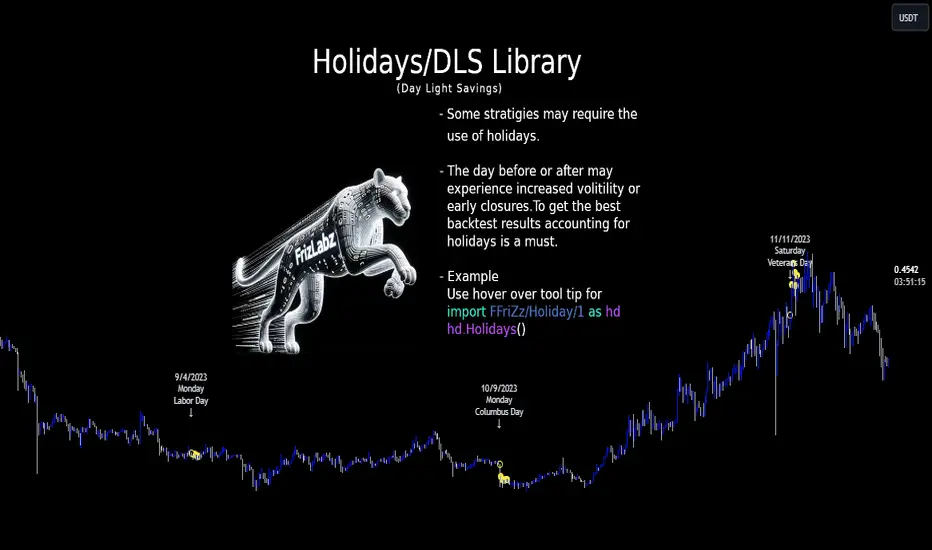
HolidayLibrary "Holiday"
- Full Control over Holidays and Daylight Savings Time (DLS)
The Holiday Library is an essential tool for traders and analysts who engage in backtesting and live trading . This comprehensive library enables the incorporation of crucial calendar elements - specifically Daylight Savings Time (DLS) adjustments and public holidays - into trading strategies and backtesting environments.
Key Features:
- DLS Adjustments: The library takes into account the shifts in time due to Daylight Savings. This feature is particularly vital for backtesting strategies, as DLS can impact trading hours, which in turn affects the volatility and liquidity in the market. Accurate DLS adjustments ensure that backtesting scenarios are as close to real-life conditions as possible.
- Comprehensive Holiday Metadata: The library includes a rich set of holiday metadata, allowing for the detailed scheduling of trading activities around public holidays. This feature is crucial for avoiding skewed results in backtesting, where holiday trading sessions might differ significantly in terms of volume and price movement.
- Customizable Holiday Schedules: Users can add or remove specific holidays, tailoring the library to fit various regional market schedules or specific trading requirements.
- Visualization Aids: The library supports on-chart labels, making it visually intuitive to identify holidays and DLS shifts directly on trading charts.
Use Cases:
1. Strategy Development: When developing trading strategies, it’s important to account for non-trading days and altered trading hours due to holidays and DLS. This library enables a realistic and accurate representation of these factors.
2. Risk Management: Trading around holidays can be riskier due to thinner liquidity and greater volatility. By integrating holiday data, traders can better manage their risk exposure.
3. Backtesting Accuracy: For backtesting to be effective, it must simulate the actual market conditions as closely as possible. Incorporating holidays and DLS adjustments contributes to more reliable and realistic backtesting results.
4. Global Trading: For traders active in multiple global markets, this library provides an easy way to handle different holiday schedules and DLS shifts across regions.
The Holiday Library is a versatile tool that enhances the precision and realism of trading simulations and strategy development . Its integration into the trading workflow is straightforward and beneficial for both novice and experienced traders.
EasterAlgo(_year)
Calculates the date of Easter Sunday for a given year using the Anonymous Gregorian algorithm.
`Gauss Algorithm for Easter Sunday` was developed by the mathematician Carl Friedrich Gauss
This algorithm is based on the cycles of the moon and the fact that Easter always falls on the first Sunday after the first ecclesiastical full moon that occurs on or after March 21.
While it's not considered to be 100% accurate due to rare exceptions, it does give the correct date in most cases.
It's important to note that Gauss's formula has been found to be inaccurate for some 21st-century years in the Gregorian calendar. Specifically, the next suggested failure years are 2038, 2051.
This function can be used for Good Friday (Friday before Easter), Easter Sunday, and Easter Monday (following Monday).
en.wikipedia.org
Parameters:
_year (int) : `int` - The year for which to calculate the date of Easter Sunday. This should be a four-digit year (YYYY).
Returns: tuple - The month (1-12) and day (1-31) of Easter Sunday for the given year.
easterInit()
Inits the date of Easter Sunday and Good Friday for a given year.
Returns: tuple - The month (1-12) and day (1-31) of Easter Sunday and Good Friday for the given year.
isLeapYear(_year)
Determine if a year is a leap year.
Parameters:
_year (int) : `int` - 4 digit year to check => YYYY
Returns: `bool` - true if input year is a leap year
method timezoneHelper(utc)
Helper function to convert UTC time.
Namespace types: series int, simple int, input int, const int
Parameters:
utc (int) : `int` - UTC time shift in hours.
Returns: `string`- UTC time string with shift applied.
weekofmonth()
Function to find the week of the month of a given Unix Time.
Returns: number - The week of the month of the specified UTC time.
dayLightSavingsAdjustedUTC(utc, adjustForDLS)
dayLightSavingsAdjustedUTC
Parameters:
utc (int) : `int` - The normal UTC timestamp to be used for reference.
adjustForDLS (bool) : `bool` - Flag indicating whether to adjust for daylight savings time (DLS).
Returns: `int` - The adjusted UTC timestamp for the given normal UTC timestamp.
getDayOfYear(monthOfYear, dayOfMonth, weekOfMonth, dayOfWeek, lastOccurrenceInMonth, holiday)
Function gets the day of the year of a given holiday (1-366)
Parameters:
monthOfYear (int)
dayOfMonth (int)
weekOfMonth (int)
dayOfWeek (int)
lastOccurrenceInMonth (bool)
holiday (string)
Returns: `int` - The day of the year of the holiday 1-366.
method buildMap(holidayMap, holiday, monthOfYear, weekOfMonth, dayOfWeek, dayOfMonth, lastOccurrenceInMonth, closingTime)
Function to build the `holidaysMap`.
Namespace types: map
Parameters:
holidayMap (map) : `map` - The map of holidays.
holiday (string) : `string` - The name of the holiday.
monthOfYear (int) : `int` - The month of the year of the holiday.
weekOfMonth (int) : `int` - The week of the month of the holiday.
dayOfWeek (int) : `int` - The day of the week of the holiday.
dayOfMonth (int) : `int` - The day of the month of the holiday.
lastOccurrenceInMonth (bool) : `bool` - Flag indicating whether the holiday is the last occurrence of the day in the month.
closingTime (int) : `int` - The closing time of the holiday.
Returns: `map` - The updated map of holidays
holidayInit(addHolidaysArray, removeHolidaysArray, defaultHolidays)
Initializes a HolidayStorage object with predefined US holidays.
Parameters:
addHolidaysArray (array) : `array` - The array of additional holidays to be added.
removeHolidaysArray (array) : `array` - The array of holidays to be removed.
defaultHolidays (bool) : `bool` - Flag indicating whether to include the default holidays.
Returns: `map` - The map of holidays.
Holidays(utc, addHolidaysArray, removeHolidaysArray, adjustForDLS, displayLabel, defaultHolidays)
Main function to build the holidays object, this is the only function from this library that should be needed. \
all functionality should be available through this function. \
With the exception of initializing a `HolidayMetaData` object to add a holiday or early close. \
\
**Default Holidays:** \
`DLS begin`, `DLS end`, `New Year's Day`, `MLK Jr. Day`, \
`Washington Day`, `Memorial Day`, `Independence Day`, `Labor Day`, \
`Columbus Day`, `Veterans Day`, `Thanksgiving Day`, `Christmas Day` \
\
**Example**
```
HolidayMetaData valentinesDay = HolidayMetaData.new(holiday="Valentine's Day", monthOfYear=2, dayOfMonth=14)
HolidayMetaData stPatricksDay = HolidayMetaData.new(holiday="St. Patrick's Day", monthOfYear=3, dayOfMonth=17)
HolidayMetaData addHolidaysArray = array.from(valentinesDay, stPatricksDay)
string removeHolidaysArray = array.from("DLS begin", "DLS end")
܂Holidays = Holidays(
܂ utc=-6,
܂ addHolidaysArray=addHolidaysArray,
܂ removeHolidaysArray=removeHolidaysArray,
܂ adjustForDLS=true,
܂ displayLabel=true,
܂ defaultHolidays=true,
܂ )
plot(Holidays.newHoliday ? open : na, title="newHoliday", color=color.red, linewidth=4, style=plot.style_circles)
```
Parameters:
utc (int) : `int` - The UTC time shift in hours
addHolidaysArray (array) : `array` - The array of additional holidays to be added
removeHolidaysArray (array) : `array` - The array of holidays to be removed
adjustForDLS (bool) : `bool` - Flag indicating whether to adjust for daylight savings time (DLS)
displayLabel (bool) : `bool` - Flag indicating whether to display a label on the chart
defaultHolidays (bool) : `bool` - Flag indicating whether to include the default holidays
Returns: `HolidayObject` - The holidays object | Holidays = (holidaysMap: map, newHoliday: bool, holiday: string, dayString: string)
HolidayMetaData
HolidayMetaData
Fields:
holiday (series string) : `string` - The name of the holiday.
dayOfYear (series int) : `int` - The day of the year of the holiday.
monthOfYear (series int) : `int` - The month of the year of the holiday.
dayOfMonth (series int) : `int` - The day of the month of the holiday.
weekOfMonth (series int) : `int` - The week of the month of the holiday.
dayOfWeek (series int) : `int` - The day of the week of the holiday.
lastOccurrenceInMonth (series bool)
closingTime (series int) : `int` - The closing time of the holiday.
utc (series int) : `int` - The UTC time shift in hours.
HolidayObject
HolidayObject
Fields:
holidaysMap (map) : `map` - The map of holidays.
newHoliday (series bool) : `bool` - Flag indicating whether today is a new holiday.
activeHoliday (series bool) : `bool` - Flag indicating whether today is an active holiday.
holiday (series string) : `string` - The name of the holiday.
dayString (series string) : `string` - The day of the week of the holiday.
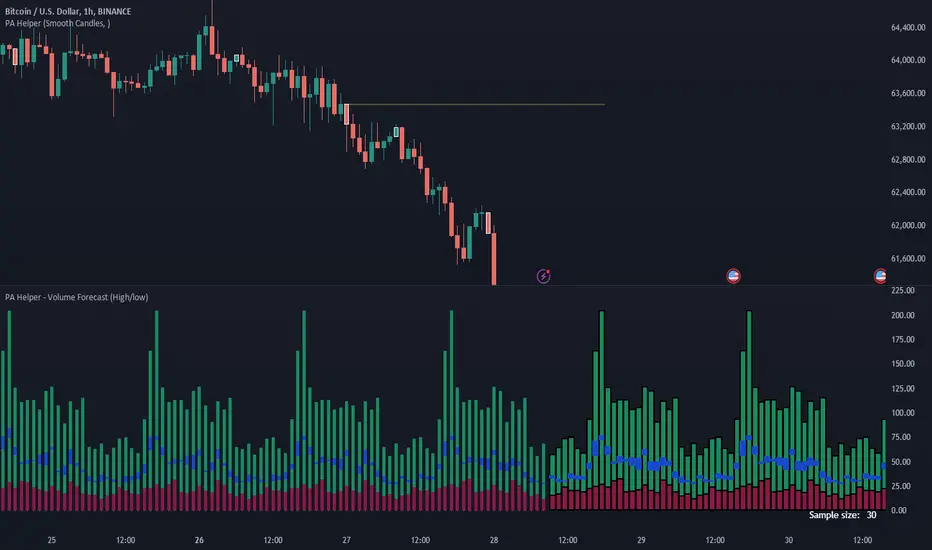
Volume ForecastThe Volume Forecast indicator on TradingView is a comprehensive tool designed to analyze historical price action and project future market movements based on the average sizes of candles. Incorporating various data points such as candle high/low, open/close, and real volumes, Volume Forecast provides traders with a holistic view of market dynamics, allowing for more informed decision-making.
Key Features:
Multi-Data Source Analysis:
Volume Forecast seamlessly integrates multiple data sources, including candle high/low, open/close prices, and real volumes. By considering these diverse elements, the indicator offers a nuanced understanding of market conditions.
Historical Candle Size Analysis:
The indicator conducts a thorough analysis of historical candle sizes, capturing key data points to calculate the average candle size over a specified period. This historical context serves as the foundation for forecasting future candle sizes.
Customizable Forecasting Parameters:
Traders have the flexibility to fine-tune forecasting parameters to align with their trading strategies. Whether focusing on open/close relationships, high/low points, or real volumes, users can customize the indicator to suit their preferences.
Predictive Algorithm:
Volume Forecast employs a sophisticated predictive algorithm that leverages historical candle size data to project the potential size of upcoming candles. This algorithmic approach enhances the indicator's accuracy in forecasting market movements.
Visual Clarity:
The indicator provides a clear visual representation on the TradingView chart, displaying historical candle sizes and forecasted values. Color-coded elements and visual cues help traders quickly interpret the data, facilitating timely decision-making.
Adaptive Real-Time Updates:
Volume Forecast dynamically updates in real-time, ensuring traders have access to the latest information. This adaptability allows for swift adjustments to trading strategies in response to changing market conditions.
Comprehensive Market Compatibility:
Whether trading stocks, forex, cryptocurrencies, or commodities, Volume Forecast is compatible across various financial instruments and timeframes. This versatility makes it a valuable asset for traders in different markets.
User-Friendly Interface:
With an intuitive interface, Volume Forecast is accessible to traders of all experience levels. The indicator's user-friendly design streamlines the analysis process, making it easier for traders to incorporate it into their trading routines.
In summary, Volume Forecast is a robust TradingView indicator that combines historical candle size analysis with advanced forecasting techniques. By incorporating multiple data sources and offering customization options, it empowers traders to make more informed decisions in anticipation of market movements. Whether used independently or in conjunction with other tools, Volume Forecast is a valuable asset for traders seeking a comprehensive understanding of market dynamics.
Machine Learning: kNN (New Approach)Description:
kNN is a very robust and simple method for data classification and prediction. It is very effective if the training data is large. However, it is distinguished by difficulty at determining its main parameter, K (a number of nearest neighbors), beforehand. The computation cost is also quite high because we need to compute distance of each instance to all training samples. Nevertheless, in algorithmic trading KNN is reported to perform on a par with such techniques as SVM and Random Forest. It is also widely used in the area of data science.
The input data is just a long series of prices over time without any particular features. The value to be predicted is just the next bar's price. The way that this problem is solved for both nearest neighbor techniques and for some other types of prediction algorithms is to create training records by taking, for instance, 10 consecutive prices and using the first 9 as predictor values and the 10th as the prediction value. Doing this way, given 100 data points in your time series you could create 10 different training records. It's possible to create even more training records than 10 by creating a new record starting at every data point. For instance, you could take the first 10 data points and create a record. Then you could take the 10 consecutive data points starting at the second data point, the 10 consecutive data points starting at the third data point, etc.
By default, shown are only 10 initial data points as predictor values and the 6th as the prediction value.
Here is a step-by-step workthrough on how to compute K nearest neighbors (KNN) algorithm for quantitative data:
1. Determine parameter K = number of nearest neighbors.
2. Calculate the distance between the instance and all the training samples. As we are dealing with one-dimensional distance, we simply take absolute value from the instance to value of x (| x – v |).
3. Rank the distance and determine nearest neighbors based on the K'th minimum distance.
4. Gather the values of the nearest neighbors.
5. Use average of nearest neighbors as the prediction value of the instance.
The original logic of the algorithm was slightly modified, and as a result at approx. N=17 the resulting curve nicely approximates that of the sma(20). See the description below. Beside the sma-like MA this algorithm also gives you a hint on the direction of the next bar move.

Pulu's 3 Moving Averages
Pulu's 3 Moving Averages
Release version 1, date 2021-09-28
This script allows you to customize three sets of moving averages, turn on/off, set color and parameters. It also tags the start date of the last set of moving average if there is. This, release version 1, supports eight moving average algorithms:
ALMA, Arnaud Legoux Moving Average
EMA, Exponential Moving Average
RMA, Adjusted exponential moving average (aka Wilder’s EMA)
SMA, Simple Moving Average
SWMA, Symmetrically-Weighted Moving Average
VWAP, Volume-Weighted Average Price
VWMA, Volume-Weighted Moving Average
WMA, Weighted Moving Average
The availability and function parameters
Func. Availability Parameters
ALMA
MA1, MA2, MA3
source
length
offset
sigma
EMA
RMA
SMA
VWMA
WMA
MA1, MA2, MA3
source
length
SWMA
VWAP
MA1
source
Parameters
Parameter Description
source the series of values to process. The default is to use the closing price to calculate the moving average.
length an integer value that defines the number of bars to calculate the moving average on. The SWMA and VWAP do not use this parameter.
ALMA offset a floating-point value that controls the tradeoff between smoothness (with a value closer to 1) and responsiveness (with a value closer to 0). This parameter is only used by ALMA.
ALMA sigma a floating-point value that specifies the ALMA’s smoothness. The larger this value, the smoother the moving average is. This parameter is only used by ALMA.
I'm not sure if it is needed, so I do not let the three Moving Averages of the script to have indivial algorithm setting. Because that will involve much complicated condition testing and use up more TradingView script lines limit. If you need to combine different algorithms in the three sets of moving averages, or have other ideas, leave a message to let me know; maybe I will try it in the next update.
我不確定是否需要,所以我沒有讓腳本的三組移動平均線有各別的算法設置。因為這將涉及更多複雜的條件測試,並使用更多 TradingView 腳本列數限制。如果您需要在三組均線中組合不同的算法,或者有其他想法,請留言告訴我;也許我會在下一次更新中嘗試。
Band Walk Detector TENKYO [BASIC]1. Abstract: The Computational Resolution of Cognitive Latency
This publication presents the findings of the "TENKYO" Research Project , focusing on the algorithmic detection of high-probability volatility breakouts ("Band Walks") on the 15-minute timeframe.
Problem Statement: Manual trading suffers from a critical "Cognitive Latency Gap." A trader cannot simultaneously process multi-dimensional variables—volatility expansion rates (derivative of variance), candle morphology (price rejection ratios), and time-weighted liquidity cycles—within the millisecond timeframe required for optimal execution.
Solution: This script is not a discretionary indicator but a Hard-Coded Decision Support System . It automates the verification of market conditions using a "Piecewise Constant Parameter Model," offloading the computational burden from the human operator to the CPU.
Note: This is a research release for the verification of the TENKYO logic, not a commercial product.
2. Theoretical Framework & Methodology
The architecture of this script rejects the standard "Stationary Volatility Assumption" (the idea that market behavior is consistent throughout the day). Instead, it adopts a Time-Segmented Heteroskedasticity Model.
A. Temporal Segmentation Logic (The Session Filter)
Global forex markets exhibit distinct liquidity profiles based on the active session (London, New York, Tokyo/Sydney). A standard deviation ($\sigma$) that signals a breakout in the Asian session is often mere noise in the London session.To solve this, the script partitions the trading day into four distinct phases ($S_1, S_2, S_3, S_4$) and applies a Dynamic Parameter Matrix:
・ Logic: $P(t) = \{ \text{Length}_i, \text{Mult}_i, \text{Threshold}_i \}$ where $t \in S_i$
・ Implementation: The script contains an extensive if-else structure that automatically swaps the Lookback Period and Deviation Multiplier based on the timestamp. This allows the algorithm to "tighten" or "loosen" its sensitivity relative to expected market volume.
B. Synthetic Execution Modeling (Bid/Ask Simulation)
TradingView's default variables (close, high, low) represent mid-market data, which fails to account for the spread cost inherent in execution.
・Correction: This algorithm internally calculates synthetic Bid and Ask prices using a defined spread factor ($\Delta$).
・Formula:
$$P_{Ask} = P_{Mid} + (\Delta / 2), \quad P_{Bid} = P_{Mid} - (\Delta / 2)$$
3. Algorithmic Core: The "TENKYO" Logic
The script identifies a "Band Walk" only when three independent layers of logic align perfectly.
Layer 1: The Volatility Impulse (Expansion)
The primary trigger is not merely price crossing a band, but the acceleration of the Band Width.
・Condition: The algorithm monitors the differential of the Upper and Lower bands. A signal is generated only if the expansion velocity exceeds a predefined Pips threshold (bwGrow_px) specifically tuned for the current session $S_i$.
Layer 2: Morphological Rejection Filtering (Wick Analysis)
To filter out "Mean Reversion Traps" (False Breakouts), the script analyzes the morphology of the signal candle using a Wick-to-Body Ratio test.
・The Trap: A candle that breaks the band but closes with a long rejection wick indicates exhausted momentum.
・The Filter: Let $R_{wb} = \text{Body} / \text{RejectionWick}$. If $R_{wb} < \text{Threshold}_{Si}$,, the signal is suppressed.This mathematical filter prevents the user from entering trades where the market sentiment has already reversed within the candle's duration.Layer
3: The "Scramble" State (Momentum Continuity)
The script introduces a unique state machine called "Scramble."
・Purpose: To detect re-entry opportunities during a high-momentum trend.
・Mechanism: If the market enters an "Endure" state (a pause in expansion) but validates specific continuity conditions (price remains within the $2\sigma$ corridor without violating the trend vector), the algorithm flags a "Scramble" signal. This effectively distinguishes between a "Trend Reversal" and a "Trend Pause."
4. Operational Features & Visual Guide
This tool is designed to serve as a rigorous "Filter" for manual trading.
・The "Mushy" Zone: Visualized by a gray fill between bands. This represents a low-kurtosis, mean-reverting market state where trend-following strategies are statistically disadvantageous. The algorithm disables all signals in this zone.
・Secure & Breakeven Visualization: The script projects potential exit points based on Maximum Favorable Excursion (MFE) logic calculated from the entry bar's synthetic price. This assists the user in objective trade management.
・Hard-Coded Optimization: Users will notice that many parameters are locked or preset. This is intentional. These values are derived from extensive backtesting on EURUSD and JPY pairs and serve as the "Control" variables for this research.
5. Conclusion
The Band Walk Detector TENKYO is a comprehensive logical framework that integrates time, volatility, and morphology. It denies the simplistic "one-size-fits-all" approach of standard indicators in favor of a granular, session-adaptive model. It provides the trader with a computationally verified "Go/No-Go" signal, bridging the gap between human intuition and algorithmic precision.

ML Adaptive SuperTrend Strategy [trade_crush]# ML Adaptive SuperTrend Strategy - User Guide
## Introduction
The **ML Adaptive SuperTrend Strategy** is a sophisticated trading tool that combines traditional trend-following logic with **Machine Learning (K-Means Clustering)** to dynamically adapt to market volatility. Unlike standard SuperTrend indicators that use a fixed ATR, this strategy analyzes historical volatility to categorize the current market into distinct clusters, providing more precise entries and exits.
>
> **Special Thanks:** This strategy is based on the innovative work of **AlgoAlpha**. You can explore their extensive library of high-quality indicators and strategies on TradingView: (www.tradingview.com).
---
## Machine Learning Engine (K-Means)
The core of this strategy is its ability to "learn" from recent market behavior.
- **K-Means Clustering**: The script takes the last $N$ bars of ATR data and runs an iterative clustering algorithm to find three "centroids" representing **High**, **Medium**, and **Low** volatility.
- **Adaptive ATR**: Based on the current volatility, the strategy selects the nearest centroid to use as the ATR value for the SuperTrend calculation. This ensures the trailing stop tightens during low volatility and widens during high volatility to avoid "noise".
---
## Key Features
### 1. Non-Repainting Signals
- **Confirm Signals**: When enabled, signals are only triggered after a bar closes. This ensures that the arrows and entries you see on the chart are permanent and reliable for backtesting.
### 2. Intelligent Risk Management
- **Multiple SL/TP Types**: Choose between **Percentage** based stops or **ATR** based stops for both Stop Loss and Take Profit.
- **Trailing Stop Loss (TSL)**:
- Supports both Percentage and ATR modes.
- **Activation Offset**: Only activates the trailing mechanism after the price has moved a certain percentage in your favor, protecting early-stage trades.
### 3. Risk-Based Position Sizing
- **Dynamic Quantity**: If enabled, the strategy automatically calculates the trade size based on your **Risk % Per Trade** and the distance to your **Stop Loss**. This ensures you never lose more than your defined risk on a single trade.
---
## User Input Guide
### SuperTrend & ML Settings
- **ATR Length**: The window used to calculate market volatility.
- **SuperTrend Factor**: The multiplier that determines the distance of the trailing stop from the price.
- **Use ML Adaptive ATR**: Toggle between the ML-enhanced logic and standard ATR.
- **Training Data Length**: How many historical bars the ML engine analyzes to find clusters.
### Risk Management
- **Stop Loss Type**: Set to Percentage, ATR, or None.
- **TS Activation Offset**: The profit buffer required before the trailing stop starts following the price.
- **Use Risk-Based Sizing**: Toggle this to let the script manage your position size automatically.
---
## How to Trade with This Strategy
1. **Monitor the Dashboard**: Check the top-right table to see which volatility cluster the market is currently in.
2. **Observe the Fills**: The adaptive fills (green/red) visualize the "breathing room" the strategy is giving the price.
3. **Execution**: The strategy enters on "ML Bullish" (Triangle Up) and "ML Bearish" (Triangle Down) signals.
4. **Exits**: The script will automatically exit based on your SL, TP, or Trailing Stop settings.
---
## Credits
Original Concept: **AlgoAlpha**
Strategy Conversion & Enhancements: **Antigravity AI**

MLExtensionsLibrary "MLExtensions"
A set of extension methods for a novel implementation of a Approximate Nearest Neighbors (ANN) algorithm in Lorentzian space.
normalizeDeriv(src, quadraticMeanLength)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src (float) : The input series (i.e., the first-order derivative for price).
quadraticMeanLength (int) : The length of the quadratic mean (RMS).
Returns: nDeriv The normalized derivative of the input series.
normalize(src, min, max)
Rescales a source value with an unbounded range to a target range.
Parameters:
src (float) : The input series
min (float) : The minimum value of the unbounded range
max (float) : The maximum value of the unbounded range
Returns: The normalized series
rescale(src, oldMin, oldMax, newMin, newMax)
Rescales a source value with a bounded range to anther bounded range
Parameters:
src (float) : The input series
oldMin (float) : The minimum value of the range to rescale from
oldMax (float) : The maximum value of the range to rescale from
newMin (float) : The minimum value of the range to rescale to
newMax (float) : The maximum value of the range to rescale to
Returns: The rescaled series
getColorShades(color)
Creates an array of colors with varying shades of the input color
Parameters:
color (color) : The color to create shades of
Returns: An array of colors with varying shades of the input color
getPredictionColor(prediction, neighborsCount, shadesArr)
Determines the color shade based on prediction percentile
Parameters:
prediction (float) : Value of the prediction
neighborsCount (int) : The number of neighbors used in a nearest neighbors classification
shadesArr (array) : An array of colors with varying shades of the input color
Returns: shade Color shade based on prediction percentile
color_green(prediction)
Assigns varying shades of the color green based on the KNN classification
Parameters:
prediction (float) : Value (int|float) of the prediction
Returns: color
color_red(prediction)
Assigns varying shades of the color red based on the KNN classification
Parameters:
prediction (float) : Value of the prediction
Returns: color
tanh(src)
Returns the the hyperbolic tangent of the input series. The sigmoid-like hyperbolic tangent function is used to compress the input to a value between -1 and 1.
Parameters:
src (float) : The input series (i.e., the normalized derivative).
Returns: tanh The hyperbolic tangent of the input series.
dualPoleFilter(src, lookback)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src (float) : The input series (i.e., the hyperbolic tangent).
lookback (int) : The lookback window for the smoothing.
Returns: filter The smoothed hyperbolic tangent of the input series.
tanhTransform(src, smoothingFrequency, quadraticMeanLength)
Returns the tanh transform of the input series.
Parameters:
src (float) : The input series (i.e., the result of the tanh calculation).
smoothingFrequency (int)
quadraticMeanLength (int)
Returns: signal The smoothed hyperbolic tangent transform of the input series.
n_rsi(src, n1, n2)
Returns the normalized RSI ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the RSI calculation).
n1 (simple int) : The length of the RSI.
n2 (simple int) : The smoothing length of the RSI.
Returns: signal The normalized RSI.
n_cci(src, n1, n2)
Returns the normalized CCI ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the CCI calculation).
n1 (simple int) : The length of the CCI.
n2 (simple int) : The smoothing length of the CCI.
Returns: signal The normalized CCI.
n_wt(src, n1, n2)
Returns the normalized WaveTrend Classic series ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the WaveTrend Classic calculation).
n1 (simple int)
n2 (simple int)
Returns: signal The normalized WaveTrend Classic series.
n_adx(highSrc, lowSrc, closeSrc, n1)
Returns the normalized ADX ideal for use in ML algorithms.
Parameters:
highSrc (float) : The input series for the high price.
lowSrc (float) : The input series for the low price.
closeSrc (float) : The input series for the close price.
n1 (simple int) : The length of the ADX.
regime_filter(src, threshold, useRegimeFilter)
Parameters:
src (float)
threshold (float)
useRegimeFilter (bool)
filter_adx(src, length, adxThreshold, useAdxFilter)
filter_adx
Parameters:
src (float) : The source series.
length (simple int) : The length of the ADX.
adxThreshold (int) : The ADX threshold.
useAdxFilter (bool) : Whether to use the ADX filter.
Returns: The ADX.
filter_volatility(minLength, maxLength, useVolatilityFilter)
filter_volatility
Parameters:
minLength (simple int) : The minimum length of the ATR.
maxLength (simple int) : The maximum length of the ATR.
useVolatilityFilter (bool) : Whether to use the volatility filter.
Returns: Boolean indicating whether or not to let the signal pass through the filter.
backtest(high, low, open, startLongTrade, endLongTrade, startShortTrade, endShortTrade, isEarlySignalFlip, maxBarsBackIndex, thisBarIndex, src, useWorstCase)
Performs a basic backtest using the specified parameters and conditions.
Parameters:
high (float) : The input series for the high price.
low (float) : The input series for the low price.
open (float) : The input series for the open price.
startLongTrade (bool) : The series of conditions that indicate the start of a long trade.
endLongTrade (bool) : The series of conditions that indicate the end of a long trade.
startShortTrade (bool) : The series of conditions that indicate the start of a short trade.
endShortTrade (bool) : The series of conditions that indicate the end of a short trade.
isEarlySignalFlip (bool) : Whether or not the signal flip is early.
maxBarsBackIndex (int) : The maximum number of bars to go back in the backtest.
thisBarIndex (int) : The current bar index.
src (float) : The source series.
useWorstCase (bool) : Whether to use the worst case scenario for the backtest.
Returns: A tuple containing backtest values
init_table()
init_table()
Returns: tbl The backtest results.
update_table(tbl, tradeStatsHeader, totalTrades, totalWins, totalLosses, winLossRatio, winrate, earlySignalFlips)
update_table(tbl, tradeStats)
Parameters:
tbl (table) : The backtest results table.
tradeStatsHeader (string) : The trade stats header.
totalTrades (float) : The total number of trades.
totalWins (float) : The total number of wins.
totalLosses (float) : The total number of losses.
winLossRatio (float) : The win loss ratio.
winrate (float) : The winrate.
earlySignalFlips (float) : The total number of early signal flips.
Returns: Updated backtest results table.

Volume Profile VisionVolume Profile Vision - Complete Description
Overview
Volume Profile Vision (VPV) is an advanced volume profile indicator that visualizes where trading activity has occurred at different price levels over a specified time period. Unlike traditional volume indicators that show volume over time, this indicator displays volume distribution across price levels, helping traders identify key support/resistance zones, fair value areas, and potential reversal points.
What Makes This Indicator Original
Volume Profile Vision introduces several unique features not found in standard volume profile tools:
Dual-Direction Histogram Display:
Unlike conventional volume profiles that only show bars extending in one direction, VPV displays volume bars extending both left (into historical candles) and right (as a traditional histogram). This bi-directional approach allows traders to see exactly where historical price action intersected with high-volume nodes.
Real-Time Candle Highlighting: The indicator dynamically highlights volume bars that intersect with the current candle's price range, making it immediately obvious which volume levels are currently in play.
Four Professional Color Schemes: Each color scheme uses distinct gradient algorithms and visual encoding systems:
Traffic Light: Uses red (POC), green (VA boundaries), yellow (HVN), with grayscale gradients outside the value area
Aurora Glass: Modern cyan-to-magenta gradient with hot magenta POC highlighting
Obsidian Precision: Professional dark theme with white POC and electric cyan accents
Black Ice: Monochromatic cyan family with graduated intensity
Adaptive Transparency System: Automatically adjusts bar transparency based on position relative to value area, with special handling for each color scheme to maintain visual clarity.
Core Concepts & Calculations
Volume Distribution Analysis
The indicator divides the visible price range into user-defined price levels (default: 80 levels) and calculates the total volume traded at each level by:
Scanning back through the specified lookback period (customizable or visible range)
For each historical bar, determining which price levels the bar's high/low range intersects
Accumulating volume for each intersected price level
Optionally filtering by bullish/bearish volume only
Point of Control (POC)
The POC is the price level with the highest traded volume during the analyzed period. This represents the "fairest" price where most traders agreed on value. The indicator marks this with distinct coloring (red in Traffic Light, magenta in Aurora Glass, white in Obsidian Precision, cyan in Black Ice).
Trading Significance: POC acts as a strong magnet for price - markets tend to return to fair value. When price is away from POC, traders watch for:
Mean reversion opportunities when price is far from POC
Rejection signals when price tests POC from above/below
Breakout confirmation when price breaks through and holds beyond POC
Value Area (VA)
The Value Area encompasses the price range where a specified percentage (default: 68%) of all volume traded. This represents the range of "accepted value" by market participants.
Calculation Method:
Start at the POC (highest volume level)
Expand upward and downward, adding adjacent price levels
Always add the level with higher volume next
Continue until accumulated volume reaches the VA percentage threshold
Value Area High (VAH): Upper boundary of accepted value - acts as resistance
Value Area Low (VAL): Lower boundary of accepted value - acts as support
Trading Significance:
Price spending time inside VA indicates market equilibrium
Breakouts above VAH suggest bullish momentum shift
Breakdowns below VAL suggest bearish momentum shift
Returns to VA boundaries often provide high-probability entry zones
High Volume Nodes (HVN)
Price levels with volume exceeding a threshold percentage (default: 80%) of POC volume. These represent areas of strong agreement and consolidation.
Trading Significance:
HVNs act as strong support/resistance zones
Price tends to consolidate at HVNs before making directional moves
Breaking through an HVN often signals strong momentum
Low Volume Nodes (LVN)
Price levels within the Value Area with volume ≤30% of POC volume. These are zones price moved through quickly with minimal consolidation.
Trading Significance:
LVNs represent areas of rejection - price finds little acceptance
Price tends to move rapidly through LVN zones
Useful for setting stop-losses (below LVN for longs, above for shorts)
Can identify potential gaps or "air pockets" in the market structure
Grayscale POC Detection
A secondary POC detection system identifies the highest volume level outside the Value Area (with a 2-level buffer to avoid confusion). This helps identify significant volume accumulation zones that exist beyond the main value area.
How to Use This Indicator
Setup
Choose Lookback Period:
Enable "Use Visible Range" to analyze only what's on your chart
Or set "Fixed Range Lookback Depth" (default: 200 bars) for consistent analysis
Adjust Profile Resolution:
"Number of Price Levels" (default: 80) - higher = more granular analysis, lower = broader zones
Select Color Scheme:
Traffic Light: Best for clear POC/VA/HVN identification
Aurora Glass: Modern aesthetic for dark charts
Obsidian Precision: Professional trader preference
Black Ice: Minimalist single-color family
Visual Customization
Left Extension: How far back the left-side histogram extends into historical candles (default: 490 bars)
Right Extension: Width of the traditional histogram bars on the right (default: 50 bars)
Right Margin: Space between current price bar and histogram (default: 0 for flush alignment)
Left Profile Gap: Space between left-side histogram and candles (default: 0)
Trading Strategies
Strategy 1: Value Area Mean Reversion
Wait for price to move outside the Value Area (above VAH or below VAL)
Look for rejection signals (wicks, bearish/bullish candles)
Enter trades toward the POC
Take profits as price returns to POC or opposite VA boundary
Strategy 2: Breakout Confirmation
Identify when price is consolidating within the Value Area
Wait for a strong close above VAH (bullish) or below VAL (bearish)
Enter on the breakout or on first pullback to the VA boundary
Target previous HVNs or swing highs/lows outside the VA
Strategy 3: POC Support/Resistance
Watch for price approaching the POC level
If approaching from below, look for bullish reversal patterns at POC (support)
If approaching from above, look for bearish reversal patterns at POC (resistance)
Trade in the direction of the bounce with stops beyond the POC
Strategy 4: LVN Fast Movement Zones
Identify LVN zones within the Value Area (marked with "LVN" label)
When price enters an LVN, expect rapid movement through the zone
Avoid entering trades within LVNs
Use LVNs as confirmation of directional momentum
Alert System
The indicator includes 7 customizable alert conditions:
POC Touch: Alerts when price comes within 0.5 ATR of POC
VAH/VAL Touch: Alerts at Value Area boundaries
VA Breakout: Alerts on breakouts above VAH or below VAL
HVN Touch: Alerts when price contacts High Volume Nodes
LVN Entry: Alerts when entering Low Volume zones
POC Shift: Alerts when POC moves to a new price level
Reading the Profile
Price Labels (shown on the right side):
POC: Point of Control - highest volume price level
VAH: Value Area High - upper boundary of accepted value
VAL: Value Area Low - lower boundary of accepted value
LVN: Low Volume Node - expect fast movement through this zone
Color Intensity Interpretation:
Brighter colors = higher volume concentration
Dimmer colors = lower volume
Abrupt color changes = transition between volume zones
Gaps in the histogram = price levels with no trading activity
Technical Details
Volume Accumulation Logic:
For each bar in lookback period:
For each price level:
If bar's high/low range intersects price level:
Add bar's volume to that price level's total
Gradient Algorithm:
Traffic Light: Dual-range piecewise gradient (0-50% and 50-100% volume intensity)
Aurora Glass: Linear cyan-to-magenta interpolation
Obsidian Precision: Dark blue gradient with cyan highlights
Black Ice: Three-stage cyan intensity progression
Real-Time Updates:
The profile recalculates on every bar, including real-time tick data, ensuring the volume distribution always reflects current market structure.
Best Practices
Timeframe Selection: Use higher timeframes (4H, Daily) for swing trading, lower timeframes (5min, 15min) for day trading
Combine with Price Action: Volume profile shows WHERE, price action shows WHEN
Multiple Timeframe Analysis: Check daily VP for major levels, then drill down to intraday for entries
Volume Type Selection: Use "Bullish" volume in uptrends, "Bearish" in downtrends, or "Both" for complete picture
Adjust VA Percentage: 68% (default) captures one standard deviation; try 70% for tighter or 60% for broader value areas
Performance Notes
Maximum bars back: 5000 (handles deep historical analysis)
Maximum boxes: 500 (handles complex profiles)
Optimized calculation: Only recalculates on last bar for efficiency
Real-time capable: Updates as new ticks arrive

Advanced Market Profile & S/R Zones (Pro)Advanced Market Profile & S/R Zones
This indicator brings professional Auction Market Theory to your chart using a custom rolling Volume Profile algorithm. Unlike standard profiles that remain fixed, this tool dynamically calculates the "Fair Value" of the asset based on your specific lookback period (e.g., the last 100 bars).
It automatically highlights the Point of Control (POC), Value Area (VA), and suggests statistical Discount (Buy) and Premium (Sell) zones.
Key Features
Volume Splitting Algorithm:
Most basic scripts dump the entire volume of a candle into a single price point (the average). This script splits the volume across the candle's entire High-Low range. This results in a much smoother, higher-resolution bell curve that accurately reflects price action, especially on higher timeframes like Monthly charts.
Auto-generated Zones:
Green Zone (Discount): Prices below the Value Area Low (VAL). Statistically "cheap."
Red Zone (Premium): Prices above the Value Area High (VAH). Statistically "expensive."
Real-Time Dashboard:
A built-in panel displays the exact price levels for the POC, VAH, and VAL for precise limit order placement, along with the current Market Trend.
How to Use
For Intraday (Day Trading):
Settings: Set Lookback to 100 - 300.
Strategy: Watch for price to open outside the Value Area. If price breaks back inside the Value Area, target the POC (Red Line).
For Macro (Monthly/Weekly Charts):
Settings: Set Lookback to 12 (1 Year) or 60 (5 Years).
Strategy: Identify multi-year structural support. When a monthly candle enters the Green Discount Zone of a 5-year profile, it is often a high-probability institutional entry point.
Trend Logic
The Dashboard indicates trend based on price location relative to value:
Strong Bullish: Price is accepted ABOVE the Value Area.
Strong Bearish: Price is accepted BELOW the Value Area.
Neutral / In VA: Price is chopping inside the Value Area.
Disclaimer
This is a "Rolling Profile." It calculates the profile based on the current lookback window relative to the latest bar. As new bars form, the lookback window shifts, and the profile updates to reflect the new dataset.

Custom Bollinger Band Squeeze Screener [Pineify]Custom Bollinger Band Squeeze Screener
Key Features
Multi-symbol scanning: Analyze up to 6 tickers simultaneously.
Multi-timeframe flexibility: Screen across four selectable timeframes for each symbol.
Bollinger Band Squeeze algorithm: Detect volatility contraction and imminent breakouts.
Advanced ATR integration: Measure expansion and squeeze states with custom multipliers.
Customizable indicator parameters: Fine-tune Bollinger and ATR settings for tailored detection.
Visual table interface: Rapidly compare squeeze and expansion signals across all instruments.
How It Works
At the core, this screener leverages a unique blend of Bollinger Bands and Average True Range (ATR) to quantify volatility states for multiple assets and timeframes at once. For each symbol and every selected timeframe, the indicator calculates Bollinger Band width and compares it against ATR levels, offering real-time squeeze (consolidation) and expansion (breakout) signals.
Bollinger Band width is computed using standard deviations around a SMA basis.
ATR is calculated to gauge market volatility independent of price direction.
Squeeze: Triggered when BB width contracts below a multiple of ATR, forecasting lower volatility and set-up for a move.
Expansion: Triggered when BB width expands above a higher ATR multiple, signaling a high-volatility breakout.
Display: Results shown in an intuitive table, marking each status per ticker and TF.
Trading Ideas and Insights
Spot assets poised for volatility-driven breakouts.
Compare squeeze presence across timeframes for optimal entry timing.
Integrate screener results with price action or volume for high-confidence setups.
Use squeeze signals to avoid choppy or non-trending conditions.
Expand and diversify watchlists with multi-symbol coverage.
How Multiple Indicators Work Together
This script seamlessly merges Bollinger Bands and ATR with customized multipliers:
Bollinger Bands identify price consolidation and volatility squeeze zones.
ATR tailors the definition of squeeze and expansion, making signals adaptive to volatility regime changes.
By layering these with multi-symbol/multi-timeframe data, traders access a high-precision view of market readiness for trend acceleration or reversal.
The real synergy is in the screener's ability to visualize volatility states for a diverse asset selection, transforming traditional single-chart analysis into a broad market view.
Unique Aspects
Original implementation: Not a simple trend or scalping indicator; utilizes advanced volatility logic.
Fully multi-symbol and multi-timeframe support uncommon in most screeners.
Custom ATR multipliers for both squeeze and expansion allow traders to match their risk profile and market dynamics.
Visual clarity: Table structure promotes actionable insights and reduces decision fatigue.
How to Use
Add the indicator to your TradingView chart (supports any asset class including crypto, forex, stocks).
Select up to six symbols (tickers) and set your preferred timeframes.
Adjust Bollinger Band Length/Deviation and ATR multipliers to refine squeeze/expansion criteria.
Review the screener table: Look for "SQZ" (squeeze) or "EXP" (expansion) cells for entry/exit ideas.
Combine screener information with other technical or fundamental signals for trade confirmation.
Customization
Symbols: Choose any tickers for scanning.
Timeframes: Select short- to long-term intervals to match your trading style.
Bollinger Band parameters: Modify length and deviation for sensitivity.
ATR multipliers: Set low or high values to adjust squeeze/expansion triggers.
Table size and layout: Adapt display for optimal workflow.
Conclusion
The Bollinger Band Squeeze Screener Pineify delivers an innovative, SEO-friendly multi-asset solution for volatility and trend detection. Harness its original algorithmic design to uncover powerful breakout opportunities and optimize your portfolio. Whether you trade crypto with dynamic volatility or scan stocks for momentum, this tool supercharges your TradingView workflow.

Opening Range Gaps [TakingProphets]What is an Opening Range Gap (ORG)?
In ICT, the Opening Range Gap is defined as the price difference between the previous session’s close (e.g., 4:00 PM EST in U.S. indices) and the current day’s open (9:30 AM EST).
That gap is a liquidity void—an area where no trading occurred during regular hours.
Why ICT Traders Care About ORG
Liquidity Void (Gap Fill Logic)
-Because the gap is an untraded area, it naturally acts as a draw on liquidity.
-Price often seeks to rebalance by retracing into or fully filling this void.
Premium/Discount Sensitivity
-Once the ORG is defined, ICT treats it as a mini dealing range.
-Above EQ (Consequent Encroachment) = algorithmic premium (sell-sensitive).
-Below EQ = algorithmic discount (buy-sensitive).
-Price reaction at these levels gives a precise read on institutional intent intraday.
Support/Resistance from ORG
-If the session opens above prior close, the gap often acts as support until violated.
-If the session opens below prior close, the gap often acts as resistance until reclaimed.
Key ICT Concepts Anchored to ORG
Consequent Encroachment (CE): The midpoint of the gap. The algo is highly sensitive to CE as a decision point: reject → continuation; reclaim → reversal.
Draw on Liquidity (DoL): Price is algorithmically “pulled” toward gap fills, CE, or the opposite side of the ORG.
Order Flow Confirmation: If price ignores the gap and runs away from it, this signals strong institutional order flow in that direction.
Confluence with Other Tools: FVGs, OBs, and HTF PD arrays often overlap with ORG levels, strengthening setups.
Practical Application for Traders
Bias Formation:
Use ORG EQ as a line in the sand for intraday bias.
If price trades below ORG EQ after the open → look for short setups into the prior day’s low or external liquidity.
If price trades above ORG EQ → favor longs into highs/liquidity pools.
Execution Framework:
Wait for liquidity raids or market structure shifts at ORG edges (.00, .25, .50, .75).
Target: EQ, opposite quarter, or full gap fill.
Precision Reads:
ORG lines let traders anticipate where algorithms are likely to respond, providing mechanical invalidation and clear targets without clutter.

Quantile-Based Adaptive Detection🙏🏻 Dedicated to John Tukey. He invented the boxplot, and I finalized it.
QBAD (Quantile-Based Adaptive Detection) is ‘the’ adaptive (also optionally weighted = ready for timeseries) boxplot with more senseful fences. Instead of hardcoded multipliers for outer fences, I base em on a set of quantile-based asymmetry metrics (you can view it as an ‘algorithmic’ counter part of central & standardized moments). So outer bands are Not hardcoded, not optimized, not cross-validated etc, simply calculated at O(nlogn).
You can use it literally everywhere in any context with any continuous data, in any task that requires statistical control, novelty || outlier detection, without worrying and doubting the sense in arbitrary chosen thresholds. Obviously, given the robust nature of quantiles, it would fit best the cases where data has problems.
The thresholds are:
Basis: the model of the data (median in our case);
Deviations: represent typical spread around basis, together form “value” in general sense;
Extensions: estimate data’s extremums via combination of quantile-based asymmetry metrics without relying on actual blunt min and max, together form “range” / ”frame”. Datapoints outside the frame/range are novelties or outliers;
Limits: based also on quantile asymmetry metrics, estimate the bounds within which values can ‘ever’ emerge given the current data generating process stays the same, together form “field”. Datapoints outside the field are very rare, happen when a significant change/structural break happens in current data-generating process, or when a corrupt datapoint emerges.
…
The first part of the post is for locals xd, the second is for the wanderers/wizards/creators/:
First part:
In terms of markets, mostly u gotta worry about dem instruments that represent crypto & FX assets: it’s either activity hence data sources there are decentralized, or data is fishy.
For a higher algocomplexity cost O(nlong), unlike MBAD that is 0(n), this thing (a control system in fact) works better with ishy data (contaminated with wrong values, incomplete, missing values etc). Read about the “ breakdown point of an estimator ” if you wanna understand it.
Even with good data, in cases when you have multiple instruments that represent the same asset, e.g. CL and BRN futures, and for some reason you wanna skip constructing a proper index of em (while you should), QBAD should be better put on each instrument individually.
Another reason to use this algo-based rather than math-based tool, might be in cases when data quality is all good, but the actual causal processes that generate the data are a bit inconsistent and/or possess ‘increased’ activity in a way. SO in high volatility periods, this tool should provide better.
In terms of built-ins you got 2 weightings: by sequence and by inferred volume delta. The former should be ‘On’ all the time when you work with timeseries, unless for a reason you want to consciously turn it off for a reason. The latter, you gotta keep it ‘On’ unless you apply the tool on another dataset that ain’t got that particular additional dimension.
Ain’t matter the way you gonna use it, moving windows, cumulative windows with or without anchors, that’s your freedom of will, but some stuff stays the same:
Basis and deviations are “value” levels. From process control perspective, if you pls, it makes sense to Not only fade or push based on these levels, but to also do nothing when things are ambiguous and/or don’t require your intervention
Extensions and limits are extreme levels. Here you either push or fade, doing nothing is not an option, these are decisive points in all the meanings
Another important thing, lately I started to see one kind of trend here on tradingview as well and in general in near quant sources, of applying averages, percentiles etc ‘on’ other stationary metrics, so called “indicators”. And I mean not for diagnostic or development reasons, for decision making xd
This is not the evil crime ofc, but hillbilly af, cuz the metrics are stationary it means that you can model em, fit a distribution, like do smth sharper. Worst case you have Bayesian statistics armed with high density intervals and equal tail intervals, and even some others. All this stuff is not hard to do, if u aint’t doing it, it’s on you.
So what I’m saying is it makes sense to apply QBAD on returns ‘of your strategy’, on volume delta, but Not on other metrics that already do calculations over their own moving windows.
...
Second part:
Looks like some finna start to have lil suspicions, that ‘maybe’ after all math entities in reality are more like blueprints, while actual representations are physical/mechanical/algorithmic. Std & centralized moments is a math entity that represents location, scale & asymmetry info, and we can use it no problem, when things are legit and consistent especially. Real world stuff tho sometimes deviates from that ideal, so we need smth more handy and real. Add to the mix the algo counter part of means: quantiles.
Unlike the legacy quantile-based asymmetry metrics from the previous century (check quantile skewness & kurtosis), I don’t use arbitrary sets of quantiles, instead we get a binary pattern that is totally geometric & natural (check the code if interested, I made it very damn explicit). In spirit with math based central & standardized moments, each consequent pair is wider empathizing tail info more and more for each higher order metric.
Unlike the classic box plot, where inner thresholds are quartiles and the rest are based on em, here the basis is median (minimises L1), I base inner thresholds on it, and we continue the pattern by basing the further set of levels on the previous set. So unlike the classic box plot, here we have coherency in construction, symmetry.
Another thing to pay attention to, tho for some reason ain’t many talk about it, it’s not conceptually right to think that “you got data and you apply std moments on it”. No, you apply it to ‘centered around smth’ data. That ‘smth’ should minimize L2 error in case of math, L1 error in case of algo, and L0 error in case of learning/MLish/optimizational/whatever-you-cal-it stuff. So in the case of L0, that’s actually the ‘mode’ of KDE, but that’s for another time. Anyways, in case of L2 it’s mean, so we center data around mean, and apply std moments on residuals. That’s the precise way of framing it. If you understand this, suddenly very interesting details like 0th and 1st central moments start to make sense. In case of quantiles, we center data around the median, and do further processing on residuals, same.
Oth moment (I call it init) is always 1, tho it’s interesting to extrapolate backwards the sequence for higher order moments construction, to understand how we actually end up with this zero.
1st moment (I call it bias) of residuals would be zero if you match centering and residuals analysis methods. But for some reason you didn’t do that (e.g centered data around midhinge or mean and applied QBAD on the centered data), you have to account for that bias.
Realizing stuff > understanding stuff
Learning 2981234 human invented fields < realizing the same unified principles how the Universe works
∞
RVol+ Enhanced Relative Volume Indicator📊 RVol+ Enhanced Relative Volume Indicator
Overview
RVol+ (Relative Volume Plus) is an advanced time-based relative volume indicator designed specifically for swing traders and breakout detection. Unlike simple volume comparisons, RVol+ analyzes volume at the same time of day across multiple sessions, providing statistically significant insights into institutional activity and breakout potential.
🎯 Key Features
Core Volume Analysis
Time-Based RVol Calculation - Compares current cumulative volume to the average volume at this exact time over the past N days
Statistical Z-Score - Measures volume in standard deviations from the mean for true anomaly detection
Volume Percentile - Shows where current volume ranks historically (0-100%)
Sustained Volume Filter - 3-bar moving average prevents false signals from single-bar spikes
Breakout Detection
🚀 Confirmed Breakouts - Identifies price breakouts validated by high volume (RVol > 1.5x)
⚠️ False Breakout Warnings - Alerts when price breaks key levels on low volume (high failure risk)
Multi-Timeframe Context - Weekly volume overlay prevents chasing daily noise
Advanced Metrics
OBV Divergence Detection - Spots bullish/bearish accumulation/distribution patterns
Volume Profile Integration - Identifies institutional positioning
Money Flow Analysis - Tracks smart money vs retail activity
Extreme Volume Alerts - 🔥 Labels mark unusual spikes beyond the display cap
Visual Intelligence
Smart Color Coding:
🟢 Bright Teal = High activity (RVol ≥ 1.5x)
🟡 Medium Teal = Caution zone (RVol ≥ 1.2x)
⚪ Light Teal = Normal activity
🟠 Orange = Breakout confirmed
🔴 Red = False breakout risk
Comprehensive Stats Table:
Current Volume (formatted as M/K/B)
RVol ratio
Z-Score with significance
Volume percentile
Historical average and standard deviation
Sustained volume confirmation
📈 How to Use
For Swing Trading (1D - 3W Holds)
Perfect Setup:
✓ RVol > 1.5x (bright teal)
✓ Z-Score > 2.0 (⚡ alert)
✓ Percentile > 90%
✓ Sustained = ✓
✓ 🚀 Breakout label appears
Avoid:
✗ Red "Low Vol" warning during breakouts
✗ RVol < 1.0 at key levels
✗ Sustained volume not confirmed
Signal Interpretation
⚡ Z>2 Labels - Statistically significant volume (95th+ percentile) - highest probability moves
↗️ OBV+ Labels - Bullish accumulation (OBV rising while price consolidates)
↘️ OBV- Labels - Bearish distribution (OBV falling while price rises)
🔵 Blue Background - Weekly volume elevated (confirms daily strength)
⚙️ Customization
Basic Settings
N Day Average - Number of historical days for comparison (default: 5)
RVol Thresholds - Customize highlight levels (default: 1.2x, 1.5x)
Visual Display Cap - Prevent extreme spikes from compressing view (default: 4.0x)
Advanced Metrics (Toggle On/Off)
Z-Score analysis
Weekly RVol context
OBV divergence detection
Volume percentile ranking
Breakout signal generation
Table Customization
Position - 9 placement options to avoid chart overlap
Size - Tiny to Huge
Colors - Full customization of positive/negative/neutral values
Transparency - Adjustable background
Debug Mode
Enable Pine Logs for calculation transparency
Adjustable log frequency
Real-time calculation breakdown
🔬 Technical Details
Algorithm:
Binary search for historical lookups (O(log n) performance)
Time-zone aware session detection
DST-safe timestamp calculations
Exponentially weighted standard deviation
Anti-repainting architecture
Performance:
Optimized for max_bars_back = 5000
Efficient array management
Built-in function optimization
Memory-conscious data structures
📊 What Makes RVol+ Different?
vs. Standard Volume:
Context-aware (time-of-day matters)
Statistical significance testing
False breakout filtering
vs. Basic RVol:
Z-Score normalization (2-3 sigma detection)
Multi-timeframe confirmation
OBV divergence integration
Sustained volume filtering
Smart visual scaling
vs. Professional Tools:
Free and open-source
Fully customizable
No black-box algorithms
Educational debug logs
💡 Best Practices
Wait for Confirmation - Don't enter on first bar; wait for sustained volume ✓
Combine with Price Action - RVol validates, price structure determines entry
Weekly Context Matters - Blue background = institutional interest
Z-Score is King - Focus on ⚡ alerts for highest probability
Avoid Low Volume Breakouts - Red ⚠️ labels = high failure risk
🎓 Trading Psychology
Volume precedes price. When RVol+ shows:
High RVol + Rising OBV = Accumulation before breakout
High RVol at Resistance = Test of conviction
Low RVol on Breakout = Retail-driven (fade candidate)
Z-Score > 3 = Potential "whale" positioning
📝 Credits
Based on the time-based RVol concept from /u/HurlTeaInTheSea, enhanced with:
Statistical analysis (z-scores, percentiles)
Multi-timeframe integration
OBV divergence detection
Professional-grade visualization
Swing trading optimization
🔧 Version History
v2.0 - Enhanced Edition
Added Z-Score analysis
Multi-timeframe volume context
OBV divergence detection
Breakout confirmation system
Smart color coding
Customizable stats table
Debug logging mode
Performance optimizations
📚 Learn More
For optimal use with swing trading:
Combine with support/resistance levels
Watch for volume clusters in consolidation
Use weekly timeframe for trend confirmation
Monitor OBV divergence for early warnings
⚠️ Disclaimer
This indicator is for educational purposes. Volume analysis is one component of trading decisions. Always use proper risk management, consider multiple timeframes, and validate signals with price structure. Past performance does not guarantee future results.
🚀 Getting Started
Add indicator to chart
Adjust "N Day Average" to your preference (5-10 days typical)
Position stats table to avoid overlap
Enable features you want to monitor
Watch for 🚀 breakout confirmations!
Happy Trading! 📈
