Adaptive Fisherized Z-scoreHello Fellas,
It's time for a new adaptive fisherized indicator of me, where I apply adaptive length and more on a classic indicator.
Today, I chose the Z-score, also called standard score, as indicator of interest.
Special Features
Advanced Smoothing: JMA, T3, Hann Window and Super Smoother
Adaptive Length Algorithms: In-Phase Quadrature, Homodyne Discriminator, Median and Hilbert Transform
Inverse Fisher Transform (IFT)
Signals: Enter Long, Enter Short, Exit Long and Exit Short
Bar Coloring: Presents the trade state as bar colors
Band Levels: Changes the band levels
Decision Making
When you create such a mod you need to think about which concepts are the best to conclude. I decided to take Inverse Fisher Transform instead of normalization to make a version which fits to a fixed scale to avoid the usual distortion created by normalization.
Moreover, I chose JMA, T3, Hann Window and Super Smoother, because JMA and T3 are the bleeding-edge MA's at the moment with the best balance of lag and responsiveness. Additionally, I chose Hann Window and Super Smoother because of their extraordinary smoothing capabilities and because Ehlers favours them.
Furthermore, I decided to choose the half length of the dominant cycle instead of the full dominant cycle to make the indicator more responsive which is very important for a signal emitter like Z-score. Signal emitters always need to be faster or have the same speed as the filters they are combined with.
Usage
The Z-score is a low timeframe scalper which works best during choppy/ranging phases. The direction you should trade is determined by the last trend change. E.g. when the last trend change was from bearish market to bullish market and you are now in a choppy/ranging phase confirmed by e.g. Chop Zone or KAMA slope you want to do long trades.
Interpretation
The Z-score indicator is a momentum indicator which shows the number of standard deviations by which the value of a raw score (price/source) is above or below the mean value of what is being observed or measured. Easily explained, it is almost the same as Bollinger Bands with another visual representation form.
Signals
B -> Buy -> Z-score crosses above lower band
S -> Short -> Z-score crosses below upper band
BE -> Buy Exit -> Z-score crosses above 0
SE -> Sell Exit -> Z-score crosses below 0
If you were reading till here, thank you already. Now, follows a bunch of knowledge for people who don't know the concepts I talk about.
T3
The T3 moving average, short for "Tim Tillson's Triple Exponential Moving Average," is a technical indicator used in financial markets and technical analysis to smooth out price data over a specific period. It was developed by Tim Tillson, a software project manager at Hewlett-Packard, with expertise in Mathematics and Computer Science.
The T3 moving average is an enhancement of the traditional Exponential Moving Average (EMA) and aims to overcome some of its limitations. The primary goal of the T3 moving average is to provide a smoother representation of price trends while minimizing lag compared to other moving averages like Simple Moving Average (SMA), Weighted Moving Average (WMA), or EMA.
To compute the T3 moving average, it involves a triple smoothing process using exponential moving averages. Here's how it works:
Calculate the first exponential moving average (EMA1) of the price data over a specific period 'n.'
Calculate the second exponential moving average (EMA2) of EMA1 using the same period 'n.'
Calculate the third exponential moving average (EMA3) of EMA2 using the same period 'n.'
The formula for the T3 moving average is as follows:
T3 = 3 * (EMA1) - 3 * (EMA2) + (EMA3)
By applying this triple smoothing process, the T3 moving average is intended to offer reduced noise and improved responsiveness to price trends. It achieves this by incorporating multiple time frames of the exponential moving averages, resulting in a more accurate representation of the underlying price action.
JMA
The Jurik Moving Average (JMA) is a technical indicator used in trading to predict price direction. Developed by Mark Jurik, it’s a type of weighted moving average that gives more weight to recent market data rather than past historical data.
JMA is known for its superior noise elimination. It’s a causal, nonlinear, and adaptive filter, meaning it responds to changes in price action without introducing unnecessary lag. This makes JMA a world-class moving average that tracks and smooths price charts or any market-related time series with surprising agility.
In comparison to other moving averages, such as the Exponential Moving Average (EMA), JMA is known to track fast price movement more accurately. This allows traders to apply their strategies to a more accurate picture of price action.
Inverse Fisher Transform
The Inverse Fisher Transform is a transform used in DSP to alter the Probability Distribution Function (PDF) of a signal or in our case of indicators.
The result of using the Inverse Fisher Transform is that the output has a very high probability of being either +1 or –1. This bipolar probability distribution makes the Inverse Fisher Transform ideal for generating an indicator that provides clear buy and sell signals.
Hann Window
The Hann function (aka Hann Window) is named after the Austrian meteorologist Julius von Hann. It is a window function used to perform Hann smoothing.
Super Smoother
The Super Smoother uses a special mathematical process for the smoothing of data points.
The Super Smoother is a technical analysis indicator designed to be smoother and with less lag than a traditional moving average.
Adaptive Length
Length based on the dominant cycle length measured by a "dominant cycle measurement" algorithm.
Happy Trading!
Best regards,
simwai
---
Credits to
@cheatcountry
@everget
@loxx
@DasanC
@blackcat1402
Adaptive

RSI Volatility Bands [QuantraSystems]RSI Volatility Bands
Introduction
The RSI Volatility Bands indicator introduces a unique approach to market analysis by combining the traditional Relative Strength Index (RSI) with dynamic, volatility adjusted deviation bands. It is designed to provide a highly customizable method of trend analysis, enabling investors to analyze potential entry and exit points in a new and profound way.
The deviation bands are calculated and drawn in a manner which allows investors to view them as areas of dynamic support and resistance.
Legend
Upper and Lower Bands - A dynamic plot of the volatility-adjusted range around the current price.
Signals - Generated when the RSI volatility bands indicate a trend shift.
Case Study
The chart highlights the occurrence of false signals, emphasizing the need for caution when the bands are contracted and market volatility is low.
Juxtaposing this, during volatile market phases as shown, the indicator can effectively adapt to strong trends. This keeps an investor in a position even through a minor drawdown in order to exploit the entire price movement.
Recommended Settings
The RSI Volatility Bands are highly customisable and can be adapted to many assets with diverse behaviors.
The calibrations used in the above screenshots are as follows:
Source = close
RSI Length = 8
RSI Smoothing MA = DEMA
Bandwidth Type = DEMA
Bandwidth Length = 24
Bandwidth Smooth = 25
Methodology
The indicator first calculates the RSI of the price data, and applies a custom moving average.
The deviation bands are then calculated based upon the absolute difference between the RSI and its moving average - providing a unique volatility insight.
The deviation bands are then adjusted with another smoothing function, providing clear visuals of the RSI’s trend within a volatility-adjusted context.
rsiVal = ta.rsi(close, rsiLength)
rsiEma = ma(rsiMA, rsiVal, bandLength)
bandwidth = ma(bandMA, math.abs(rsiVal - rsiEma), bandLength)
upperBand = ma(bandMA, rsiEma + bandwidth, smooth)
lowerBand = ma(bandMA, rsiEma - bandwidth, smooth)
long = upperBand > 50 and not (lowerBand < lowerBand and lowerBand < 50)
short= not (upperBand > 50 and not (lowerBand < lowerBand and lowerBand < 50))
By dynamically adjusting to market conditions, the RSI trend bands offer a unique perspective on market trends, and reversal zones.
Backtesting ModuleDo you often find yourself creating new 'strategy()' scripts for each trading system? Are you unable to focus on generating new systems due to fatigue and time loss incurred in the process? Here's a potential solution: the 'Backtesting Module' :)
INTRODUCTION
Every trading system is based on four basic conditions: long entry, long exit, short entry and short exit (which are typically defined as boolean series in Pine Script).
If you can define the conditions generated by your trading system as a series of integers, it becomes possible to use these variables in different scripts in efficient ways. (Pine Script is a convenient language that allows you to use the integer output of one indicator as a source in another.)
The 'Backtesting Module' is a dynamic strategy script designed to adapt to your signals. It boasts two notable features:
⮞ It produces a backtest report using the entry and exit variables you define.
⮞ It not only serves for system testing but also to combine independent signals into a single system. (This functionality enables to create complex strategies and report on their success!)
The module tests Golden and Death cross signals by default, when you enter your own conditions the default signals will be neutralized. The methodology is described below.
PREPARATION
There are three simple steps to connect your own indicator to the Module.
STEP 1
Firstly, you must define entry and exit variables in your own script. Let's elucidate it with a straightforward example. Consider a system generating long and short signals based on the intersections of two moving averages. Consequently, our conditions would be as follows:
// Signals
long = ta.crossover(ta.sma(close, 14), ta.sma(close, 28))
short = ta.crossunder(ta.sma(close, 14), ta.sma(close, 28))
Now, the question is: How can we convert boolean variables into integer variables? The answer is conditional ternary block, defined as follows:
// Entry & Exit
long_entry = long ? 1 : 0
long_exit = short ? 1 : 0
short_entry = short ? 1 : 0
short_exit = long ? 1 : 0
The mechanics of the Entry & Exit variables are simple. The variable takes on a value of 1 when your trading system generates the signal and if your system does not produce any signal, variable returns 0. In this example, you see how exit signals can be generated in a trading system that only contains entry signals. If you have a system with original exit signals, you can also use them directly. (Please mind the NOTES section below).
STEP 2
To utilize the Entry & Exit variables as source in another script, they must be plotted on the chart. Therefore, the final detail to include in the script containing your trading system would be as follows:
// Plot The Output
plot(long_entry, "Long Entry", display=display.data_window, editable=false)
plot(long_exit, "Long Exit", display=display.data_window, editable=false)
plot(short_entry, "Short Entry", display=display.data_window, editable=false)
plot(short_exit, "Short Exit", display=display.data_window, editable=false)
STEP 3
Now, we are ready to test the system! Load the Backtesting Module indicator onto the chart along with your trading system/indicator. Then set the outputs of your system (Long Entry, Long Exit, Short Entry, Short Exit) as source in the module. That's it.
FEATURES & ORIGINALITY
⮞ Primarily, this script has been created to provide you with an easy and practical method when testing your trading system.
⮞ I thought it might be nice to visualize a few useful results. The Backtesting Module provides insights into the outcomes of both long and short trades by computing the number of trades and the success percentage.
⮞ Through the 'Trade' parameter, users can specify the market direction in which the indicator is permitted to initiate positions.
⮞ Users have the flexibility to define the date range for the test.
⮞ There are optional features allowing users to plot entry prices on the chart and customize bar colors.
⮞ The report and the test date range are presented in a table on the chart screen. The entry price can be monitored in the data window.
⮞ Note that results are based on realized returns, and the open trade is not included in the displayed results. (The only exception is the 'Unrealized PNL' result in the table.)
STRATEGY SETTINGS
The default parameters are as follows:
⮞ Initial Balance : 10000 (in units of currency)
⮞ Quantity : 10% of equity
⮞ Commission : 0.04%
⮞ Slippage : 0
⮞ Dataset : All bars in the chart
For a realistic backtest result, you should size trades to only risk sustainable amounts of equity. Do not risk more than 5-10% on a trade. And ALWAYS configure your commission and slippage parameters according to pessimistic scenarios!
NOTES
⮞ This script is intended solely for development purposes. And it'll will be available for all the indicators I publish.
⮞ In this version of the module, all order types are designed as market orders. The exit size is the sum of the entry size.
⮞ As your trading conditions grow more intricate, you might need to define the outputs of your system in alternative ways. The method outlined in this description is tailored for straightforward signal structures.
⮞ Additionally, depending on the structure of your trading system, the backtest module may require further development. This encompasses stop-loss, take-profit, specific exit orders, quantity, margin and risk management calculations. I am considering releasing improvements that consider these options in future versions.
⮞ An example of how complex trading signals can be generated is the OTT Collection. If you're interested in seeing how the signals are constructed, you can use the link below.
THANKS
Special thanks to PineCoders for their valuable moderation efforts.
I hope this will be a useful example for the TradingView community...
DISCLAIMER
This is just an indicator, nothing more. It is provided for informational and educational purposes exclusively. The utilization of this script does not constitute professional or financial advice. The user solely bears the responsibility for risks associated with script usage. Do not forget to manage your risk. And trade as safely as possible. Best of luck!

Advanced Dynamic Threshold RSI [Elysian_Mind]Advanced Dynamic Threshold RSI Indicator
Overview
The Advanced Dynamic Threshold RSI Indicator is a powerful tool designed for traders seeking a unique approach to RSI-based signals. This indicator combines traditional RSI analysis with dynamic threshold calculation and optional Bollinger Bands to generate weighted buy and sell signals.
Features
Dynamic Thresholds: The indicator calculates dynamic thresholds based on market volatility, providing more adaptive signal generation.
Performance Analysis: Users can evaluate recent price performance to further refine signals. The script calculates the percentage change over a specified lookback period.
Bollinger Bands Integration: Optional integration of Bollinger Bands for additional confirmation and visualization of potential overbought or oversold conditions.
Customizable Settings: Traders can easily customize key parameters, including RSI length, SMA length, lookback bars, threshold multiplier, and Bollinger Bands parameters.
Weighted Signals: The script introduces a unique weighting mechanism for signals, reducing false positives and improving overall reliability.
Underlying Calculations and Methods
1. Dynamic Threshold Calculation:
The heart of the Advanced Dynamic Threshold RSI Indicator lies in its ability to dynamically calculate thresholds based on multiple timeframes. Let's delve into the technical details:
RSI Calculation:
For each specified timeframe (1-hour, 4-hour, 1-day, 1-week), the Relative Strength Index (RSI) is calculated using the standard 14-period formula.
SMA of RSI:
The Simple Moving Average (SMA) is applied to each RSI, resulting in the smoothing of RSI values. This smoothed RSI becomes the basis for dynamic threshold calculations.
Dynamic Adjustment:
The dynamically adjusted threshold for each timeframe is computed by adding a constant value (5 in this case) to the respective SMA of RSI. This dynamic adjustment ensures that the threshold reflects changing market conditions.
2. Weighted Signal System:
To enhance the precision of buy and sell signals, the script introduces a weighted signal system. Here's how it works technically:
Signal Weighting:
The script assigns weights to buy and sell signals based on the crossover and crossunder events between RSI and the dynamically adjusted thresholds. If a crossover event occurs, the weight is set to 2; otherwise, it remains at 1.
Signal Combination:
The weighted buy and sell signals from different timeframes are combined using logical operations. A buy signal is generated if the product of weights from all timeframes is equal to 2, indicating alignment across timeframe.
3. Experimental Enhancements:
The Advanced Dynamic Threshold RSI Indicator incorporates experimental features for educational exploration. While not intended as proven strategies, these features aim to offer users a glimpse into unconventional analysis. Some of these features include Performance Calculation, Volatility Calculation, Dynamic Threshold Calculation Using Volatility, Bollinger Bands Module, Weighted Signal System Incorporating New Features.
3.1 Performance Calculation:
The script calculates the percentage change in the price over a specified lookback period (variable lookbackBars). This provides a measure of recent performance.
pctChange(src, length) =>
change = src - src
pctChange = (change / src ) * 100
recentPerformance1H = pctChange(close, lookbackBars)
recentPerformance4H = pctChange(request.security(syminfo.tickerid, "240", close), lookbackBars)
recentPerformance1D = pctChange(request.security(syminfo.tickerid, "1D", close), lookbackBars)
3.2 Volatility Calculation:
The script computes the standard deviation of the closing price to measure volatility.
volatility1H = ta.stdev(close, 20)
volatility4H = ta.stdev(request.security(syminfo.tickerid, "240", close), 20)
volatility1D = ta.stdev(request.security(syminfo.tickerid, "1D", close), 20)
3.3 Dynamic Threshold Calculation Using Volatility:
The dynamic thresholds for RSI are calculated by adding a multiplier of volatility to 50.
dynamicThreshold1H = 50 + thresholdMultiplier * volatility1H
dynamicThreshold4H = 50 + thresholdMultiplier * volatility4H
dynamicThreshold1D = 50 + thresholdMultiplier * volatility1D
3.4 Bollinger Bands Module:
An additional module for Bollinger Bands is introduced, providing an option to enable or disable it.
// Additional Module: Bollinger Bands
bbLength = input(20, title="Bollinger Bands Length")
bbMultiplier = input(2.0, title="Bollinger Bands Multiplier")
upperBand = ta.sma(close, bbLength) + bbMultiplier * ta.stdev(close, bbLength)
lowerBand = ta.sma(close, bbLength) - bbMultiplier * ta.stdev(close, bbLength)
3.5 Weighted Signal System Incorporating New Features:
Buy and sell signals are generated based on the dynamic threshold, recent performance, and Bollinger Bands.
weightedBuySignal = rsi1H > dynamicThreshold1H and rsi4H > dynamicThreshold4H and rsi1D > dynamicThreshold1D and crossOver1H
weightedSellSignal = rsi1H < dynamicThreshold1H and rsi4H < dynamicThreshold4H and rsi1D < dynamicThreshold1D and crossUnder1H
These features collectively aim to provide users with a more comprehensive view of market dynamics by incorporating recent performance and volatility considerations into the RSI analysis. Users can experiment with these features to explore their impact on signal accuracy and overall indicator performance.
Indicator Placement for Enhanced Visibility
Overview
The design choice to position the "Advanced Dynamic Threshold RSI" indicator both on the main chart and beneath it has been carefully considered to address specific challenges related to visibility and scaling, providing users with an improved analytical experience.
Challenges Faced
1. Differing Scaling of RSI Results:
RSI values for different timeframes (1-hour, 4-hour, and 1-day) often exhibit different scales, especially in markets like gold.
Attempting to display these RSIs on the same chart can lead to visibility issues, as the scaling differences may cause certain RSI lines to appear compressed or nearly invisible.
2. Candlestick Visibility vs. RSI Scaling:
Balancing the visibility of candlestick patterns with that of RSI values posed a unique challenge.
A single pane for both candlesticks and RSIs may compromise the clarity of either, particularly when dealing with assets that exhibit distinct volatility patterns.
Design Solution
Placing the buy/sell signals above/below the candles helps to maintain a clear association between the signals and price movements.
By allocating RSIs beneath the main chart, users can better distinguish and analyze the RSI values without interference from candlestick scaling.
Doubling the scaling of the 1-hour RSI (displayed in blue) addresses visibility concerns and ensures that it remains discernible even when compared to the other two RSIs: 4-hour RSI (orange) and 1-day RSI (green).
Bollinger Bands Module is optional, but is turned on as default. When the module is turned on, the users can see the upper Bollinger Band (green) and lower Bollinger Band (red) on the main chart to gain more insight into price actions of the candles.
User Flexibility
This dual-placement approach offers users the flexibility to choose their preferred visualization:
The main chart provides a comprehensive view of buy/sell signals in relation to candlestick patterns.
The area beneath the chart accommodates a detailed examination of RSI values, each in its own timeframe, without compromising visibility.
The chosen design optimizes visibility and usability, addressing the unique challenges posed by differing RSI scales and ensuring users can make informed decisions based on both price action and RSI dynamics.
Usage
Installation
To ensure you receive updates and enhancements seamlessly, follow these steps:
Open the TradingView platform.
Navigate to the "Indicators" tab in the top menu.
Click on "Community Scripts" and search for "Advanced Dynamic Threshold RSI Indicator."
Select the indicator from the search results and click on it to add to your chart.
This ensures that any future updates to the indicator can be easily applied, keeping you up-to-date with the latest features and improvements.
Review Code
Open TradingView and navigate to the Pine Editor.
Copy the provided script.
Paste the script into the Pine Editor.
Click "Add to Chart."
Configuration
The indicator offers several customizable settings:
RSI Length: Defines the length of the RSI calculation.
SMA Length: Sets the length of the SMA applied to the RSI.
Lookback Bars: Determines the number of bars used for recent performance analysis.
Threshold Multiplier: Adjusts the multiplier for dynamic threshold calculation.
Enable Bollinger Bands: Allows users to enable or disable Bollinger Bands integration.
Interpreting Signals
Buy Signal: Generated when RSI values are above dynamic thresholds and a crossover occurs.
Sell Signal: Generated when RSI values are below dynamic thresholds and a crossunder occurs.
Additional Information
The indicator plots scaled RSI lines for 1-hour, 4-hour, and 1-day timeframes.
Users can experiment with additional modules, such as machine-learning simulation, dynamic real-life improvements, or experimental signal filtering, depending on personal preferences.
Conclusion
The Advanced Dynamic Threshold RSI Indicator provides traders with a sophisticated tool for RSI-based analysis, offering a unique combination of dynamic thresholds, performance analysis, and optional Bollinger Bands integration. Traders can customize settings and experiment with additional modules to tailor the indicator to their trading strategy.
Disclaimer: Use of the Advanced Dynamic Threshold RSI Indicator
The Advanced Dynamic Threshold RSI Indicator is provided for educational and experimental purposes only. The indicator is not intended to be used as financial or investment advice. Trading and investing in financial markets involve risk, and past performance is not indicative of future results.
The creator of this indicator is not a financial advisor, and the use of this indicator does not guarantee profitability or specific trading outcomes. Users are encouraged to conduct their own research and analysis and, if necessary, consult with a qualified financial professional before making any investment decisions.
It is important to recognize that all trading involves risk, and users should only trade with capital that they can afford to lose. The Advanced Dynamic Threshold RSI Indicator is an experimental tool that may not be suitable for all individuals, and its effectiveness may vary under different market conditions.
By using this indicator, you acknowledge that you are doing so at your own risk and discretion. The creator of this indicator shall not be held responsible for any financial losses or damages incurred as a result of using the indicator.
Kind regards,
Ely

Optimal Length BackTester [YinYangAlgorithms]This Indicator allows for a ‘Optimal Length’ to be inputted within the Settings as a Source. Unlike most Indicators and/or Strategies that rely on either Static Lengths or Internal calculations for the length, this Indicator relies on the Length being derived from an external Indicator in the form of a Source Input.
This may not sound like much, but this application may allows limitless implementations of such an idea. By allowing the input of a Length within a Source Setting you may have an ‘Optimal Length’ that adjusts automatically without the need for manual intervention. This may allow for Traditional and Non-Traditional Indicators and/or Strategies to allow modifications within their settings as well to accommodate the idea of this ‘Optimal Length’ model to create an Indicator and/or Strategy that adjusts its length based on the top performing Length within the current Market Conditions.
This specific Indicator aims to allow backtesting with an ‘Optimal Length’ inputted as a ‘Source’ within the Settings.
This ‘Optimal Length’ may be used to display and potentially optimize multiple different Traditional Indicators within this BackTester. The following Traditional Indicators are included and available to be backtested with an ‘Optimal Length’ inputted as a Source in the Settings:
Moving Average; expressed as either a: Simple Moving Average, Exponential Moving Average or Volume Weighted Moving Average
Bollinger Bands; expressed based on the Moving Average Type
Donchian Channels; expressed based on the Moving Average Type
Envelopes; expressed based on the Moving Average Type
Envelopes Adjusted; expressed based on the Moving Average Type
All of these Traditional Indicators likewise may be displayed with multiple ‘Optimal Lengths’. They have the ability for multiple different ‘Optimal Lengths’ to be inputted and displayed, such as:
Fast Optimal Length
Slow Optimal Length
Neutral Optimal Length
By allowing for the input of multiple different ‘Optimal Lengths’ we may express the ‘Optimal Movement’ of such an expressed Indicator based on different Time Frames and potentially also movement based on Fast, Slow and Neutral (Inclusive) Lengths.
This in general is a simple Indicator that simply allows for the input of multiple different varieties of ‘Optimal Lengths’ to be displayed in different ways using Tradition Indicators. However, the idea and model of accepting a Length as a Source is unique and may be adopted in many different forms and endless ideas.
Tutorial:
You may add an ‘Optimal Length’ within the Settings as a ‘Source’ as followed in the example above. This Indicator allows for the input of a:
Neutral ‘Optimal Length’
Fast ‘Optimal Length’
Slow ‘Optimal Length’
It is important to account for all three as they generally encompass different min/max length values and therefore result in varying ‘Optimal Length’s’.
For instance, say you’re calculating the ‘Optimal Length’ and you use:
Min: 1
Max: 400
This would therefore be scanning for 400 (inclusive) lengths.
As a general way of calculating you may assume the following for which lengths are being used within an ‘Optimal Length’ calculation:
Fast: 1 - 199
Slow: 200 - 400
Neutral: 1 - 400
This allows for the calculation of a Fast and Slow length within the predetermined lengths allotted. However, it likewise allows for a Neutral length which is inclusive to all lengths alloted and may be deemed the ‘Most Accurate’ for these reasons. However, just because the Neutral is inclusive to all lengths, doesn’t mean the Fast and Slow lengths are irrelevant. The Fast and Slow length inputs may be useful for seeing how specifically zoned lengths may fair, and likewise when they cross over and/or under the Neutral ‘Optimal Length’.
This Indicator features the ability to display multiple different types of Traditional Indicators within the ‘Display Type’.
We will go over all of the different ‘Display Types’ with examples on how using a Fast, Slow and Neutral length would impact it:
Simple Moving Average:
In this example above have the Fast, Slow and Neutral Optimal Length formatted as a Slow Moving Average. The first example is on the 15 minute Time Frame and the second is on the 1 Day Time Frame, demonstrating how the length changes based on the Time Frame and the effects it may have.
Here we can see that by inputting ‘Optimal Lengths’ as a Simple Moving Average we may see moving averages that change over time with their ‘Optimal Lengths’. These lengths may help identify Support and/or Resistance locations. By using an 'Optimal Length' rather than a static length, we may create a Moving Average which may be more accurate as it attempts to be adaptive to current Market Conditions.
Bollinger Bands:
Bollinger Bands are a way to see a Simple Moving Average (SMA) that then uses Standard Deviation to identify how much deviation has occurred. This Deviation is then Added and Subtracted from the SMA to create the Bollinger Bands which help Identify possible movement zones that are ‘within range’. This may mean that the price may face Support / Resistance when it reaches the Outer / Inner bounds of the Bollinger Bands. Likewise, it may mean the Price is ‘Overbought’ when outside and above or ‘Underbought’ when outside and below the Bollinger Bands.
By applying All 3 different types of Optimal Lengths towards a Traditional Bollinger Band calculation we may hope to see different ranges of Bollinger Bands and how different lookback lengths may imply possible movement ranges on both a Short Term, Long Term and Neutral perspective. By seeing these possible ranges you may have the ability to identify more levels of Support and Resistance over different lengths and Trading Styles.
Donchian Channels:
Above you’ll see two examples of Machine Learning: Optimal Length applied to Donchian Channels. These are displayed with both the 15 Minute Time Frame and the 1 Day Time Frame.
Donchian Channels are a way of seeing potential Support and Resistance within a given lookback length. They are a way of withholding the High’s and Low’s of a specific lookback length and looking for deviation within this length. By applying a Fast, Slow and Neutral Machine Learning: Optimal Length to these Donchian Channels way may hope to achieve a viable range of High’s and Low’s that one may use to Identify Support and Resistance locations for different ranges of Optimal Lengths and likewise potentially different Trading Strategies.
Envelopes / Envelopes Adjusted:
Envelopes are an interesting one in the sense that they both may be perceived as useful; however we deem that with the use of an ‘Optimal Length’ that the ‘Envelopes Adjusted’ may work best. We will start with examples of the Traditional Envelope then showcase the Adjusted version.
Envelopes:
As you may see, a Traditional form of Envelopes even produced with a Machine Learning: Optimal Length may not produce optimal results. Unfortunately this may occur with some Traditional Indicators and they may need some adjustments as you’ll notice with the ‘Envelopes Adjusted’ version. However, even without the adjustments, these Envelopes may be useful for seeing ‘Overbought’ and ‘Oversold’ locations within a Machine Learning: Optimal Length standpoint.
Envelopes Adjusted:
By adding an adjustment to these Envelopes, we may hope to better reflect our Optimal Length within it. This is caused by adding a ratio reflection towards the current length of the Optimal Length and the max Length used. This allows for the Fast and Neutral (and potentially Slow if Neutral is greater) to achieve a potentially more accurate result.
Envelopes, much like Bollinger Bands are a way of seeing potential movement zones along with potential Support and Resistance. However, unlike Bollinger Bands which are based on Standard Deviation, Envelopes are based on percentages +/- from the Simple Moving Average.
We will conclude our Tutorial here. Hopefully this has given you some insight into how useful adding a ‘Optimal Length’ within an external (secondary) Indicator as a Source within the Settings may be. Likewise, how useful it may be for automation sake in the sense that when the ‘Optimal Length’ changes, it doesn’t rely on an alert where you need to manually update it yourself; instead it will update Automatically and you may reap the benefits of such with little manual input needed (aside from the initial setup).
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

Fibonacci HH LL TRAMA BandLuxAlgo's Trend Moving Adaptive Moving Average was used as a reference to create bands by reading the highest and lowest prices of past bars based on Fibonacci numbers and then multiplying them by the Fibonacci ratio.
LuxAlgo/ LuxAlgo/
In particular, the so-called TRAMA is characterized by its adaptation to the average of the highest and lowest prices over a specific period of time and is used to identify support/resistance.
In order to apply this feature to the maximum extent possible, I used the high or low prices as the source of input, rather than the closing price.
For example,
src = high
not original like
src = close
In addition, I created 6 levels by multiplying the Fibonacci ratio
//Midline
mah = ama1
mal = ama2
m = (mah + mal)/2
//Half Mean Range
dist = (mah - mal)/2
//Levels
h6 = m + dist * 11.089
h5 = m + dist * 6.857
h4 = m + dist * 4.235
h3 = m + dist * 2.618
h2 = m + dist * 1.618
h1 = m + dist * 0.618
l1 = m - dist * 0.618
l2 = m - dist * 1.618
l3 = m - dist * 2.618
l4 = m - dist * 4.235
l5 = m - dist * 6.857
l6 = m - dist * 11.089
If you want to use it for scalping, such as 15 minutes, you can include Fibonacci numbers such as 21,34,55 for a quick reaction type to detect the trend. Also, by including Fibonacci numbers such as 89,144,233, you can see where you stand in the larger trend. Some examples are included below.
For Investors
BTCUSDT 1day Chart Fibonacci number "55"
For Daytraders
BTCUSDT 4hour Chart Fibonacci number "34"
For Scalpers
BTCUSDT 15min Chart Fibonacci number "55"
BTCUSDT 15min Chart Fibonacci number "89"
BTCUSDT 15min Chart Fibonacci number "233"
Fibonacci numbers are 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, etc.,
Fibonacci ratios are 0.618, 1.618, 2.618, 4.236, 6.854, 11.089, etc.,
PA-Adaptive Hull Parabolic [Loxx]The PA-Adaptive Hull Parabolic is not your typical trading indicator. It synthesizes the computational brilliance of two famed technicians: John Ehlers and John Hull. Let's demystify its sophistication.
█ Ehlers' Phase Accumulation
John Ehlers is well-known in the trading community for his digital signal processing approach to market data. One of his standout techniques is phase accumulation. This method identifies the dominant cycle in the market by accumulating the phases of individual cycles. By doing so, it "adapts" to real-time market conditions.
Here's the brilliance of phase accumulation in this code
The indicator doesn't merely use a static look-back period. Instead, it dynamically determines the dominant market cycle through phase accumulation.
The calcComp function, rooted in Ehlers' methodology, provides a complex computation using a digital signal processing approach to filter out market noise and pinpoint the current cycle's frequency.
By measuring and adapting to the instantaneous period of the market, it ensures that the indicator remains relevant, especially in non-stationary market conditions.
Hull's Moving Average
John Hull introduced the Hull Moving Average (HMA) aiming to reduce lag and improve smoothing. The HMA's essence lies in its weighted average computation, prioritizing more recent prices.
This code takes an adaptive twist on the HMA
Instead of a fixed period, the HMA uses the dominant cycle length derived from Ehlers' phase accumulation. This makes the HMA not just fast and smooth, but also adaptive to the dominant market rhythm.
The intricate iLwmp function in the script provides this adaptive HMA computation. It's a weighted moving average, but its length isn't static; it's based on the previously determined dominant market cycle.
█ Trading Insights
The indicator paints the bars to represent the immediate trend: green for bullish and red for bearish.
Entry points, both long ("L") and short ("S"), are presented visually. These are derived from crossovers of the adaptive HMA, a clear indication of a potential shift in the trend.
Additionally, alert conditions are set, ready to notify a trader when these crossovers occur, ensuring real-time actionable insights.
█ Conclusion
The PA-Adaptive Hull Parabolic is a masterclass in advanced technical indicator design. By marrying John Ehlers' adaptive phase accumulation with John Hull's HMA, it creates a dynamic, responsive, and precise tool for traders. It's not just about capturing the trend; it's about understanding the very rhythm of the market.
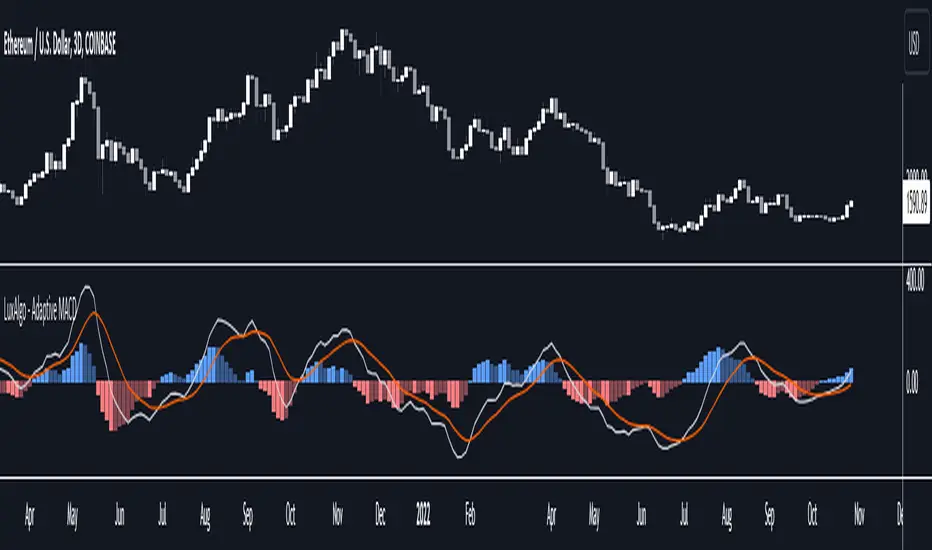
Adaptive MACD [LuxAlgo]The Adaptive MACD indicator is an adaptive version of the popular Moving Average Convergence Divergence (MACD) oscillator, returning longer-term variations during trending markets and cyclic variations during ranging markets while filtering out noisy variations.
🔶 USAGE
The proposed oscillator contains all the elements within a regular MACD, such as a signal line and histogram. A MACD value above 0 would indicate up-trending variations, while a value under 0 would be indicating down-trending variations.
Just like most oscillators, our proposed Adaptive MACD is able to return divergences with the price.
As we can see in the image above ranging markets will make the Adaptive MACD more conservative toward more cyclical conservations, filtering out both noise and longer-term variations. However, when longer-term variations (such as in a trending market) are prominent the oscillator will conserve longer-term variations.
The R2 Period setting determines when trending/ranging markets are detected, with higher values returning indications for longer intervals.
The fast and slow settings will act similarly to the regular MACD, however, closer values will return more cyclical outputs.
The image above compares our proposed MACD (top) with a regular MACD (bottom), both using fast = 19 and slow = 20 .
🔶 DETAILS
It is common to be solely interested in the trend component when the market is trending, however, during a ranging market it is more common to observe a more prominent cyclical/noise component. We want to be able to preserve one of the components at the appropriate market conditions, however, the regular MACD lack the ability to preserve cyclical component with high accuracy.
The MACD is an IIR bandpass filter. In order to obtain a lower passband bandwidth and a more symmetrical magnitude response (which would allow to conserve more precise cyclical variations) we can directly change the system calculation:
y = (price - price ) × g + ((1 - a1) + (1 - a2)) × y - (1 - a1) × (1 - a2) × y
where:
a1 = 2/(fast + 1)
a2 = 2/(slow + 1)
g = a1 - a2
Using division instead of multiplication on the second feedback weight allows further weighting the 2 samples lagged output, returning a more desirable magnitude response with a higher degree of filtering on both ends of the spectrum as shown in the image below:
We are interested in conserving cycles during ranging markets, and longer-term variations during trending markets, we can do this by interpolating between our two filter coefficients:
α × + (1 - α) ×
where 1 > α > 0 . α is measuring if the market is trending or ranging, with values closer to 1 indicating a trending market. We see that for higher values of α the original coefficient of the MACD is used. The image below shows various magnitude responses given multiple values of α :
We use a rolling R-Squared as α , this measurement has the benefit of indicating if the market is trending or ranging, as well as being constrained within range (0, 1), and having a U-shaped distribution.
If you are interested to learn more about the MACD see:
🔶 SETTINGS
R2 Period: Calculation window of the R-Squared.
Fast: Fast period for the calculation of the Adaptive MACD, lower values will return more noisy results.
Slow: Slow period for the calculation of the Adaptive MACD, higher values will return result with longer-term conserved variations.
Signal: Period of the EMA applied to the Adaptive MACD.
adaptive_mfi
█ Description
Money flow an indexed value-based price and volume for the specified input length (lookback period). In summary, a momentum indicator that attempt to measure the flow of money (identify buying/selling pressure) through the asset within a specified period of time. MFI will oscillate between 0 to 100, oftentimes comprehend the analysis with oversold (20) or overbought (80) level, and a divergence that spotted to signaling a further change in trend/direction. As similar to many other indicators that use length (commonly a fixed value) as an input parameter, can be optimized by applied an adaptive filter (Ehlers), to solve the measuring cycle period. In this indicator, the adaptive measure of dominant cycle as an input parameter for the lookback period/n, will be applied to the money flow index.
█ Money Flow Index
mfi = 100 - (100/(1 + money_flow_ratio))
where:
n = int(dominant_cycle)
money_flow_ratio = n positive raw_money_flow / n negative raw_money_flow
raw_money_flow = typical_price * volume
typical_price = hlc3
█ Feature
The indicator will have a specified default parameter of: hp_period = 48; source = ohlc4
Horizontal line indicates positive/negative money flow
MFI Color Scheme: Solid; Normalized

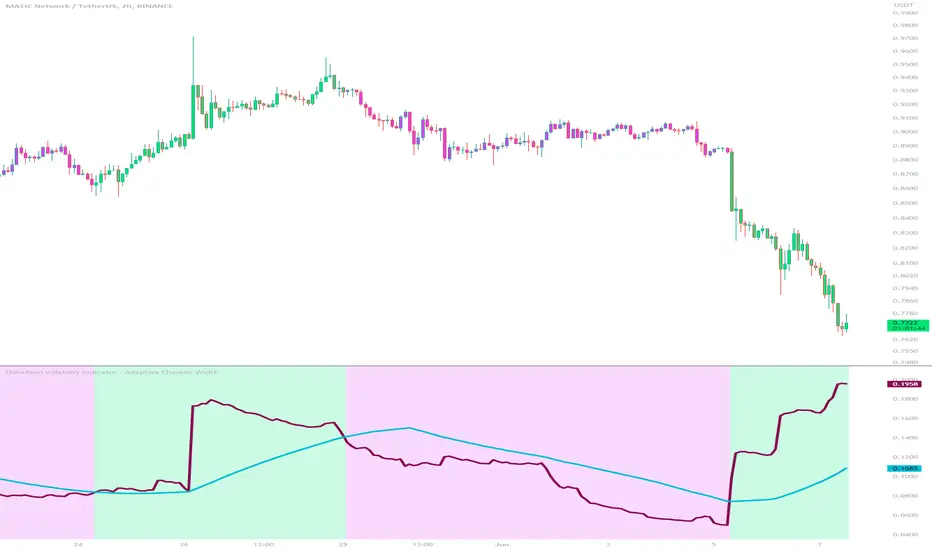
Donchian Volatility Indicator - Adaptive Channel WidthThis indicator is designed to help traders assess and analyze market volatility. By calculating the width of the Donchian channels, it provides valuable insights into the range of price movements over a specified period. This indicator helps traders identify periods of high and low volatility, enabling them to make more informed trading decisions.
The indicator is based on the concept of Donchian channels, which consist of the highest high and lowest low over a specified lookback period. The channel width is calculated as the difference between the upper and lower channels. A wider channel indicates higher volatility, suggesting potentially larger price movements and increased trading opportunities. On the other hand, a narrower channel suggests lower volatility, indicating a relatively calmer market environment with potentially fewer trading opportunities.
The adaptive aspect of the indicator refers to its ability to adjust the width of the channels dynamically based on market conditions. The indicator calculates the width of the channels using the Average True Range (ATR) indicator, which measures the average range of price movements over a specified period. By multiplying the ATR value with the user-defined ATR multiplier, the indicator adapts the width of the channels to reflect the current level of volatility. During periods of higher volatility, the channels expand to accommodate larger price movements, providing a broader range for assessing volatility. Conversely, during periods of lower volatility, the channels contract, reflecting the narrower price ranges and signaling a decrease in volatility. This adaptive nature allows traders to have a flexible and responsive measure of volatility, ensuring that the indicator reflects the current market conditions accurately.
To provide further insights, the indicator includes a signal line. The signal line is derived from the channel width and is calculated as a simple moving average over a specified signal period. This signal line acts as a reference level, allowing traders to compare the current channel width with the average width over a given time frame. By assessing whether the current channel width is above or below the signal line, traders can gain additional context on the volatility level in the market.
The colors used in the Donchian Volatility Indicator - Adaptive Channel Width play a vital role in visualizing the volatility levels:
-- Lime Color : When the channel width is above the signal line, it is colored lime. This color signifies that volatility has entered the market, indicating potentially higher price movements and increased trading opportunities. Traders can pay closer attention to the lime-colored channel width as it may suggest favorable conditions for trend-following or breakout trading strategies.
-- Fuchsia Color : When the channel width is below the signal line, it is colored fuchsia. This color represents relatively low volatility, suggesting a calmer market environment with potentially fewer trading opportunities. Traders may consider adjusting their strategies during periods of low volatility, such as employing range-bound or mean-reversion strategies.
-- Aqua Color : The signal line is represented by the aqua color. This color allows traders to easily identify the signal line amidst the channel width. The aqua color provides a visual reference for the average channel width and helps traders assess whether the current width is above or below this average.
The Donchian Volatility Indicator - Adaptive Channel Width has several practical applications for traders:
-- Volatility Assessment : Traders can use this indicator to assess the level of volatility in the market. By observing the width of the Donchian channels and comparing it to the signal line, they can determine whether the current volatility is relatively high or low. This information helps traders set appropriate expectations and adjust their trading strategies accordingly.
-- Breakout Trading : Wide channel widths may indicate an increased likelihood of price breakouts. Traders can use the Donchian Volatility Indicator - Adaptive Channel Width to identify potential breakout opportunities. When the channel width exceeds the signal line, it suggests a higher probability of significant price movements, potentially signaling a breakout. Traders may consider entering trades in the direction of the breakout.
-- Risk Management : The indicator can assist in setting appropriate stop-loss levels based on the current volatility. During periods of high volatility (lime-colored channel width), wider stop-loss orders may be warranted to account for larger price swings. Conversely, during periods of low volatility (fuchsia-colored channel width), narrower stop-loss orders may be appropriate to limit risk in a more range-bound market.
While the Donchian Volatility Indicator - Adaptive Channel Width is a valuable tool, it is important to consider its limitations:
-- Lagging Indicator : The indicator relies on historical price data, making it a lagging indicator. It provides insights based on past price movements and may not capture sudden changes or shifts in volatility. Traders should be aware that the indicator may not generate real-time signals and should be used in conjunction with other indicators and analysis tools.
-- False Signals : Like any technical indicator, the Donchian Volatility Indicator - Adaptive Channel Width is not immune to generating false signals. Traders should exercise caution and use additional analysis to confirm the signals generated by the indicator. Considering the broader market context and employing risk management techniques can help mitigate the impact of false signals.
-- Market Conditions : Market conditions can vary, and volatility levels can differ across different assets and timeframes. Traders should adapt their strategies and consider other market factors when interpreting the signals provided by the indicator. It is crucial to avoid relying solely on the indicator and to incorporate a comprehensive analysis of the market environment.
In conclusion, this indicator is a powerful tool for assessing market volatility. By examining the width of the Donchian channels and comparing it to the signal line, traders can gain insights into the level of volatility and adjust their trading strategies accordingly. The color-coded representation of the channel width and signal line allows for easy visualization and interpretation of the volatility dynamics. Traders should utilize this indicator as part of a broader trading approach, incorporating other technical analysis tools and considering market conditions for a comprehensive assessment of market volatility.
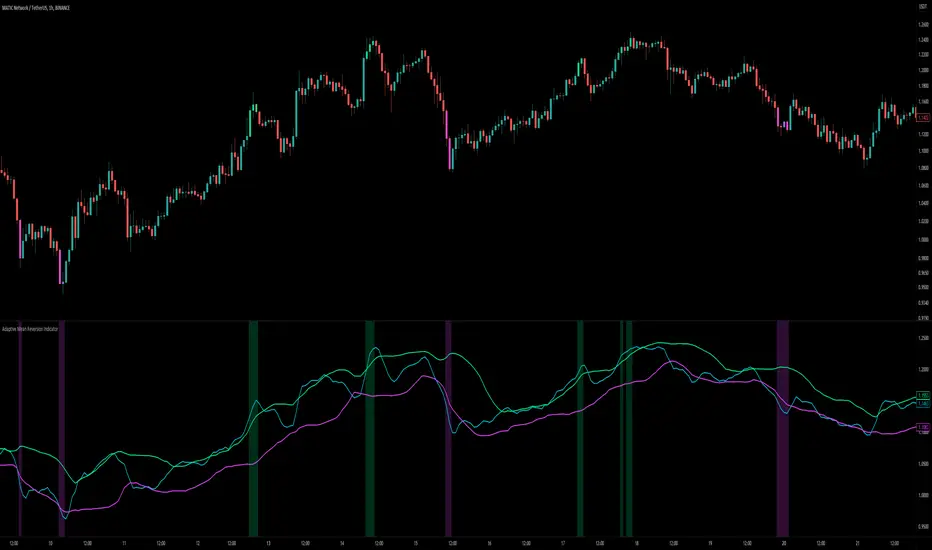
Adaptive Mean Reversion IndicatorThe Adaptive Mean Reversion Indicator is a tool for identifying mean reversion trading opportunities in the market. The indicator employs a dynamic approach by adapting its parameters based on the detected market regime, ensuring optimal performance in different market conditions.
To determine the market regime, the indicator utilizes a volatility threshold. By comparing the average true range (ATR) over a 14-period to the specified threshold, it determines whether the market is trending or ranging. This information is crucial as it sets the foundation for parameter optimization.
The parameter optimization process is an essential step in the indicator's calculation. It dynamically adjusts the lookback period and threshold level based on the identified market regime. In trending markets, a longer lookback period and higher threshold level are chosen to capture extended trends. In ranging markets, a shorter lookback period and lower threshold level are used to identify mean reversion opportunities within a narrower price range.
The mean reversion calculation lies at the core of this indicator. It starts with computing the mean value using the simple moving average (SMA) over the selected lookback period. This represents the average price level. The deviation is then determined by calculating the standard deviation of the closing prices over the same lookback period. The upper and lower bands are derived by adding and subtracting the threshold level multiplied by the deviation from the mean, respectively. These bands serve as dynamic levels that define potential overbought and oversold areas.
In real-time, the indicator's adaptability shines through. If the market is trending, the adaptive mean is set to the calculated mean value. The adaptive upper and lower bands are adjusted by scaling the threshold level with a factor of 0.75. This adjustment allows the indicator to be less sensitive to minor price fluctuations during trending periods, providing more robust mean reversion signals. In ranging market conditions, the regular mean, upper band, and lower band are used as they are more suited to capture mean reversion within a confined price range.
The signal generation component of the indicator identifies potential trading opportunities based on the relationship between the current close price and the adaptive upper and lower bands. If the close price is above the adaptive upper band, it suggests a potential short entry opportunity (-1). Conversely, if the close price is below the adaptive lower band, it indicates a potential long entry opportunity (1). When the close price is within the range defined by the adaptive upper and lower bands, no clear trading signal is generated (0).
To further strengthen the quality of signals, the indicator introduces a confluence condition based on the RSI. When the RSI exceeds the threshold levels of 70 or falls below the threshold level of 30, it indicates a strong momentum condition. By incorporating this confluence condition, the indicator ensures that mean reversion signals align with the prevailing market momentum. It reduces the likelihood of false signals and provides traders with added confidence when entering trades.
The indicator offers alert conditions to notify traders of potential trading opportunities. Alert conditions are set to trigger when a potential long entry signal (1) or a potential short entry signal (-1) aligns with the confluence condition. These alerts allow traders to stay informed about favorable mean reversion setups, even when they are not actively monitoring the charts. By leveraging alerts, traders can efficiently manage their time and take advantage of market opportunities.
To enhance visual interpretation, the indicator incorporates background coloration that provides valuable insights into the prevailing market conditions. When the indicator generates a potential short entry signal (-1) that aligns with the confluence condition, the background color is set to lime. This color suggests a bullish trend that is potentially reaching an exhaustion point and about to revert downwards. Similarly, when the indicator generates a potential long entry signal (1) that aligns with the confluence condition, the background color is set to fuchsia. This color represents a bearish trend that is potentially reaching an exhaustion point and about to revert upwards. By employing background coloration, the indicator enables traders to quickly identify market conditions that may offer mean reversion opportunities with a directional bias.
The indicator further enhances visual clarity by incorporating bar coloring that aligns with the prevailing market conditions and signals. When the indicator generates a potential short entry signal (-1) that aligns with the confluence condition, the bar color is set to lime. This color signifies a bullish trend that is potentially reaching an exhaustion point, indicating a high probability of a downward reversion. Conversely, when the indicator generates a potential long entry signal (1) that aligns with the confluence condition, the bar color is set to fuchsia. This color represents a bearish trend that is potentially reaching an exhaustion point, indicating a high probability of an upward reversion. By using distinct bar colors, the indicator provides traders with a clear visual distinction between bullish and bearish trends, facilitating easier identification of mean reversion opportunities within the context of the broader trend.
While the "Adaptive Mean Reversion Indicator" offers a robust framework for identifying mean reversion opportunities, it's important to remember that no indicator is foolproof. Traders should exercise caution and employ risk management strategies. Additionally, it is recommended to use this indicator in conjunction with other technical analysis tools and fundamental factors to make well-informed trading decisions. Regular backtesting and refinement of the indicator's parameters are crucial to ensure its effectiveness in different market conditions.
Volume-Weighted RSI with Adaptive SmoothingThis indicator is designed to provide traders with insights into the relative strength of a security by incorporating volume-weighted elements, effectively combining the concepts of Relative Strength Index (RSI) and volume-weighted averages to generate meaningful trading signals.
The indicator calculates the traditional RSI, which measures the speed and change of price movements, as well as the volume-weighted RSI, which considers the influence of trading volume on price action. It then applies adaptive smoothing to the volume-weighted RSI, allowing for customization of the smoothing process. The resulting smoothed volume-weighted RSI is plotted alongside the original RSI, providing traders with a comprehensive view of the price strength dynamics.
The line coloration in this indicator is designed to provide visual cues about the relationship between the RSI and the volume-weighted RSI. When the RSI line is above or equal to the volume-weighted RSI line, it suggests a potentially bullish condition with positive market momentum. In such cases, the line is colored lime. Conversely, when the RSI line (fuchsia) is below the volume-weighted RSI line, it indicates a potentially bearish condition with negative market momentum. The line color is set to fuchsia. By observing the line color, traders can quickly assess the relative strength between the RSI and the volume-weighted RSI, aiding their decision-making process.
The bar color and background color further enhance the visual interpretation of the indicator. The bar color reflects the RSI's relationship with the volume-weighted RSI and the predefined thresholds. If the RSI line is above both the volume-weighted RSI line and the overbought threshold (70), the bar color is set to lime, indicating a potentially overbought condition. Conversely, if the RSI line is below both the volume-weighted RSI line and the oversold threshold (30), the bar color is set to fuchsia, suggesting a potentially oversold condition. When the RSI line is between these two thresholds, the bar color is set to yellow, indicating a neutral or intermediate state. The background color, displayed with a semi-transparent shade, provides additional context by reflecting the prevailing market conditions. It turns lime if the volume-weighted RSI is above the overbought threshold, fuchsia if below the oversold threshold, and yellow if it falls between these two thresholds. This coloration scheme aids traders in quickly assessing market conditions and potential trading opportunities.
Calculations:
-- RSI Calculation : The traditional RSI is calculated based on the price movements of the asset. The up and down movements are determined, and exponential moving averages are used to smooth the values. The RSI value ranges from 0 to 100, with levels above 70 indicating overbought conditions and levels below 30 indicating oversold conditions.
-- Volume-Weighted RSI Calculation : The volume-weighted RSI incorporates the trading volume of the asset into the calculations. The closing price is multiplied by the corresponding volume, and the average is taken over a specific length. The up and down movements are smoothed using exponential moving averages to generate the volume-weighted RSI value.
-- Adaptive Smoothing : The indicator offers an adaptive smoothing option, allowing traders to customize the smoothing process of the volume-weighted RSI. By adjusting the smoothing length, traders can fine-tune the responsiveness of the indicator to changes in market conditions. Smoothing helps reduce noise and enhances the clarity of the signals.
Interpretation:
The indicator provides two main components for interpretation:
-- RSI : The traditional RSI reflects the price momentum and potential overbought or oversold conditions. Traders can look for RSI values above 70 as potential overbought signals, suggesting a possible price reversal or correction. Conversely, RSI values below 30 indicate potential oversold signals, indicating a potential price rebound or rally.
-- Volume-Weighted RSI : The volume-weighted RSI incorporates trading volume, which provides insights into the strength of price movements. When the volume-weighted RSI is above the traditional RSI, it suggests that the buying pressure supported by higher volume is stronger, potentially indicating a more reliable trend. Conversely, when the volume-weighted RSI is below the traditional RSI, it suggests that the selling pressure supported by higher volume is stronger, potentially indicating a more significant price reversal.
Potential Strategies:
-- Overbought and Oversold Signals : Traders can utilize the RSI component of the indicator to identify overbought and oversold conditions. A potential strategy is to consider taking short positions when the RSI is above 70 and long positions when the RSI is below 30. These levels can act as dynamic support and resistance areas, indicating possible price reversals.
-- Confirmation with Volume : Traders can use the volume-weighted RSI as a confirmation tool to validate price movements. When the volume-weighted RSI is above the traditional RSI, it may provide additional confirmation for long positions, suggesting stronger buying pressure. Conversely, when the volume-weighted RSI is below the traditional RSI, it may provide confirmation for short positions, indicating stronger selling pressure.
-- Trend Reversal Strategy : Watch for the volume-weighted RSI to reach extreme levels above 70 (overbought) or below 30 (oversold). Look for a reversal signal where the RSI line (green or fuchsia) crosses below or above the volume-weighted RSI line. Enter a trade when the reversal signal occurs, and the RSI line changes color. Exit the trade when the RSI line crosses back in the opposite direction or reaches the opposite extreme level.
-- Divergence Strategy : Compare the direction of the RSI line (green or fuchsia) with the volume-weighted RSI line. A bullish divergence occurs when the RSI line makes higher lows while the volume-weighted RSI line makes lower lows. A bearish divergence occurs when the RSI line makes lower highs while the volume-weighted RSI line makes higher highs. Once a divergence is identified, wait for the RSI line to cross above or below the volume-weighted RSI line as confirmation of a potential trend reversal. Consider using additional indicators or price action analysis to time the entry more accurately. Use stop-loss orders and profit targets to manage risk and secure profits.
-- Trend Continuation Strategy : Assess the overall trend direction by observing the RSI line's position relative to the volume-weighted RSI line. When the RSI line consistently stays above the volume-weighted RSI line, it indicates a bullish trend, while the opposite suggests a bearish trend. Look for temporary pullbacks within the ongoing trend where the RSI line (green or fuchsia) touches or crosses the volume-weighted RSI line. Enter trades in the direction of the dominant trend when the RSI line crosses back in the trend direction. Exit the trade when the RSI line starts to deviate significantly from the volume-weighted RSI line or when the trend shows signs of weakening through other technical or fundamental factors.
Limitations:
-- False Signals : Like any indicator, the "Volume-Weighted RSI with Adaptive Smoothing" may produce false signals, especially during periods of low liquidity or choppy market conditions. Traders should exercise caution and consider using additional confirmation indicators or tools to validate the signals generated by this indicator.
-- Lagging Nature : The indicator relies on historical price data and volume to calculate the RSI and volume-weighted RSI. As a result, the signals provided may have a certain degree of lag compared to real-time price action. Traders should be aware of this inherent lag and consider combining the indicator with other timely indicators to enhance the accuracy of their trading decisions.
-- Parameter Sensitivity : The indicator's effectiveness can be influenced by the choice of parameters, such as the length of the RSI, smoothing length, and adaptive smoothing option. Different market conditions may require adjustments to these parameters to optimize performance. Traders are encouraged to conduct thorough testing and analysis to determine the most suitable parameter values for their specific trading strategies and preferences.
-- Market Conditions : The indicator's performance may vary depending on the prevailing market conditions. It is essential to understand that no indicator can guarantee accurate predictions or consistently profitable trades. Traders should consider the broader market context, fundamental factors, and other technical indicators to complement the insights provided by the "Volume-Weighted RSI with Adaptive Smoothing" indicator.
-- Subjectivity : Interpretation of the indicator's signals involves subjective judgment. Traders may have varying interpretations of overbought and oversold levels, as well as the significance of the volume-weighted RSI in relation to the traditional RSI. It is crucial to combine the indicator with personal analysis and trading experience to make informed trading decisions.
Remember, no single indicator can provide foolproof trading signals. The "Volume-Weighted RSI with Adaptive Smoothing" indicator serves as a valuable tool for analyzing price strength and volume dynamics. It can assist traders in identifying potential entry and exit points, validating trends, and managing risk. However, it should be used as part of a comprehensive trading strategy that considers multiple factors and indicators to increase the likelihood of successful trades.

Non Adaptive Moving Average - Quan DaoThis Non-Adaptive Moving Average (NAMA) is my origin work. It came from the issues that I always face when using existing famous MA like EMA or RMA:
- What length should I choose for the MA for this security?
- Is there a length that works for multiple timeframes?
- Is there a length that works for multiple securities in multiple markets?
Choosing the right length for an MA is a tedious and boring work and is very subjective. One day in early 2023, I decided to create a new MA that will not be dependant a lot (non-adaptive) on the length of it, to make my life a little bit easier. The idea came from the formula of EMA and RMA:
ma = alpha * src + (1 - alpha) * ma
in which,
alpha = 1 / length for RMA
alpha = 2 / (length + 1) for EMA
I decided to use a constant alpha for the formula, which happened to be: 1.618 / 100 (i.e., golden ratio / 100)
This NAMA is using the length in the start only, after running for a while the MA value will be the same for every value of its length, which resolves good my 3 questions above.
The application of this NAMA is wide, I think.
- It can be used like a normal MA but you don't have to choose its length anymore.
- It can be used like EMA in DEMA, TEMA (I called it DNAMA, TNAMA)
- It can be used in calculating some famous indicators (RSI, TR, ...) so that these indicators will not be dependant on the length as well
In this example script, I included an EMA (in blue color) as well so that you can see how the EMA changes and NAMA stays the same when changing the value of its Length.

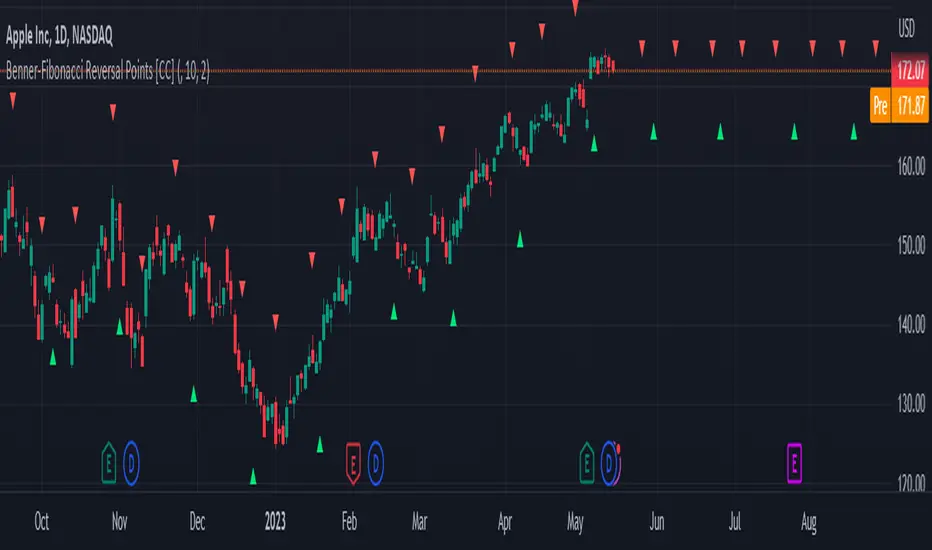
Benner-Fibonacci Reversal Points [CC]This is an original script based on a very old idea called the Benner Theory from the Civil War times. Benner discovered a pattern in pig iron prices (no clue what those are), and this turned out to be a parallel idea to indicators based on Fibonacci numbers. Because a year is 365 days (nearly 377, which is a Fibonacci number), made up of 52 weeks (nearly 55, which is another Fibonacci number), or 12 months (nearly 13, which is another Fibonacci number), Benner theorized that he could find both past and future turning points in the market by using a pattern he found. He discovered that peaks in prices seemed to follow a pattern of 8-9-10, meaning that after a recent peak, it would be 8 bars until the next peak, 9 bars until after that peak for the next, and 10 bars until the following peak. For past peaks, he would just need to reverse this pattern, and so the previous peak would be 10 bars before the most current peak, 9 bars before that peak, and 8 bars before the previous one, and these patterns seemed to repeat. For troughs, he found a pattern of 16,18,20 which follows the same logic, and this idea also seemed to work on long-term peaks and troughs as well.
This is my version of the Benner theory and the major difference between my version and his is that he would manually select a year or date and either work backwards or forwards from that point. I chose to go with an adaptive version that will automatically detect those points and plot those past and future points. I have included several options such as allowing the algorithm to be calculated in reverse which seems to work well for Crypto for some reason. I also have both short and long term options to only show one or both if you choose and of course the option to enable repainting or leave it disabled.
Big thanks to @HeWhoMustNotBeNamed and @RicardoSantos for helping me fix some bugs in my code and for @kerpiciwuasile for suggesting this idea in the first place.
Endpointed SSA of Price [Loxx]The Endpointed SSA of Price: A Comprehensive Tool for Market Analysis and Decision-Making
The financial markets present sophisticated challenges for traders and investors as they navigate the complexities of market behavior. To effectively interpret and capitalize on these complexities, it is crucial to employ powerful analytical tools that can reveal hidden patterns and trends. One such tool is the Endpointed SSA of Price, which combines the strengths of Caterpillar Singular Spectrum Analysis, a sophisticated time series decomposition method, with insights from the fields of economics, artificial intelligence, and machine learning.
The Endpointed SSA of Price has its roots in the interdisciplinary fusion of mathematical techniques, economic understanding, and advancements in artificial intelligence. This unique combination allows for a versatile and reliable tool that can aid traders and investors in making informed decisions based on comprehensive market analysis.
The Endpointed SSA of Price is not only valuable for experienced traders but also serves as a useful resource for those new to the financial markets. By providing a deeper understanding of market forces, this innovative indicator equips users with the knowledge and confidence to better assess risks and opportunities in their financial pursuits.
█ Exploring Caterpillar SSA: Applications in AI, Machine Learning, and Finance
Caterpillar SSA (Singular Spectrum Analysis) is a non-parametric method for time series analysis and signal processing. It is based on a combination of principles from classical time series analysis, multivariate statistics, and the theory of random processes. The method was initially developed in the early 1990s by a group of Russian mathematicians, including Golyandina, Nekrutkin, and Zhigljavsky.
Background Information:
SSA is an advanced technique for decomposing time series data into a sum of interpretable components, such as trend, seasonality, and noise. This decomposition allows for a better understanding of the underlying structure of the data and facilitates forecasting, smoothing, and anomaly detection. Caterpillar SSA is a particular implementation of SSA that has proven to be computationally efficient and effective for handling large datasets.
Uses in AI and Machine Learning:
In recent years, Caterpillar SSA has found applications in various fields of artificial intelligence (AI) and machine learning. Some of these applications include:
1. Feature extraction: Caterpillar SSA can be used to extract meaningful features from time series data, which can then serve as inputs for machine learning models. These features can help improve the performance of various models, such as regression, classification, and clustering algorithms.
2. Dimensionality reduction: Caterpillar SSA can be employed as a dimensionality reduction technique, similar to Principal Component Analysis (PCA). It helps identify the most significant components of a high-dimensional dataset, reducing the computational complexity and mitigating the "curse of dimensionality" in machine learning tasks.
3. Anomaly detection: The decomposition of a time series into interpretable components through Caterpillar SSA can help in identifying unusual patterns or outliers in the data. Machine learning models trained on these decomposed components can detect anomalies more effectively, as the noise component is separated from the signal.
4. Forecasting: Caterpillar SSA has been used in combination with machine learning techniques, such as neural networks, to improve forecasting accuracy. By decomposing a time series into its underlying components, machine learning models can better capture the trends and seasonality in the data, resulting in more accurate predictions.
Application in Financial Markets and Economics:
Caterpillar SSA has been employed in various domains within financial markets and economics. Some notable applications include:
1. Stock price analysis: Caterpillar SSA can be used to analyze and forecast stock prices by decomposing them into trend, seasonal, and noise components. This decomposition can help traders and investors better understand market dynamics, detect potential turning points, and make more informed decisions.
2. Economic indicators: Caterpillar SSA has been used to analyze and forecast economic indicators, such as GDP, inflation, and unemployment rates. By decomposing these time series, researchers can better understand the underlying factors driving economic fluctuations and develop more accurate forecasting models.
3. Portfolio optimization: By applying Caterpillar SSA to financial time series data, portfolio managers can better understand the relationships between different assets and make more informed decisions regarding asset allocation and risk management.
Application in the Indicator:
In the given indicator, Caterpillar SSA is applied to a financial time series (price data) to smooth the series and detect significant trends or turning points. The method is used to decompose the price data into a set number of components, which are then combined to generate a smoothed signal. This signal can help traders and investors identify potential entry and exit points for their trades.
The indicator applies the Caterpillar SSA method by first constructing the trajectory matrix using the price data, then computing the singular value decomposition (SVD) of the matrix, and finally reconstructing the time series using a selected number of components. The reconstructed series serves as a smoothed version of the original price data, highlighting significant trends and turning points. The indicator can be customized by adjusting the lag, number of computations, and number of components used in the reconstruction process. By fine-tuning these parameters, traders and investors can optimize the indicator to better match their specific trading style and risk tolerance.
Caterpillar SSA is versatile and can be applied to various types of financial instruments, such as stocks, bonds, commodities, and currencies. It can also be combined with other technical analysis tools or indicators to create a comprehensive trading system. For example, a trader might use Caterpillar SSA to identify the primary trend in a market and then employ additional indicators, such as moving averages or RSI, to confirm the trend and generate trading signals.
In summary, Caterpillar SSA is a powerful time series analysis technique that has found applications in AI and machine learning, as well as financial markets and economics. By decomposing a time series into interpretable components, Caterpillar SSA enables better understanding of the underlying structure of the data, facilitating forecasting, smoothing, and anomaly detection. In the context of financial trading, the technique is used to analyze price data, detect significant trends or turning points, and inform trading decisions.
█ Input Parameters
This indicator takes several inputs that affect its signal output. These inputs can be classified into three categories: Basic Settings, UI Options, and Computation Parameters.
Source: This input represents the source of price data, which is typically the closing price of an asset. The user can select other price data, such as opening price, high price, or low price. The selected price data is then utilized in the Caterpillar SSA calculation process.
Lag: The lag input determines the window size used for the time series decomposition. A higher lag value implies that the SSA algorithm will consider a longer range of historical data when extracting the underlying trend and components. This parameter is crucial, as it directly impacts the resulting smoothed series and the quality of extracted components.
Number of Computations: This input, denoted as 'ncomp,' specifies the number of eigencomponents to be considered in the reconstruction of the time series. A smaller value results in a smoother output signal, while a higher value retains more details in the series, potentially capturing short-term fluctuations.
SSA Period Normalization: This input is used to normalize the SSA period, which adjusts the significance of each eigencomponent to the overall signal. It helps in making the algorithm adaptive to different timeframes and market conditions.
Number of Bars: This input specifies the number of bars to be processed by the algorithm. It controls the range of data used for calculations and directly affects the computation time and the output signal.
Number of Bars to Render: This input sets the number of bars to be plotted on the chart. A higher value slows down the computation but provides a more comprehensive view of the indicator's performance over a longer period. This value controls how far back the indicator is rendered.
Color bars: This boolean input determines whether the bars should be colored according to the signal's direction. If set to true, the bars are colored using the defined colors, which visually indicate the trend direction.
Show signals: This boolean input controls the display of buy and sell signals on the chart. If set to true, the indicator plots shapes (triangles) to represent long and short trade signals.
Static Computation Parameters:
The indicator also includes several internal parameters that affect the Caterpillar SSA algorithm, such as Maxncomp, MaxLag, and MaxArrayLength. These parameters set the maximum allowed values for the number of computations, the lag, and the array length, ensuring that the calculations remain within reasonable limits and do not consume excessive computational resources.
█ A Note on Endpionted, Non-repainting Indicators
An endpointed indicator is one that does not recalculate or repaint its past values based on new incoming data. In other words, the indicator's previous signals remain the same even as new price data is added. This is an important feature because it ensures that the signals generated by the indicator are reliable and accurate, even after the fact.
When an indicator is non-repainting or endpointed, it means that the trader can have confidence in the signals being generated, knowing that they will not change as new data comes in. This allows traders to make informed decisions based on historical signals, without the fear of the signals being invalidated in the future.
In the case of the Endpointed SSA of Price, this non-repainting property is particularly valuable because it allows traders to identify trend changes and reversals with a high degree of accuracy, which can be used to inform trading decisions. This can be especially important in volatile markets where quick decisions need to be made.
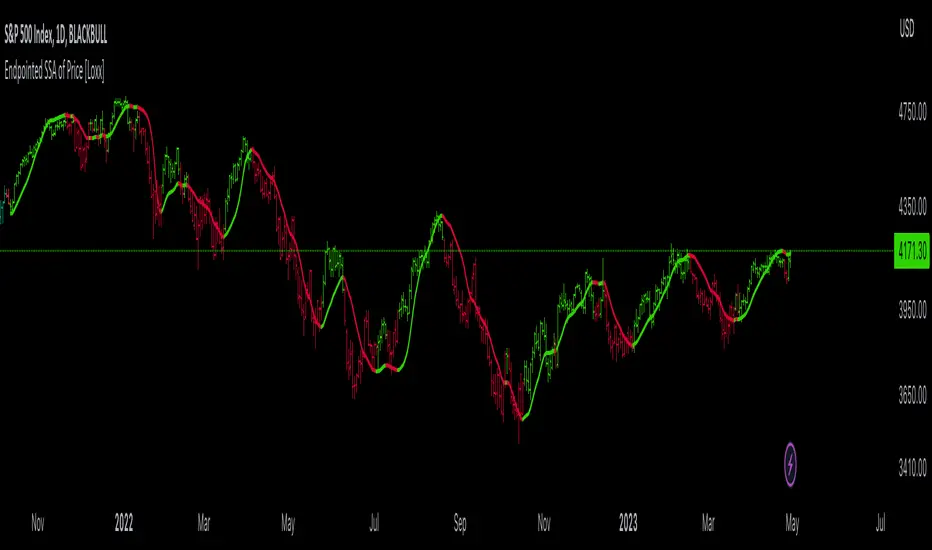
Adaptive Price Channel StrategyThis strategy is an adaptive price channel strategy based on the Average True Range (ATR) indicator and the Average Directional Index (ADX). It aims to identify sideways markets and trends in the price movements and make trades accordingly.
The strategy uses a length parameter for the ATR and ADX indicators, which determines the length of the calculation for these indicators. The strategy also uses an ATR multiplier, which is multiplied by the ATR to determine the upper and lower bounds of the price channel.
The first step of the strategy is to calculate the highest high (HH) and lowest low (LL) over the specified length. The ATR is also calculated over the same length. Then the strategy calculates the positive directional indicator (+DI) and negative directional indicator (-DI) based on the up and down moves in the price, and uses these to calculate the ADX.
If the ADX is less than 25, the market is considered to be in a sideways phase. In this case, if the price closes above the upper bound of the price channel (HH - ATR multiplier * ATR), the strategy enters a long position, and if the price closes below the lower bound of the price channel (LL + ATR multiplier * ATR), the strategy enters a short position.
If the ADX is greater than or equal to 25 and the +DI is greater than the -DI, the market is considered to be in a bullish phase. In this case, if the price closes above the upper bound of the price channel, the strategy enters a long position. If the ADX is greater than or equal to 25 and the +DI is less than the -DI, the market is considered to be in a bearish phase. In this case, if the price closes below the lower bound of the price channel, the strategy enters a short position.
The strategy exits a position after a certain number of bars have passed since the entry, as specified by the exit_length input.
In summary, this strategy attempts to trade in accordance with the prevailing market conditions by identifying sideways markets and trends and making trades based on price movements within a dynamically-adjusted price channel.
This strategy takes a read on the market and either takes a channel strategy or trades volatility based on current trend. Works well on 2, 3 ,4, 12 hour for BTC. It’s my first attempt and creating a strategy. I am very interested in constructive criticism. I will look into better risk management, maybe a trailing stop loss. Other suggestions welcome. This is my first attempt at a strategy.
Here are the settings I used.
Inputs
Length 20
Exit 10
ATR 3.2
Dates I picked when I got into Crypto
Properties
Capital 1000
Order size 2 Contracts
Pyramiding 1
Commission .05

STD-Filtered Jurik Volty Adaptive TEMA [Loxx]The STD-Filtered Jurik Volty Adaptive TEMA is an advanced moving average overlay indicator that incorporates adaptive period inputs from Jurik Volty into a Triple Exponential Moving Average (TEMA). The resulting value is further refined using a standard deviation filter to minimize noise. This adaptation aims to develop a faster TEMA that leads the standard, non-adaptive TEMA. However, during periods of low volatility, the output may be noisy, so a standard deviation filter is employed to decrease choppiness, yielding a highly responsive TEMA without the noise typically caused by low market volatility.
█ What is Jurik Volty?
Jurik Volty calculates the price volatility and relative price volatility factor.
The Jurik smoothing includes 3 stages:
1st stage - Preliminary smoothing by adaptive EMA
2nd stage - One more preliminary smoothing by Kalman filter
3rd stage - Final smoothing by unique Jurik adaptive filter
Here's a breakdown of the code:
1. volty(float src, int len) => defines a function called volty that takes two arguments: src, which represents the source price data (like close price), and len, which represents the length or period for calculating the indicator.
2. int avgLen = 65 sets the length for the Simple Moving Average (SMA) to 65.
3. Various variables are initialized like volty, voltya, bsmax, bsmin, and vsum.
4. len1 is calculated as math.max(math.log(math.sqrt(0.5 * (len-1))) / math.log(2.0) + 2.0, 0); this expression involves some mathematical transformations based on the len input. The purpose is to create a dynamic factor that will be used later in the calculations.
5. pow1 is calculated as math.max(len1 - 2.0, 0.5); this variable is another dynamic factor used in further calculations.
6. del1 and del2 represent the differences between the current src value and the previous values of bsmax and bsmin, respectively.
7. volty is assigned a value based on a conditional expression, which checks whether the absolute value of del1 is greater than the absolute value of del2. This step is essential for determining the direction and magnitude of the price change.
8. vsum is updated based on the previous value and the difference between the current and previous volty values.
9. The Simple Moving Average (SMA) of vsum is calculated with the length avgLen and assigned to avg.
10. Variables dVolty, pow2, len2, and Kv are calculated using various mathematical transformations based on previously calculated variables. These variables are used to adjust the Jurik Volty indicator based on the observed volatility.
11. The bsmax and bsmin variables are updated based on the calculated Kv value and the direction of the price change.
12. inally, the temp variable is calculated as the ratio of avolty to vsum. This value represents the Jurik Volty indicator's output and can be used to analyze the market trends and potential reversals.
Jurik Volty can be used to identify periods of high or low volatility and to spot potential trade setups based on price behavior near the volatility bands.
█ What is the Triple Exponential Moving Average?
The Triple Exponential Moving Average (TEMA) is a technical indicator used by traders and investors to identify trends and price reversals in financial markets. It is a more advanced and responsive version of the Exponential Moving Average (EMA). TEMA was developed by Patrick Mulloy and introduced in the January 1994 issue of Technical Analysis of Stocks & Commodities magazine. The aim of TEMA is to minimize the lag associated with single and double exponential moving averages while also filtering out market noise, thus providing a smoother, more accurate representation of the market trend.
To understand TEMA, let's first briefly review the EMA.
Exponential Moving Average (EMA):
EMA is a weighted moving average that gives more importance to recent price data. The formula for EMA is:
EMA_t = (Price_t * α) + (EMA_(t-1) * (1 - α))
Where:
EMA_t: EMA at time t
Price_t: Price at time t
α: Smoothing factor (α = 2 / (N + 1))
N: Length of the moving average period
EMA_(t-1): EMA at time t-1
Triple Exponential Moving Average (TEMA):
Triple Exponential Moving Average (TEMA):
TEMA combines three exponential moving averages to provide a more accurate and responsive trend indicator. The formula for TEMA is:
TEMA = 3 * EMA_1 - 3 * EMA_2 + EMA_3
Where:
EMA_1: The first EMA of the price data
EMA_2: The EMA of EMA_1
EMA_3: The EMA of EMA_2
Here are the steps to calculate TEMA:
1. Choose the length of the moving average period (N).
2. Calculate the smoothing factor α (α = 2 / (N + 1)).
3. Calculate the first EMA (EMA_1) using the price data and the smoothing factor α.
4. Calculate the second EMA (EMA_2) using the values of EMA_1 and the same smoothing factor α.
5. Calculate the third EMA (EMA_3) using the values of EMA_2 and the same smoothing factor α.
5. Finally, compute the TEMA using the formula: TEMA = 3 * EMA_1 - 3 * EMA_2 + EMA_3
The Triple Exponential Moving Average, with its combination of three EMAs, helps to reduce the lag and filter out market noise more effectively than a single or double EMA. It is particularly useful for short-term traders who require a responsive indicator to capture rapid price changes. Keep in mind, however, that TEMA is still a lagging indicator, and as with any technical analysis tool, it should be used in conjunction with other indicators and analysis methods to make well-informed trading decisions.
Extras
Signals
Alerts
Bar coloring
Loxx's Expanded Source Types (see below):
Adaptive Candlestick Pattern Recognition System█ INTRODUCTION
Nearly three years in the making, intermittently worked on in the few spare hours of weekends and time off, this is a passion project I undertook to flesh out my skills as a computer programmer. This script currently recognizes 85 different candlestick patterns ranging from one to five candles in length. It also performs statistical analysis on those patterns to determine prior performance and changes the coloration of those patterns based on that performance. In searching TradingView's script library for scripts similar to this one, I had found a handful. However, when I reviewed the ones which were open source, I did not see many that truly captured the power of PineScrypt or leveraged the way it works to create efficient and reliable code; one of the main driving factors for releasing this 5,000+ line behemoth open sourced.
Please take the time to review this description and source code to utilize this script to its fullest potential.
█ CONCEPTS
This script covers the following topics: Candlestick Theory, Trend Direction, Higher Timeframes, Price Analysis, Statistic Analysis, and Code Design.
Candlestick Theory - This script focuses solely on the concept of Candlestick Theory: arrangements of candlesticks may form certain patterns that can potentially influence the future price action of assets which experience those patterns. A full list of patterns (grouped by pattern length) will be in its own section of this description. This script contains two modes of operation for identifying candlestick patterns, 'CLASSIC' and 'BREAKOUT'.
CLASSIC: In this mode, candlestick patterns will be identified whenever they appear. The user has a wide variety of inputs to manipulate that can change how certain patterns are identified and even enable alerts to notify themselves when these patterns appear. Each pattern selected to appear will have their Profit or Loss (P/L) calculated starting from the first candle open succeeding the pattern to a candle close specified some number of candles ahead. These P/L calculations are then collected for each pattern, and split among partitions of prior price action of the asset the script is currently applied to (more on that in Higher Timeframes ).
BREAKOUT: In this mode, P/L calculations are held off until a breakout direction has been confirmed. The user may specify the number of candles ahead of a pattern's appearance (from one to five) that a pattern has to confirm a breakout in either an upward or downward direction. A breakout is constituted when there is a candle following the appearance of the pattern that closes above/at the highest high of the pattern, or below/at its lowest low. Only then will percent return calculations be performed for the pattern that's been identified, and these percent returns are broken up not only by the partition they had appeared in but also by the breakout direction itself. Patterns which do not breakout in either direction will be ignored, along with having their labels deleted.
In both of these modes, patterns may be overridden. Overrides occur when a smaller pattern has been detected and ends up becoming one (or more) of the candles of a larger pattern. A key example of this would be the Bearish Engulfing and the Three Outside Down patterns. A Three Outside Down necessitates a Bearish Engulfing as the first two candles in it, while the third candle closes lower. When a pattern is overridden, the return for that pattern will no longer be tracked. Overrides will not occur if the tail end of a larger pattern occurs at the beginning of a smaller pattern (Ex: a Bullish Engulfing occurs on the third candle of a Three Outside Down and the candle immediately following that pattern, the Three Outside Down pattern will not be overridden).
Important Functionality Note: These patterns are only searched for at the most recently closed candle, not on the currently closing candle, which creates an offset of one for this script's execution. (SEE LIMITATIONS)
Trend Direction - Many of the patterns require a trend direction prior to their appearance. Noting TradingView's own publication of candlestick patterns, I utilize a similar method for determining trend direction. Moving Averages are used to determine which trend is currently taking place for candlestick patterns to be sought out. The user has access to two Moving Averages which they may individually modify the following for each: Moving Average type (list of 9), their length, width, source values, and all variables associated with two special Moving Averages (Least Squares and Arnaud Legoux).
There are 3 settings for these Moving Averages, the first two switch between the two Moving Averages, and the third uses both. When using individual Moving Averages, the user may select a 'price point' to compare against the Moving Average (default is close). This price point is compared to the Moving Average at the candles prior to the appearance of candle patterns. Meaning: The close compared to the Moving Average two candles behind determines the trend direction used for Candlestick Analysis of one candle patterns; three candles behind for two candle patterns and so on. If the selected price point is above the Moving Average, then the current trend is an 'uptrend', 'downtrend' otherwise.
The third setting using both Moving Averages will compare the lengths of each, and trend direction is determined by the shorter Moving Average compared to the longer one. If the shorter Moving Average is above the longer, then the current trend is an 'uptrend', 'downtrend' otherwise. If the lengths of the Moving Averages are the same, or both Moving Averages are Symmetrical, then MA1 will be used by default. (SEE LIMITATIONS)
Higher Timeframes - This script employs the use of Higher Timeframes with a few request.security calls. The purpose of these calls is strictly for the partitioning of an asset's chart, splitting the returns of patterns into three separate groups. The four inputs in control of this partitioning split the chart based on: A given resolution to grab values from, the length of time in that resolution, and 'Upper' and 'Lower Limits' which split the trading range provided by that length of time in that resolution that forms three separate groups. The default values for these four inputs will partition the current chart by the yearly high-low range where: the 'Upper' partition is the top 20% of that trading range, the 'Middle' partition is 80% to 33% of the trading range, and the 'Lower' partition covers the trading range within 33% of the yearly low.
Patterns which are identified by this script will have their returns grouped together based on which partition they had appeared in. For example, a Bullish Engulfing which occurs within a third of the yearly low will have its return placed separately from a Bullish Engulfing that occurred within 20% of the yearly high. The idea is that certain patterns may perform better or worse depending on when they had occurred during an asset's trading range.
Price Analysis - Price Analysis is a major part of this script's functionality as it can fundamentally change how patterns are shown to the user. The settings related to Price Analysis include setting the number of candles ahead of a pattern's appearance to determine the return of that pattern. In 'BREAKOUT' mode, an additional setting allows the user to specify where the P/L calculation will begin for a pattern that had appeared and confirmed. (SEE LIMITATIONS)
The calculation for percent returns of patterns is illustrated with the following pseudo-code (CLASSIC mode, this is a simplified version of the actual code):
type patternObj
int ID
int partition
type returnsArray
float returns
// No pattern found = na returned
patternObj TEST_VAL = f_FindPattern()
priorTestVal = TEST_VAL
if not na( priorTestVal )
pnlMatrixRow = priorTestVal.ID
pnlMatrixCol = priorTestVal.partition
matrixReturn = matrix.get(PERCENT_RETURNS, pnlMatrixRow, pnlMatrixCol)
percentReturn = ( (close - open ) / open ) * 100%
array.push(matrixReturn.returns, percentReturn)
Statistic Analysis - This script uses Pine's built-in array functions to conduct the Statistic Analysis for patterns. When a pattern is found and its P/L calculation is complete, its return is added to a 'Return Array' User-Defined-Type that contains numerous fields which retain information on a pattern's prior performance. The actual UDT is as follows:
type returnArray
float returns = na
int size = 0
float avg = 0
float median = 0
float stdDev = 0
int polarities = na
All values within this UDT will be updated when a return is added to it (some based on user input). The array.avg , array.median and array.stdev will be ran and saved into their respective fields after a return is placed in the 'returns' array. The 'polarities' integer array is what will be changed based on user input. The user specifies two different percentages that declare 'Positive' and 'Negative' returns for patterns. When a pattern returns above, below, or in between these two values, different indices of this array will be incremented to reflect the kind of return that pattern had just experienced.
These values (plus the full name, partition the pattern occurred in, and a 95% confidence interval of expected returns) will be displayed to the user on the tooltip of the labels that identify patterns. Simply scroll over the pattern label to view each of these values.
Code Design - Overall this script is as much of an art piece as it is functional. Its design features numerous depictions of ASCII Art that illustrate what is being attempted by the functions that identify patterns, and an incalculable amount of time was spent rewriting portions of code to improve its efficiency. Admittedly, this final version is nearly 1,000 lines shorter than a previous version (one which took nearly 30 seconds after compilation to run, and didn't do nearly half of what this version does). The use of UDTs, especially the 'patternObj' one crafted and redesigned from the Hikkake Hunter 2.0 I published last month, played a significant role in making this script run efficiently. There is a slight rigidity in some of this code mainly around pattern IDs which are responsible for displaying the abbreviation for patterns (as well as the full names under the tooltips, and the matrix row position for holding returns), as each is hard-coded to correspond to that pattern.
However, one thing I would like to mention is the extensive use of global variables for pattern detection. Many scripts I had looked over for ideas on how to identify candlestick patterns had the same idea; break the pattern into a set of logical 'true/false' statements derived from historically referencing candle OHLC values. Some scripts which identified upwards of 20 to 30 patterns would reference Pine's built-in OHLC values for each pattern individually, potentially requesting information from TradingView's servers numerous times that could easily be saved into a variable for re-use and only requested once per candle (what this script does).
█ FEATURES
This script features a massive amount of switches, options, floating point values, detection settings, and methods for identifying/tailoring pattern appearances. All modifiable inputs for patterns are grouped together based on the number of candles they contain. Other inputs (like those for statistics settings and coloration) are grouped separately and presented in a way I believe makes the most sense.
Not mentioned above is the coloration settings. One of the aims of this script was to make patterns visually signify their behavior to the user when they are identified. Each pattern has its own collection of returns which are analyzed and compared to the inputs of the user. The user may choose the colors for bullish, neutral, and bearish patterns. They may also choose the minimum number of patterns needed to occur before assigning a color to that pattern based on its behavior; a color for patterns that have not met this minimum number of occurrences yet, and a color for patterns that are still processing in BREAKOUT mode.
There are also an additional three settings which alter the color scheme for patterns: Statistic Point-of-Reference, Adaptive coloring, and Hard Limiting. The Statistic Point-of-Reference decides which value (average or median) will be compared against the 'Negative' and 'Positive Return Tolerance'(s) to guide the coloration of the patterns (or for Adaptive Coloring, the generation of a color gradient).
Adaptive Coloring will have this script produce a gradient that patterns will be colored along. The more bullish or bearish a pattern is, the further along the gradient those patterns will be colored starting from the 'Neutral' color (hard lined at the value of 0%: values above this will be colored bullish, bearish otherwise). When Adaptive Coloring is enabled, this script will request the highest and lowest values (these being the Statistic Point-of-Reference) from the matrix containing all returns and rewrite global variables tied to the negative and positive return tolerances. This means that all patterns identified will be compared with each other to determine bullish/bearishness in Adaptive Coloring.
Hard Limiting will prevent these global variables from being rewritten, so patterns whose Statistic Point-of-Reference exceed the return tolerances will be fully colored the bullish or bearish colors instead of a generated gradient color. (SEE LIMITATIONS)
Apart from the Candle Detection Modes (CLASSIC and BREAKOUT), there's an additional two inputs which modify how this script behaves grouped under a "MASTER DETECTION SETTINGS" tab. These two "Pattern Detection Settings" are 'SWITCHBOARD' and 'TARGET MODE'.
SWITCHBOARD: Every single pattern has a switch that is associated with its detection. When a switch is enabled, the code which searches for that pattern will be run. With the Pattern Detection Setting set to this, all patterns that have their switches enabled will be sought out and shown.
TARGET MODE: There is an additional setting which operates on top of 'SWITCHBOARD' that singles out an individual pattern the user specifies through a drop down list. The names of every pattern recognized by this script will be present along with an identifier that shows the number of candles in that pattern (Ex: " (# candles)"). All patterns enabled in the switchboard will still have their returns measured, but only the pattern selected from the "Target Pattern" list will be shown. (SEE LIMITATIONS)
The vast majority of other features are held in the one, two, and three candle pattern sections.
For one-candle patterns, there are:
3 — Settings related to defining 'Tall' candles:
The number of candles to sample for previous candle-size averages.
The type of comparison done for 'Tall' Candles: Settings are 'RANGE' and 'BODY'.
The 'Tolerance' for tall candles, specifying what percent of the 'average' size candles must exceed to be considered 'Tall'.
When 'Tall Candle Setting' is set to RANGE, the high-low ranges are what the current candle range will be compared against to determine if a candle is 'Tall'. Otherwise the candle bodies (absolute value of the close - open) will be compared instead. (SEE LIMITATIONS)
Hammer Tolerance - How large a 'discarded wick' may be before it disqualifies a candle from being a 'Hammer'.
Discarded wicks are compared to the size of the Hammer's candle body and are dependent upon the body's center position. Hammer bodies closer to the high of the candle will have the upper wick used as its 'discarded wick', otherwise the lower wick is used.
9 — Doji Settings, some pulled from an old Doji Hunter I made a while back:
Doji Tolerance - How large the body of a candle may be compared to the range to be considered a 'Doji'.
Ignore N/S Dojis - Turns off Trend Direction for non-special Dojis.
GS/DF Doji Settings - 2 Inputs that enable and specify how large wicks that typically disqualify Dojis from being 'Gravestone' or 'Dragonfly' Dojis may be.
4 Settings related to 'Long Wick Doji' candles detailed below.
A Tolerance for 'Rickshaw Man' Dojis specifying how close the center of the body must be to the range to be valid.
The 4 settings the user may modify for 'Long Legged' Dojis are: A Sample Base for determining the previous average of wicks, a Sample Length specifying how far back to look for these averages, a Behavior Setting to define how 'Long Legged' Dojis are recognized, and a tolerance to specify how large in comparison to the prior wicks a Doji's wicks must be to be considered 'Long Legged'.
The 'Sample Base' list has two settings:
RANGE: The wicks of prior candles are compared to their candle ranges and the 'wick averages' will be what the average percent of ranges were in the sample.
WICKS: The size of the wicks themselves are averaged and returned for comparing against the current wicks of a Doji.
The 'Behavior' list has three settings:
ONE: Only one wick length needs to exceed the average by the tolerance for a Doji to be considered 'Long Legged'.
BOTH: Both wick lengths need to exceed the average of the tolerance of their respective wicks (upper wicks are compared to upper wicks, lower wicks compared to lower) to be considered 'Long Legged'.
AVG: Both wicks and the averages of the previous wicks are added together, divided by two, and compared. If the 'average' of the current wicks exceeds this combined average of prior wicks by the tolerance, then this would constitute a valid 'Long Legged' Doji. (For Dojis in general - SEE LIMITATIONS)
The final input is one related to candle patterns which require a Marubozu candle in them. The two settings for this input are 'INCLUSIVE' and 'EXCLUSIVE'. If INCLUSIVE is selected, any opening/closing variant of Marubozu candles will be allowed in the patterns that require them.
For two-candle patterns, there are:
2 — Settings which define 'Engulfing' parameters:
Engulfing Setting - Two options, RANGE or BODY which sets up how one candle may 'engulf' the previous.
Inclusive Engulfing - Boolean which enables if 'engulfing' candles can be equal to the values needed to 'engulf' the prior candle.
For the 'Engulfing Setting':
RANGE: If the second candle's high-low range completely covers the high-low range of the prior candle, this is recognized as 'engulfing'.
BODY: If the second candle's open-close completely covers the open-close of the previous candle, this is recognized as 'engulfing'. (SEE LIMITATIONS)
4 — Booleans specifying different settings for a few patterns:
One which allows for 'opens within body' patterns to let the second candle's open/close values match the prior candles' open/close.
One which forces 'Kicking' patterns to have a gap if the Marubozu setting is set to 'INCLUSIVE'.
And Two which dictate if the individual candles in 'Stomach' patterns need to be 'Tall'.
8 — Floating point values which affect 11 different patterns:
One which determines the distance the close of the first candle in a 'Hammer Inverted' pattern must be to the low to be considered valid.
One which affects how close the opens/closes need to be for all 'Lines' patterns (Bull/Bear Meeting/Separating Lines).
One that allows some leeway with the 'Matching Low' pattern (gives a small range the second candle close may be within instead of needing to match the previous close).
Three tolerances for On Neck/In Neck patterns (2 and 1 respectively).
A tolerance for the Thrusting pattern which give a range the close the second candle may be between the midpoint and close of the first to be considered 'valid'.
A tolerance for the two Tweezers patterns that specifies how close the highs and lows of the patterns need to be to each other to be 'valid'.
The first On Neck tolerance specifies how large the lower wick of the first candle may be (as a % of that candle's range) before the pattern is invalidated. The second tolerance specifies how far up the lower wick to the close the second candle's close may be for this pattern. The third tolerance for the In Neck pattern determines how far into the body of the first candle the second may close to be 'valid'.
For the remaining patterns (3, 4, and 5 candles), there are:
3 — Settings for the Deliberation pattern:
A boolean which forces the open of the third candle to gap above the close of the second.
A tolerance which changes the proximity of the third candle's open to the second candle's close in this pattern.
A tolerance that sets the maximum size the third candle may be compared to the average of the first two candles.
One boolean value for the Two Crows patterns (standard and Upside Gapping) that forces the first two candles in the patterns to completely gap if disabled (candle 1's close < candle 2's low).
10 — Floating point values for the remaining patterns:
One tolerance for defining how much the size of each candle in the Identical Black Crows pattern may deviate from the average of themselves to be considered valid.
One tolerance for setting how close the opens/closes of certain three candle patterns may be to each other's opens/closes.*
Three floating point values that affect the Three Stars in the South pattern.
One tolerance for the Side-by-Side patterns - looks at the second and third candle closes.
One tolerance for the Stick Sandwich pattern - looks at the first and third candle closes.
A floating value that sizes the Concealing Baby Swallow pattern's 3rd candle wick.
Two values for the Ladder Bottom pattern which define a range that the third candle's wick size may be.
* This affects the Three Black Crows (non-identical) and Three White Soldiers patterns, each require the opens and closes of every candle to be near each other.
The first tolerance of the Three Stars in the South pattern affects the first candle body's center position, and defines where it must be above to be considered valid. The second tolerance specifies how close the second candle must be to this same position, as well as the deviation the ratio the candle body to its range may be in comparison to the first candle. The third restricts how large the second candle range may be in comparison to the first (prevents this pattern from being recognized if the second candle is similar to the first but larger).
The last two floating point values define upper and lower limits to the wick size of a Ladder Bottom's fourth candle to be considered valid.
█ HOW TO USE
While there are many moving parts to this script, I attempted to set the default values with what I believed may help identify the most patterns within reasonable definitions. When this script is applied to a chart, the Candle Detection Mode (along with the BREAKOUT settings) and all candle switches must be confirmed before patterns are displayed. All switches are on by default, so this gives the user an opportunity to pick which patterns to identify first before playing around in the settings.
All of the settings/inputs described above are meant for experimentation. I encourage the user to tweak these values at will to find which set ups work best for whichever charts they decide to apply these patterns to.
Refer to the patterns themselves during experimentation. The statistic information provided on the tooltips of the patterns are meant to help guide input decisions. The breadth of candlestick theory is deep, and this was an attempt at capturing what I could in its sea of information.
█ LIMITATIONS
DISCLAIMER: While it may seem a bit paradoxical that this script aims to use past performance to potentially measure future results, past performance is not indicative of future results . Markets are highly adaptive and often unpredictable. This script is meant as an informational tool to show how patterns may behave. There is no guarantee that confidence intervals (or any other metric measured with this script) are accurate to the performance of patterns; caution must be exercised with all patterns identified regardless of how much information regarding prior performance is available.
Candlestick Theory - In the name, Candlestick Theory is a theory , and all theories come with their own limits. Some patterns identified by this script may be completely useless/unprofitable/unpredictable regardless of whatever combination of settings are used to identify them. However, if I truly believed this theory had no merit, this script would not exist. It is important to understand that this is a tool meant to be utilized with an array of others to procure positive (or negative, looking at you, short sellers ) results when navigating the complex world of finance.
To address the functionality note however, this script has an offset of 1 by default. Patterns will not be identified on the currently closing candle, only on the candle which has most recently closed. Attempting to have this script do both (offset by one or identify on close) lead to more trouble than it was worth. I personally just want users to be aware that patterns will not be identified immediately when they appear.
Trend Direction - Moving Averages - There is a small quirk with how MA settings will be adjusted if the user inputs two moving averages of the same length when the "MA Setting" is set to 'BOTH'. If Moving Averages have the same length, this script will default to only using MA 1 regardless of if the types of Moving Averages are different . I will experiment in the future to alleviate/reduce this restriction.
Price Analysis - BREAKOUT mode - With how identifying patterns with a look-ahead confirmation works, the percent returns for patterns that break out in either direction will be calculated on the same candle regardless of if P/L Offset is set to 'FROM CONFIRMATION' or 'FROM APPEARANCE'. This same issue is present in the Hikkake Hunter script mentioned earlier. This does not mean the P/L calculations are incorrect , the offset for the calculation is set by the number of candles required to confirm the pattern if 'FROM APPEARANCE' is selected. It just means that these two different P/L calculations will complete at the same time independent of the setting that's been selected.
Adaptive Coloring/Hard Limiting - Hard Limiting is only used with Adaptive Coloring and has no effect outside of it. If Hard Limiting is used, it is recommended to increase the 'Positive' and 'Negative' return tolerance values as a pattern's bullish/bearishness may be disproportionately represented with the gradient generated under a hard limit.
TARGET MODE - This mode will break rules regarding patterns that are overridden on purpose. If a pattern selected in TARGET mode would have otherwise been absorbed by a larger pattern, it will have that pattern's percent return calculated; potentially leading to duplicate returns being included in the matrix of all returns recognized by this script.
'Tall' Candle Setting - This is a wide-reaching setting, as approximately 30 different patterns or so rely on defining 'Tall' candles. Changing how 'Tall' candles are defined whether by the tolerance value those candles need to exceed or by the values of the candle used for the baseline comparison (RANGE/BODY) can wildly affect how this script functions under certain conditions. Refer to the tooltip of these settings for more information on which specific patterns are affected by this.
Doji Settings - There are roughly 10 or so two to three candle patterns which have Dojis as a part of them. If all Dojis are disabled, it will prevent some of these larger patterns from being recognized. This is a dependency issue that I may address in the future.
'Engulfing' Setting - Functionally, the two 'Engulfing' settings are quite different. Because of this, the 'RANGE' setting may cause certain patterns that would otherwise be valid under textbook and online references/definitions to not be recognized as such (like the Upside Gap Two Crows or Three Outside down).
█ PATTERN LIST
This script recognizes 85 patterns upon initial release. I am open to adding additional patterns to it in the future and any comments/suggestions are appreciated. It recognizes:
15 — 1 Candle Patterns
4 Hammer type patterns: Regular Hammer, Takuri Line, Shooting Star, and Hanging Man
9 Doji Candles: Regular Dojis, Northern/Southern Dojis, Gravestone/Dragonfly Dojis, Gapping Up/Down Dojis, and Long-Legged/Rickshaw Man Dojis
White/Black Long Days
32 — 2 Candle Patterns
4 Engulfing type patterns: Bullish/Bearish Engulfing and Last Engulfing Top/Bottom
Dark Cloud Cover
Bullish/Bearish Doji Star patterns
Hammer Inverted
Bullish/Bearish Haramis + Cross variants
Homing Pigeon
Bullish/Bearish Kicking
4 Lines type patterns: Bullish/Bearish Meeting/Separating Lines
Matching Low
On/In Neck patterns
Piercing pattern
Shooting Star (2 Lines)
Above/Below Stomach patterns
Thrusting
Tweezers Top/Bottom patterns
Two Black Gapping
Rising/Falling Window patterns
29 — 3 Candle Patterns
Bullish/Bearish Abandoned Baby patterns
Advance Block
Collapsing Doji Star
Deliberation
Upside/Downside Gap Three Methods patterns
Three Inside/Outside Up/Down patterns (4 total)
Bullish/Bearish Side-by-Side patterns
Morning/Evening Star patterns + Doji variants
Stick Sandwich
Downside/Upside Tasuki Gap patterns
Three Black Crows + Identical variation
Three White Soldiers
Three Stars in the South
Bullish/Bearish Tri-Star patterns
Two Crows + Upside Gap variant
Unique Three River Bottom
3 — 4 Candle Patterns
Concealing Baby Swallow
Bullish/Bearish Three Line Strike patterns
6 — 5 Candle Patterns
Bullish/Bearish Breakaway patterns
Ladder Bottom
Mat Hold
Rising/Falling Three Methods patterns
█ WORKS CITED
Because of the amount of time needed to complete this script, I am unable to provide exact dates for when some of these references were used. I will also not provide every single reference, as citing a reference for each individual pattern and the place it was reviewed would lead to a bibliography larger than this script and its description combined. There were five major resources I used when building this script, one book, two websites (for various different reasons including patterns, moving averages, and various other articles of information), various scripts from TradingView's public library (including TradingView's own source code for *all* candle patterns ), and PineScrypt's reference manual.
Bulkowski, Thomas N. Encyclopedia of Candlestick Patterns . Hoboken, New Jersey: John Wiley & Sons Inc., 2008. E-book (google books).
Various. Numerous webpages. CandleScanner . 2023. online. Accessed 2020 - 2023.
Various. Numerous webpages. Investopedia . 2023. online. Accessed 2020 - 2023.
█ AKNOWLEDGEMENTS
I want to take the time here to thank all of my friends and family, both online and in real life, for the support they've given me over the last few years in this endeavor. My pets who tried their hardest to keep me from completing it. And work for the grit to continue pushing through until this script's completion.
This belongs to me just as much as it does anyone else. Whether you are an institutional trader, gold bug hedging against the dollar, retail ape who got in on a squeeze, or just parents trying to grow their retirement/save for the kids. This belongs to everyone.
Private Beta for new features to be tested can be found here .
Vires In Numeris
Adaptive Fusion ADX VortexIntroduction
The Adaptive Fusion ADX DI Vortex Indicator is a powerful tool designed to help traders identify trend strength and potential trend reversals in the market. This indicator uses a combination of technical analysis (TA) and mathematical concepts to provide accurate and reliable signals.
Features
The Adaptive Fusion ADX DI Vortex Indicator has several features that make it a powerful tool for traders. The Fusion Mode combines the Vortex Indicator and the ADX DI indicator to provide a more accurate picture of the market. The Hurst Exponent Filter helps to filter out choppy markets (inspired by balipour). Additionally, the indicator can be customized with various inputs and settings to suit individual trading strategies.
Signals
The enterLong signal is generated when the algorithm detects that it's a good time to buy a stock or other asset. This signal is based on certain conditions such as the values of technical indicators like ADX, Vortex, and Fusion. For example, if the ADX value is above a certain threshold and there is a crossover between the plus and minus lines of the ADX indicator, then the algorithm will generate an enterLong signal.
Similarly, the enterShort signal is generated when the algorithm detects that it's a good time to sell a stock or other asset. This signal is also based on certain conditions such as the values of technical indicators like ADX, Vortex, and Fusion. For example, if the ADX value is above a certain threshold and there is a crossunder between the plus and minus lines of the ADX indicator, then the algorithm will generate an enterShort signal.
The exitLong and exitShort signals are generated when the algorithm detects that it's a good time to close a long or short position, respectively. These signals are also based on certain conditions such as the values of technical indicators like ADX, Vortex, and Fusion. For example, if the ADX value crosses above a certain threshold or there is a crossover between the minus and plus lines of the ADX indicator, then the algorithm will generate an exitLong signal.
Usage
Traders can use this indicator in a variety of ways, depending on their trading strategy and style. Short-term traders may use it to identify short-term trends and potential trade opportunities, while long-term traders may use it to identify long-term trends and potential investment opportunities. The indicator can also be used to confirm other technical indicators or trading signals. Personally, I prefer to use it for short-term trades.
Strengths
One of the strengths of the Adaptive Fusion ADX DI Vortex Indicator is its accuracy and reliability. The indicator uses a combination of TA and mathematical concepts to provide accurate and reliable signals, helping traders make informed trading decisions. It is also versatile and can be used in a variety of trading strategies.
Weaknesses
While this indicator has many strengths, it also has some weaknesses. One of the weaknesses is that it can generate false signals in choppy or sideways markets. Additionally, the indicator may lag behind the market, making it less effective in fast-moving markets. That's a reason why I included the Hurst Exponent Filter and special smoothing.
Concepts
The Adaptive ADX DI Vortex Indicator with Fusion Mode and Hurst Filter is based on several key concepts. The Average Directional Index (ADX) is used to measure trend strength, while the Vortex Indicator is used to identify trend reversals. The Hurst Exponent is used to filter out noise and provide a more accurate picture of the market.
In conclusion, the Adaptive Fusion ADX DI Vortex Indicator is a versatile and powerful tool for traders. By combining technical analysis and mathematical concepts, this indicator provides accurate and reliable signals for identifying trend strength and potential trend reversals. While it has some weaknesses, its many strengths and features make it a valuable addition to any trader's toolbox.
---
Credits to:
▪️@cheatcountry – Hann Window Smoohing
▪️@loxx – VHF and T3
▪️@balipour – Hurst Exponent Filter
ATR-Stepped, Another New Adaptive Moving Average [Loxx]ATR-Filtered, Another New Adaptive Moving Average is a modification of @cheatcountry's "Another New Adaptive Moving Average " shown below
I've added AT- stepped filtering. This is a standard ATR filter that works by requiring movement by XX multiple of ATR before registering a trend flip. I've also included Loxx's Expanded Source Types. You can read about those here:
From @cheatcountry on A New Adaptive Moving Average
The New Adaptive Moving Average was created by Scott Cong (Stocks and Commodities Mar 2023) and this is a companion indicator to my previous script
This indicator still works off of the same concept as before with effort vs results but this indicator takes a slightly different approach and instead defines results as the absolute difference between the closing price and a closing price x bars ago. As you can see in my chart example, this indicator works great to stay with the current trend and provides either a stop loss or take profit target depending on which direction you are going in. As always, I use darker colors to show stronger signals and lighter colors to show normal signals. Buy when the line turns green and sell when it turns red.
Included
Alerts
Signals
Loxx's Expanded Source Types
PA-Adaptive T3 Loxxer [Loxx]PA-Adaptive T3 Loxxer is a Loxxer indicator that is Phase Accumulation Cycle adaptive and uses T3 moving average for smoothing instead of the typical SMA or EMA . this allows for smoother signals by reducing noise.
What is Loxxer?
The Loxxer indicator is a technical analysis tool that compares the most recent maximum and minimum prices to the previous period's equivalent price to measure the demand of the underlying asset.
What is the Phase Accumulation Cycle?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Divergences

Another New Adaptive Moving Average [CC]The New Adaptive Moving Average was created by Scott Cong (Stocks and Commodities Mar 2023) and this is a companion indicator to my previous script . This indicator still works off of the same concept as before with effort vs results but this indicator takes a slightly different approach and instead defines results as the absolute difference between the closing price and a closing price x bars ago. As you can see in my chart example, this indicator works great to stay with the current trend and provides either a stop loss or take profit target depending on which direction you are going in. As always, I use darker colors to show stronger signals and lighter colors to show normal signals. Buy when the line turns green and sell when it turns red.
Let me know if there are any other indicator scripts you would like to see me publish!

A New Adaptive Moving Average [CC]The New Adaptive Moving Average was created by Scott Cong (Stocks and Commodities Mar 2023) and his idea was to focus on the Adaptive Moving Average created by Perry Kaufman and to try to improve it by introducing a concept of effort vs results. In this case the effort would be the total range of the underlying price action since each bar is essentially a war of the bulls vs the bears. The result would be the total range of the close so we are looking for the highest close and lowest close in that same time period. This gives us an alpha that we can use to plug into the Kaufman Adaptive Moving Average algorithm which gives us a brand new indicator that can hug the price just enough to allow us to ride the stock up or down. I have color coded it to be darker colors when it is a strong signal and lighter colors when it is a normal signal. Buy when the line turns green and sell when it turns red.
Let me know if there are any other indicators you would like to see me publish!